This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. Chaos engineering is a practice that extends beyond traditional failure testing by identifying unpredictable issues.
Modern distributed systems, like microservices and cloud-native architectures, are built to be scalable and reliable. Chaos engineering is a useful way to test and improve system resilience by intentionally creating controlled failures. However, their complexity can lead to unexpected failures.
Several years back, virtualization became a buzzword in the industry that flourished, evolved, and became famously known as Cloud computing. To verify the quality of everything that is rendered on the cloud environment, Cloud testing was performed running manual or automation testing or both.
Virtualization has become a crucial element for companies and individuals looking to optimize their computing resources in today’s rapidly changing technological landscape. Mini PCs have become effective virtualization tools in this setting, providing a portable yet effective solution for a variety of applications.
Following up my post Are Times still Good for Load Testing? , First of all, integrating into agile development (shift-left / continuous performance testing) and integrating into performance information loop with production (shift-right) to form a holistic performance view. I decided to answer multiple comments here separately.
DevOps platform engineers are responsible for cloud platform availability and performance, as well as the efficiency of virtual bandwidth, routers, switches, virtual private networks, firewalls, and network management. Version control system and source code management with end-to-end DevOps platform and cloud-hosted Git services.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. CPU calculations apply these assumptions: A virtual CPU (vCPU) on any cloud host equals one thread of a physical CPU core, with two threads per core.
The Relationship Between Automated Testing and RPA. Automated testing is a process of transforming a human-driven testsystem into machine execution. RPA is developed from automated testing, similar to automated testing, and there is a lot of overlap between the two. and have similar technical architectures.
One way to apply improvements is transforming the way application performance engineering and testing is done. This involves new software delivery models, adapting to complex software architectures, and embracing automation for analysis and testing. Check out Dynatrace’s Load testing tool integration. Get started today! .
Global corporations with offices in multiple countries need to ensure that their internal systems are accessible to all employees, regardless of their location. A prominent solution is virtual machines, however, this is inadequate for customers who deploy their systems with Kubernetes. CAGR in the forecasted period ending 2030.
As Kubernetes adoption increases and it continues to advance technologically, Kubernetes has emerged as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Accordingly, the remaining 27% of clusters are self-managed by the customer on cloud virtual machines.
Hardware virtualization for cloud computing has come a long way, improving performance using technologies such as VT-x, SR-IOV, VT-d, NVMe, and APICv. It's an exciting development in cloud computing: hardware virtualization is now fast. Virtualized in Hardware**: Hardware support for virtualization, and near bare-metal speeds.
Available directly from the AWS Marketplace , Dynatrace provides full-stack observability and AI to help IT teams optimize the resiliency of their cloud applications from the user experience down to the underlying operating system, infrastructure, and services. Auto-detection starts monitoring new virtual machines as they are deployed.
Are we virtual yet? Once the container is running, you can give Claude a problem to solve; it will figure out how to solve that problem, and use the container’s virtual Linux computer to do the work. An automated framework for testing web applications, Selenium++? Email is my CRM system; I’ve never used a commercial CRM product.
Small enough to fit in the pages of a thin virtual book. The reason is in How Complex Systems Fail. Predicting what emerges at each layer is impossible, so it's futile to generate a 10,247-line algorithm by testing fidelity to a remembered baseline. How Complex Systems Fail : They don't. Ford had his game.
Performance Test Execution and Monitoring. In this article, we are highlighting a few points on what can be avoided for better performance when we test and monitor a load test. In this phase, virtual user scripts are run based on the number of concurrent users and workload specified in the non-functional test plan.
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. It aims to provide a reliable platform for users to participate in live or pre-recorded workout sessions, virtual training, or fitness tutorials without interruptions. Five example SLOs for faster, more reliable apps 1.
Development and QA process Assessing a vendor’s testing and quality assurance (QA) capabilities reveals their approach and commitment to validating changes and preventing new issues. Vendors take different testing and QA approaches, ranging from simple crash testing to newer strategies such as canary and blue-green.
Vulnerability assessment is the process of identifying, quantifying, and prioritizing the cybersecurity vulnerabilities in a given IT system. The goal of an assessment is to locate weaknesses that can be exploited to compromise systems. Changing system configurations. Identify vulnerabilities. Analyze findings. Assess risk.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
IT admins can automate virtually any time-consuming task that requires regular application. Testing automation can be painstaking. It’s also crucial to test frequently when automating IT operations so that you don’t automatically replicate mistakes. What is IT automation? Digital process automation tools.
Citrix is critical infrastructure For businesses operating in industries with strict regulations, such as healthcare, banking, or government, Citrix virtual apps and virtual desktops are essential for simplified infrastructure management, secure application delivery, and compliance requirements.
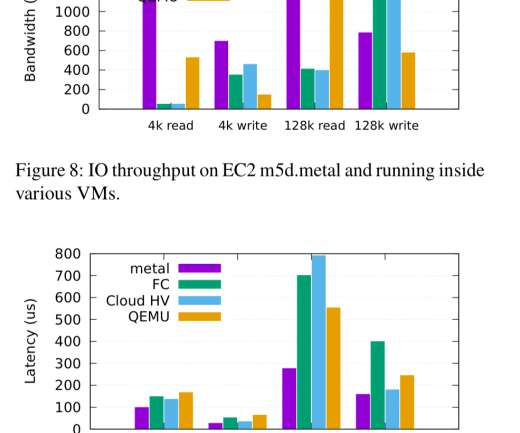
Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018. The traditional view is that there is a choice between virtualization with strong security and high overhead, and container technologies with weaker security and minimal overhead. The last word.
Process Improvements (50%) The allocation for process improvements is devoted to automation and continuous improvement SREs help to ensure that systems are scalable, reliable, and efficient. A few avenues for elevating CI/CD pipelines are: Enhancing the extent of automated test coverage during the testing phase.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
It’s easy to see why, with benefits such as better testing, easier deployment, faster performance, and more. Monolithic software systems employ one large codebase, which includes collections of tools, software development kits, and associated development dependencies. Dynatrace news. The resulting product is large, uniform, and rigid.
Unfortunately, container security is much more difficult to achieve than security for more traditional compute platforms, such as virtual machines or bare metal hosts. However, to be secure, containers must be properly isolated from each other and from the host system itself. Source code tests. Let’s look at each type.
We arm our creators with rich insights derived from our personalization system, helping them better understand our members and gain knowledge to produce content that maximizes their joy. These timecode tags enable efficient discovery, freeing our creators from hours of categorizing footage so they can focus on creative decisions instead.
Getting precise root cause analysis when dealing with several layers of virtualization in a containerized world. To optimize your back-end systems, you can use the service flow view within Dynatrace to identify layers of application architecture. Analyzing user experience to ensure uniform performance after migration.
These containers are software packages that include all the relevant dependencies needed to run software on any system. Instead, enterprises manage individual containers on virtual machines (VMs). Container-based software isn’t tied to a platform or operating system, so IT teams can move or reconfigure processes easily.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
Cloud providers then manage physical hardware, virtual machines, and web server software management. This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Increased testing complexity. These include the following: Reduced control.
In order to test whether a model has been trained on a given book, we provided the model with a paragraph quoted from the human written book along with three permutations of the same paragraph, and then asked the model to identify the verbatim (i.e., We also tested at the paragraph level. We chose one called DE-COP.
Operations teams want to make sure the system doesn’t break. SREs can then use SLOs for release quality checks, such as big bang, blue/green , and canary testing. Teams can plug in new tools for testing, deployment, or even monitoring without having to modify a lot of existing automation tools. Upgrades are automatic.
A vast majority of the features are the same, outside of these advanced features available through the BYOC model: Virtual Private Clouds / Virtual Networks. Amazon Virtual Private Clouds (VPC) and Azure Virtual Networks (VNET) are private, isolated sections of the cloud infrastructure where you can launch resources.
A message queue is a form of middleware used in software development to enable communications between services, programs, and dissimilar components, such as operating systems and communication protocols. A message queue enables the smooth flow of information to make complex systems work. Message queue software options to consider.
A message queue is a form of middleware used in software development to enable communications between services, programs, and dissimilar components, such as operating systems and communication protocols. A message queue enables the smooth flow of information to make complex systems work. Message queue software options to consider.
I am looking forward to share my thoughts on ‘Reinventing Performance Testing’ at the imPACt performance and capacity conference by CMG held on November 7-10, 2016 in La Jolla, CA. Cloud seriously impacts system architectures that has a lot of performance-related consequences. First, we have a shift to centrally managed systems.
But, manual steps — such as reviewing test results and addressing production issues resulting from performance, resiliency, security, or functional issues — often hinder these efforts. Observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces.
Application security tests and what they do. Once an application passed all the functional tests, and before it moved into production, it was put through a gauntlet of security tests. IAST only works with languages that have a virtual runtime environment, such as Java, C#, Python, and Node.js. We need a better approach.
Virtualization has revolutionized system administration by making it possible for software to manage systems, storage, and networks. This can reduce labor costs and enhance reliability by enabling systems to self-heal. By removing physical dependencies, automation can help perform SRE at scale.
Many hospitals adopted telehealth and other virtual technology to deliver care and reduce the spread of disease. As patient care continues to evolve, IT teams have accelerated this shift from legacy, on-premises systems to cloud technology to more build, test, and deploy software, and fuel healthcare innovation.
One main advantage of using a product in SaaS mode is the automatic scaling of resources based on system load. Compression of data that’s older than three days utilizes one virtual CPU. In on-premises environments, resource scaling is not always easy and requires time and thorough planning by the administrator.
Although Kubernetes simplifies application development while increasing resource utilization, it is a complex system that presents its own challenges. Containers and microservices: A revolution in the architecture of distributed systems. At its start in 2013, Docker was mainly used by developers as a sandbox for testing purposes.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content