This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What’s the problem with Black Friday traffic? But that’s difficult when Black Friday traffic brings overwhelming and unpredictable peak loads to retailer websites and exposes the weakest points in a company’s infrastructure, threatening application performance and user experience. Why Black Friday traffic threatens customer experience.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
The three strategies we will discuss today are AB Testing , Replay Testing, and Sticky Canaries. To launch Phase 1 safely, we used AB Testing. To launch Phase 2 safely, we used Replay Testing and Sticky Canaries. We knew we could test the same query with the same inputs and consistently expect the same results.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
Synthetic testing simulates real-user behaviors within an application or service to pinpoint potential problems. Here’s a look at why this testing matters, how it works, and what companies need to get the most from this approach. What is synthetic testing? RUM, meanwhile, requires actual users.
It’s also critical to have a strategy in place to address these outages, including both documented remediation processes and an observability platform to help you proactively identify and resolve issues to minimize customer and business impact. This can result from improperly configured backups, corrupted data, or insufficient testing.
While most government agencies and commercial enterprises have digital services in place, the current volume of usage — including traffic to critical employment, health and retail/eCommerce services — has reached levels that many organizations have never seen before or tested against. There are proven strategies for handling this.
This step is crucial as this environment is used for the final validation and testing phase before the code is released into production. This can lead to a lack of insight into how the code will behave when exposed to heavy traffic. Furthermore, augmenting test coverage to mirror the scenarios encountered in production is imperative.
A cloud migration strategy, however, provides technical optimization that’s also firmly rooted in the business value chain. With cloud-based resources, teams can spin up infrastructure in seconds, begin testing immediately, scale up or down as needed, and easily eliminate resources that are no longer needed. Read eBook now!
I’ve been speaking to customers over the last few months about our new cloud architecture for Synthetic testing locations and their confusion is clear. And the last thing you want to do with synthetic is introduce false positives (the bane of all synthetic testing) into the system, and yet this was happening too often.
These development and testing practices ensure the performance of critical applications and resources to deliver loyalty-building user experiences. RUM, however, has some limitations, including the following: RUM requires traffic to be useful. For example, in e-commerce, you can validate and test checking out a shopping cart.
To ensure the safety of their customers, employees, and business data, organizations must have a strategy to protect against zero-day vulnerabilities. Typically, organizations might experience abnormal scanning activity or an unexpected traffic influx that is coming from one specific client. What is a zero-day vulnerability?
When the SLO status converges to an optimal value of 100%, and there’s substantial traffic (calls/min), BurnRate becomes more relevant for anomaly detection. Error budget burn rate = Error Rate / (1 – Target) Best practices in SLO configuration To detect if an entity is a good candidate for strong SLO, test your SLO.
If any problems made it past the testing or production environments, the team faced citizens potentially calling the governor’s office and newspapers to complain. Government IT finds higher work satisfaction in legacy modernization While these strategies benefit citizens, Zbojniewicz and Smith also improved IT staff satisfaction.
Streamline development and delivery processes Nowadays, digital transformation strategies are executed by almost every organization across all industries. Whether triggered by a test result or a new release deployment, detected events work as a trigger to check the defined objectives and derive an overall status automatically.
264/AVC Main profile family still represents a substantial portion of the members viewing hours and an even larger portion of the traffic. These figures were estimated on 200 full-length titles from our catalog and have been validated through extensive A/B testing. Yet, given its wide support, our H.264/AVC
Over the course of this post, we will talk about our approach to this migration, the strategies that we employed, and the tools we built to support this. For the migration, testing was a first-class citizen. Replay Testing Enter replay testing.
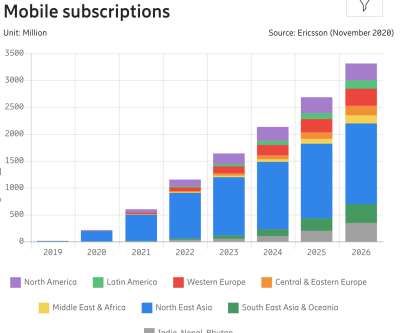
The State Of Mobile And Why Mobile Web Testing Matters. The State Of Mobile And Why Mobile Web Testing Matters. These days, with mobile traffic accounting for over 50% of web traffic , it’s fair to assume that the very first encounter of your prospect customers with your brand will happen on a mobile device.
One of the several deployment strategies is the blue/green deployment approach: In this method, two identical production environments work in parallel. One is the currently-running production environment receiving all user traffic (let’s say the “blue” one), the other is a clone of it (“green”), but idle.
We took a hybrid head-based sampling approach that allows for recording 100% of traces for a specific and configurable set of requests, while continuing to randomly sample traffic per the policy set at ingestion point. This implies that the cost of storing traces grows linearly to the amount of data being stored. What’s next?
In this post, we compare ScaleGrid’s Bring Your Own Cloud (BYOC) plan vs. the standard Dedicated Hosting model to help you determine the best strategy for your MySQL, PostgreSQL, Redis™ and MongoDB® database deployment. This can result in significant cost savings for high traffic applications. Expert Tip. Security Groups.
Finally, just 50% are confident their applications have been tested for vulnerabilities before going into production. For example, an organization might use security analytics tools to monitor user behavior and network traffic. 75% say team silos and point solutions make it easier for vulnerabilities to slip through to production.
At Netflix, we have significant investments in ensuring new versions of our applications are well tested. However, Netflix is available for streaming on thousands of types of devices and it is powered by hundreds of micro-services which are deployed independently, making it extremely challenging to comprehensively test internally.
BT has modernized with AIOps at the center of its digital transformation strategy. For BT, AIOps and digital transformation are at the center of the company’s upcoming three-to-five-year digital transformation strategy. No matter how much you test, you always get challenges. BT has 30 million consumer customers, 1.2
With traffic growth, a single leader node handling all request volume started becoming overloaded. Implementation details We solved the cache synchronization problem (as stated above) with a combination of two strategies: Titus Gateway <-> Titus Job Coordinator synchronization protocol over the wire. queries/sec.
Automatic failover is a critical strategy to achieve this. In our three-part series of posts on HA for PostgreSQL, we’ll share an overview, the prerequisites, and the working and test results for each tool. All of these tests were run while the application was running and inserting data to the PostgreSQL database.
The crisis has emphasized the importance of having a strategy for maintaining stability and performance. By simulating user interactions and running tests from various locations worldwide, synthetic monitoring provides a comprehensive view of application performance and availability.
In this post, we’ll walk you through the best way to host MongoDB on DigitalOcean, including the best instance types to use, disk types, replication strategy, and managed service providers. MongoDB Replication Strategies. DigitalOcean Advantages for MongoDB. What’s most impressive is that you’re not compromising performance for cost.
A blue-green deployment model is a software delivery release strategy based on maintaining two separate application environments. As part of testing and validation of the new version of the software, application traffic is gradually re-routed to the green environment. Why Is Blue-Green Deployment Useful?
CFS is widely used and therefore well tested and Linux machines around the world run with reasonable performance. Implementation We decided to implement the strategy through Linux cgroups since they are fully supported by CFS, by modifying each container’s cpuset cgroup based on the desired mapping of containers to hyper-threads.
Revised cleanup strategy for Elasticsearch snapshots. To address this storage issue for older snapshots, we’ve adapted our cleanup strategy so that monthly snapshots are now removed automatically after 6 months. Synthetic tests in CMC endpoint configuration didn’t work when no port was set. Also in this release.
Research by the Enterprise Strategy Group in 2020 shows 60% of reported breached production applications in the past 12 months involved a known and unpatched vulnerability. For example, a test library is never deployed to production. According to Gartner , 80% of vulnerabilities are introduced via transitive dependencies.
That’s not all, the global mobile traffic is expected to increase sevenfold between 2017 and 2022. Mobile-first design should be accompanied with mobile website testing for delivering a flawless web experience to your target audience. Why should you focus on Mobile Website Testing? Mobile-first indexing. Speed and Accuracy.
Overall, adopting this practice promotes a structured and efficient storage strategy, fostering better performance, manageability, and, ultimately, a more robust database environment. Integrating DLVs into your database strategy will help you toward your efforts in achieving peak performance and reliability.
These include improving API traffic management and caching mechanisms to reduce server and network load, optimizing database queries, and adding additional compute resources, just to name some. While some of these are already done, such as adding additional compute, others require more development and testing.
This article will take an in-depth look at the various tools and strategies that help with mobile application testing. Why do you need to engage in testing a mobile application? However, testing has also grown in prominence and importance because without rigorous testing, companies cannot put useful apps onto the market.
No matter how much you test, a few bugs can still slip through the testing phase & reach production. If you missed testing something, it’s totally fine to admit the oversight and take corrective actions. Exhaustive testing is impossible with limited time, resources and budget. Don’t Panic. Or during code review?
At the limit, statically generated, edge delivered, and HTML-first pages look like the optimal strategy. From connecting back-office operations to front-of-the-house A/B testing and dynamic personalization for each customer, the shared foundation is fast server-side rendering powered by fast storefront data access.
An automated deployment system needs to carefully sequence a software update across a fleet while it is actively receiving traffic. This made it easy for developers to “push-button” deploy their application to a development host for debugging, to a staging environment for tests, and finally to production to release an update to customers.
implement a M-CDN, organizations can use traffic management tools or Multi-CDN switching solutions that distribute and route content across the various CDN providers. Network RedundancyThe primary and most important advantage of a Multi-CDN strategy is redundancy, and, consequently, improved reliability.
These strategies help maintain system performance, reduce read overhead, and meet SLOs by minimizing the impact of deletes. Although clock-based token generation can suffer from clock skew, our tests on EC2 Nitro instances show drift is minimal (under 1 millisecond). This technique maintains read pagination protections.
Most of the time is taken by quality or release engineers looking at test results, comparing them with previous builds or walking through a checklist of items that accumulated over the years in order to harden their release acceptance process. days and therefore contributing > 90% of the overall Commit Cycle Time! Pitometer is a Node.js
The POP is strategially located within the country and lowers latency overall. Traffic from this POP will be billed towards Latin America according to our pricing. Hola Mexico! We've launched our new point of presence (POP) in Mexico City. Requests from Mexico were previously routed to the US, which is no longer needed.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content