This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Discover how to create an effective and engaging training program for your developers. Create a security training program with clearly defined goals to influence your developers to prioritize learning. Create a security training program with clearly defined goals to influence your developers to prioritize learning.
And we know as well as anyone: the need for fast transformations drives amazing flexibility and innovation, which is why we took Perform Hands-on Training (HOT) virtual for 2021. Taking training sessions online this year lets us provide more instructor-led sessions over more days and times than ever before. So where do you start?
This blog will demonstrate how to set up and benchmark the end-to-end performance of the training process. The typical process of using Alluxio to accelerate machine learning and deep learning training includes the following three steps: Architecture.
Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources. Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs.
With the exponential growth of data, we create and optimize infrastructure that enables large-scale model training and overcomes the performance bottleneck while reducing the cost of data storage and computation. The group owns the world’s largest mobile payment platform Alipay, which serves over 1.3 billion users and 80 million merchants.
Scaling experiments with Metaboost bindingsbacked by MetaflowConfig Consider a Metaboost ML project named `demo` that creates and loads data to custom tables (ETL managed by Maestro), and then trains a simple model on this data (ML Pipeline managed by Metaflow). 50/train/251640854] Task is starting. [50/train/251640854]
The process should include training technical and business users to maximize the value of the platform so they can access, ingest, analyze, and act on the new observability approach. The right unified solution , training, and reinforcement from leadership will make teams less inclined to adopt single-use tools and fall back into tool sprawl.
In the field of machine learning and artificial intelligence, inference is the phase where a trained model is applied to real world data to generate predictions or decisions. Inference Time Compute Inference time compute refers to the amount of computational power required to make such predictions using a trained model.
For more background on safety and security issues related to C++, including definitions of language safety and software security and similar terms, see my March 2024 essay C++ safety, in context. This essay picks up our story where that one left off to bring us up to date with a specific focus on undefined behavior (aka UB).
On April 22, 2022, I received an out-of-the-blue text from Sam Altman inquiring about the possibility of training GPT-4 on OReilly books. And now, of course, given reports that Meta has trained Llama on LibGen, the Russian database of pirated books, one has to wonder whether OpenAI has done the same. We chose one called DE-COP.
Like OpenAIs GPT-4 o1, 1 its training has emphasized reasoning rather than just reproducing language. GPT-4 o1 was the first model to claim that it had been trained specifically for reasoning. There are more than a few math textbooks online, and its fair to assume that all of them are in the training data.
Your trained eye can interpret them at a glance, a skill that sets you apart. Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. However, your responsibilities might change or expand, and you need to work with unfamiliar data sets.
The way we train juniors, whether it’s at university or in a boot camp or whether they train themselves from the materials we make available to them (Long Live the Internet), we imply from the very beginning that there’s a correct answer. The answer to “what’s the solution” is “it depends.”
We are living in an age where data is of utmost importance, be it analysis or reporting, training data for LLM models, etc. The amount of data we capture in any field is increasing exponentially, which requires a technology that can process large amounts of data in a short duration. One such technology would be Apache Spark.
Role -based training requires privacy training alongside security training. FedRAMP increased emphasis on privacy, which takes center stage in Rev.5, 5, including: Configuration Change Control and CM-4 – Impact Analysis now requires privacy impact analysis for configuration changes. FedRAMP Rev.5
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., at Facebook—both from 2020.
And an O’Reilly Media survey indicated that two-thirds of survey respondents have already adopted generative AI —a form of AI that uses training data to create text, images, code, or other types of content that reflect its users’ natural language queries. AI requires more compute and storage. AI performs frequent data transfers.
Training & Certification Award, NORAM. Achieving and retaining certifications is an important aspect of partnering with Dynatrace, and our winner of the NORAM Training & Certification Award – Arctiq – has demonstrated continued success in this department. Training & Certification Award, LATAM. RFO of the Year.
In order to train the model on internal training data (video clips with aligned text descriptions), we implemented a scalable version on Ray Train and switched to a more performant video decoding library. These models are trained on large amounts of image-caption pairs via in-batch contrastive learning.
Training & Certification Award DXC has stood out this year, with 50 individuals becoming Dynatrace Certified across Associate and Professional levels, and this award is a testament to that continued investment in training and enablement with Dynatrace.
Snowflake Cortex AL/ML suite helps you train the models to spot and correct these outliers in order to help improve the quality of your results. Anomaly detection is the process of identifying the data deviation from the expected results in a time-series data.
This year, we’ve increased the number of awards to partner individuals to recognize the personal achievements around training, certification, and community participation, along with recognition for partner organizations. EMEA Training and Certification Award. RFO Training and Certification Award. Partner awards. Julius Loman.
Training and Certification Award “Our APAC partners have excelled in delivering cutting-edge solutions that address the unique demands of the region. Their forward-thinking approach and unwavering commitment to quality and development have been key to our shared success. ” – Alex Lim, senior director APAC partners, Dynatrace.
Furthermore, AI can significantly boost productivity if employees are properly trained on how to use the technology correctly. “It’s But if you don’t take the time to train the workforce in the programs or the systems you’re bringing online, you lose that effectiveness.
In evaluating our model’s accuracy in understanding performance/errors and behavior, we use historical real user data and a standard 80-20 train-test split to train our model. It looks at these metrics across key pages to pinpoint where your users are most impacted and which metric directly impacts each page.
Given the temporal dependency of the data, traditional validation techniques such as K-fold cross-validation cannot be applied, thereby necessitating unique methodologies for model training and validation.
It can be difficult to understand the basis of AI systems’ decisions, particularly when they are trained on large and complex data sets. AI systems, and their data, can be biased, either intentionally or unintentionally, reflecting the biases of their creators or the data on which they are trained. AI system bias. Data in context.
At Dynatrace, our Autonomous Cloud Enablement (ACE) team are the coaches or teach and train our customers to always get the best out of Dynatrace and reach their objectives. Our expert Jean Louis Lormeau suggested a training program to help you become the champion in problem resolution. We can now move to the training phase.
Training Performance Media model training poses multiple system challenges in storage, network, and GPUs. We have developed a large-scale GPU training cluster based on Ray , which supports multi-GPU / multi-node distributed training. We accomplish this by paving the path to: Accessing and processing media data (e.g.
Despite having to reboot Perform 2022 from onsite in Vegas to virtual, due to changing circumstances, we’re still set to offer just the same high-quality training. And, what’s more – Dynatrace offers virtual training year-round in Dynatrace University, our product education platform.
Augmenting LLM input in this way reduces apparent knowledge gaps in the training data and limits AI hallucinations. The LLM then synthesizes the retrieved data with the augmented prompt and its internal training data to create a response that can be sent back to the user. million AI server units annually by 2027, consuming 75.4+
Practical use cases for speech & music activity Audio dataset preparation Speech & music activity is an important preprocessing step to prepare corpora for training. Content, genre and languages Instead of augmenting or synthesizing training data, we sample the large scale data available in the Netflix catalog with noisy labels.
In semi-supervised anomaly detection models, only a set of benign examples are required for training. Data Data Labeling For the task of anomaly detection in streaming platforms, as we have neither an already trained model nor any labeled data samples, we use structural a priori domain-specific rule-based assumptions, for data labeling.
This streamlines the process of building AI-powered APIs by reducing the need for manual intervention in model training and deployment. Key Trends and Advancements AutoML for APIs AutoML (Automated Machine Learning) tools are increasingly being used to automate the development of machine learning models that can be exposed through APIs.
It’s a shorter version of a ScyllaDB University (self-paced free training) lab. The following tutorial walks you through how to use Spring Boot apps with ScyllaDB for time series data, taking advantage of shard-aware drivers and prepared statements.
Training: We created easy-to-provide feedback using and with a fully integrated fine-tuning loop to allow end-users to teach new domains and questions around it effectively. For example, LORE provides human-readable reasoning on how it arrived at the answer that users can cross-verify.
One effective capacity-management strategy is to switch from a reactive approach to an anticipative approach: all necessary capacity resources are measured, and those measurements are used to train a prediction model that forecasts future demand. You can use any DQL query that yields a time series to train a prediction model.
During training, our goal is to generate the best downsampled representation such that, after upscaling, the mean squared error is minimized. We focus on a robust downscaler that is trained given a conventional upscaler, like bicubic. We focus on a robust downscaler that is trained given a conventional upscaler, like bicubic.
Employee training in cybersecurity best practices and maintaining up-to-date software and systems are also crucial. Comprehensive training programs and strict change management protocols can help reduce human errors. Possible scenarios An IT technician accidentally deletes a critical database, causing a service outage.
While this approach can be effective if the model is trained with a large amount of data, even in the best-case scenarios, it amounts to an informed guess, rather than a certainty. Because IT systems change often, AI models trained only on historical data struggle to diagnose novel events. That’s where causal AI can help.
To address the first challenge, we use pre trained sentence-level embeddings, e.g. from an embedding model optimized for paraphrase identification , to represent text in both sources. In order to leverage this noisily aligned data source, we need to align time-stamped text (e.g.
By carving the right AWS certification path, developers can even use their certification and training to advance their careers long term. What is the value of AWS training and certification? You and your peers – if you team up – can benefit on multiple levels from AWS training and certification.
With real-time causal AI, organizations can identify the root cause of issues without having to train their data models up front. That’s critical to circumvent the time-consuming process of training algorithms to understand system behavior. Traditional machine learning approaches involve time-consuming training of algorithms.
In addition to Spark, we want to support last-mile data processing in Python, addressing use cases such as feature transformations, batch inference, and training. There are several ways to provide explainability to models but one way is to train an explainer model based on each trained model.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















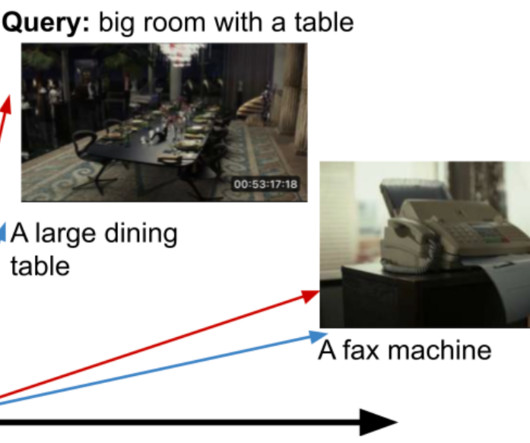





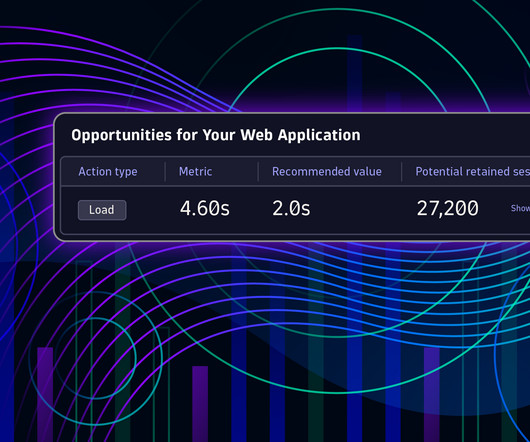






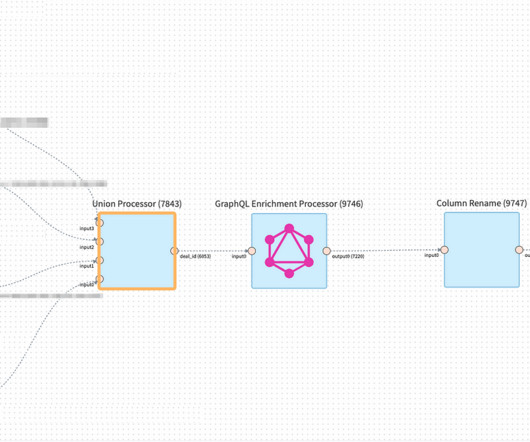








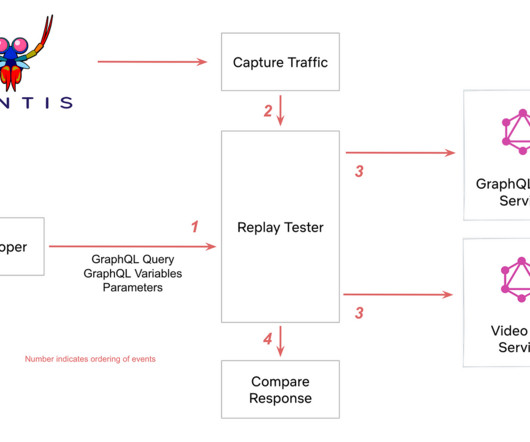









Let's personalize your content