This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performance tuning needs. Thats where the OpenTelemetry Collector can help.
A shared vision At Dynatrace, weve built a comprehensive observability platform that already includes deep database visibility, the Top Database Statements view, and Grail for unified data storage and analysis. Stay tuned for updates, and as always, thank you for being part of the Dynatrace community.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
When dealing with IoT, one of the first things that come to mind is the limited processing, networking, and storage capabilities these devices operate with. A messaging protocol is a set of rules and formats that are agreed upon among entities that want to communicate with each other.
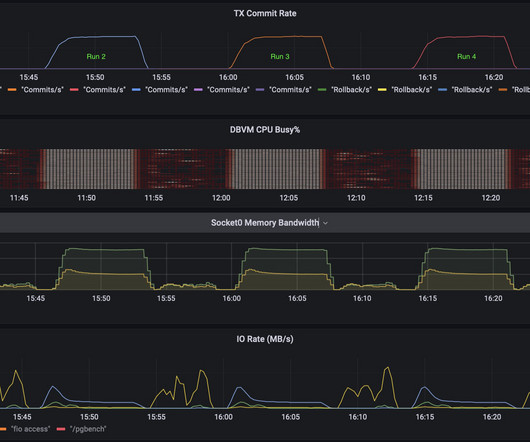
To do this I needed to drive postgres to do real transactions but have very little jitter/noise from the filesystem and storage. After reading a lot of blogs I came … The post Notes on tuning postgres for cpu and memory benchmarking appeared first on n0derunner.
The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table. Automating Performance Tuning with Autoscalers Tuning the performance of our Apache Flink jobs is currently a manual process.
An open-source distributed SQL query engine, Trino is widely used for data analytics on distributed data storage. In this article, we will show you how to tune Trino by helping you identify performance bottlenecks and provide tuning tips that you can practice. But how do we do that?
Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. Message Broker vs. Distributed Event Streaming Platform RabbitMQ functions as a message broker, managing message confirmation, routing, storage, and delivery within a queue. What is RabbitMQ?
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Let’s examine some of the drawbacks of this approach: Lack of Idempotency : There is no idempotency key baked into the storage data-model preventing users from safely retrying requests.
For the longest time, hosting static files on CDNs was the de facto standard for performance tuning website pages. The host offered browser caching advantages, better stability, and storage on fast edge servers across strategic geolocations. Not only did it have performance benefits, but it was also convenient for developers.
Masking at storage: Data is persistently masked upon ingestion into Dynatrace. Leverage three masking layers Masking at capture and masking at storage operations exclude targeted sensitive data points. To fine-tune your masking settings, select the entity you want to adjust and leverage the entity-specific settings.
Data storage and distribution through HollowFeeds Netflix Hollow is an Open Source java library and toolset for disseminating in-memory datasets from a single producer to many consumers for high performance read-only access.
Additionally, the time-sensitive nature of these investigations precludes the use of cold storage, which cannot meet the stringent SLAs required. Stay tuned for a closer look at the innovation behind thescenes! While reengineering these systems to accommodate this additional axis is possible, it would entail increased costs.
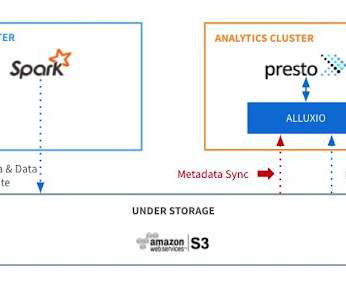
Metadata synchronization (sync) is a core feature in Alluxio that keeps files and directories consistent with their source of truth in under-storage systems, thus making it simple for users to reason the data retrieved from Alluxio. Meanwhile, understanding the internal process is important in order to tune the performance.
There are a wealth of options on how you can approach storage configuration in Percona Operator for PostgreSQL , and in this blog post, we review various storage strategies — from basics to more sophisticated use cases. For example, you can choose the public cloud storage type – gp3, io2, etc, or set file system.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
You quickly realize that it will take ages to fill up the overprovisioned database storage. Two days later, your database runs out of storage in the middle of the night. Therefore, you don’t know your current growth rate and can’t estimate the required storage for keeping the database up and running for the next month.
Flexible Storage : The service is designed to integrate with various storage backends, including Apache Cassandra and Elasticsearch , allowing Netflix to customize storage solutions based on specific use case requirements. Note : With Cassandra 4.x There is a lot more information that can be stored into the metadata column (e.g.,
You can use the Grail Storage Record Deletion API to trigger a deletion request. To delete the records, use the Storage Record Deletion API. Check our Privacy Rights documentation to stay tuned to our continuous improvements. With Notebooks, you can easily query data from Grail and visualize the results.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This technique facilitates validation on multiple fronts.
Managing storage and performance efficiently in your MySQL database is crucial, and general tablespaces offer flexibility in achieving this. In contrast to the single system tablespace that holds system tables by default, general tablespaces are user-defined storage containers for multiple InnoDB tables.
Before we dive into the technical implementation, let me explain the visual concept of this “Global Status Page”: Another requirement for this status page was that it has to be lightweight, with no data storage at all. This is where the consolidated API, which I presented in my last post , comes into play.
The KV DAL allows applications to use a well-defined and storage engine agnostic HTTP/gRPC key-value data interface that in turn decouples applications from hard to maintain and backwards-incompatible datastore APIs. As most key-value storage engines support efficiently deleting a namespace (e.g.
Storage mount points in a system might be larger or smaller, local or remote, with high or low latency, and various speeds. Sometimes these locations landed on mount points which, due to capacity, availability, or access constraints, weren’t well suited for large runtime storage. Customizable location of large runtime files.
On average, ScaleGrid provides over 30% more storage vs. DigitalOcean for PostgreSQL at the same affordable price. ScaleGrid for PostgreSQL is architectured to leverage-high performance SSD disks on DigitalOcean, and is finely tuned and optimized to achieve the best performance on DigitalOcean infrastructure. Compare Pricing.
From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step. Since not all projects are terabytes projects, allocating the largest cloud storage to all packager instances is not an efficient use of cloud resources.
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. pg_repack – reorganizes tables online to reclaim storage. PostgreSQL offers more light-weight tuning capabilities, like their Query Optimizer, and DBaaS platforms like ScaleGrid offer advanced slow query analysis.
Cloud vendors such as Amazon Web Services (AWS), Microsoft, and Google provide a wide spectrum of serverless services for compute and event-driven workloads, databases, storage, messaging, and other purposes. Stay tuned for updates. Dynatrace news. 3 End-to-end distributed trace including Azure Functions. New to Dynatrace? trial page
Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage. An additional implication of a lenient sampling policy is the need for scalable stream processing and storage infrastructure fleets to handle increased data volume. Storage: don’t break the bank!
“Logs magnify these issues by far due to their volatile structure, the massive storage needed to process them, and due to potential gold hidden in their content,” Pawlowski said, highlighting the importance of log analysis. Business leaders can decide which logs they want to use and tunestorage to their data needs.
This challenge has given rise to the discipline of observability engineering, which concentrates on the details of telemetry data to fine-tune observability use cases. But often, we use additional services and solutions within our environment for backups, storage, networking, and more. Please stay tuned!
The masking process takes place on the device, even before screenshots are saved to local storage to guarantee that confidential information is never revealed. The masking API we provide allows you to fine-tune the masking configuration to your needs.
Indexes are generally considered to be the panacea when it comes to SQL performance tuning, and PostgreSQL supports different types of indexes catering to different use cases. I keep seeing many articles and talks on “tuning” discussing how creating new indexes speeds up SQL but rarely ones discussing removing them.
Azure Data Lake Storage Gen1. We’ll release additional monitoring support for new services soon, so stay tuned for further updates. We’re happy to announce that now you can gain cloud monitoring excellence with Dynatrace for 15 additional Azure services, including: Azure Automation Account. Azure Logic Apps. Azure Event Grid.
Among these, you can find essential elements of application and infrastructure stacks, from app gateways (like HAProxy), through app fabric (like RabbitMQ), to databases (like MongoDB) and storage systems (like NetApp, Consul, Memcached, and InfluxDB, just to name a few). documentation. Prometheus Data Source documentation.
ScaleGrid provides 30% more storage on average vs. DigitalOcean for MySQL at the same affordable price. As you can see above, ScaleGrid and DigitalOcean offer the same plan configurations across this plan size, apart from SSD where ScaleGrid provides over 20% more storage for the same price. MySQL Configuration Management & Tuning.
Tuning In terms of tuning, two parameters can be tuned, the size of the bitmap and the number of bits set by every value. LSM storage engines like MyRocks are very different from the more common B-Tree-based storage engines like InnoDB.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. Amazon Simple Storage Service (S3). Stay tuned for updates in Q1 2020. Dynatrace news. Amazon Kinesis Video Streams. Amazon Redshift. Amazon Simple Email Service (SES).
Virtualization has revolutionized system administration by making it possible for software to manage systems, storage, and networks. Design, implement, and tune effective SLOs. Consider selecting platform-based solutions — whether open source or from a commercial vendor — that support open ecosystems.
In addition, compute and storage are increasingly being separated causing larger latencies for queries. Alluxio is leveraged as compute-side virtual storage to improve performance. But to get the best performance, like any technology stack, you need to follow the best practices.
In addition, we were able to perform a handful of A/B tests to validate or negate our hypotheses for tuning the search experience. This service leverages Cassandra and Elasticsearch for data storage and retrieval. We will continue to share our work in this space, so stay tuned. Do these types of challenges interest you?
To address potentially high numbers of requests during online shopping events like Singles Day or Black Friday, it’s crucial that this online shop have a memory storage strategy that allows for speed, scaling, and resilience of all microservices, especially the shopping cart service. What’s next?
Storage The type of storage and disk used for database servers can have a significant impact on performance and reliability. Cloud Different cloud providers offer a range of instance types and sizes, each with varying amounts of CPU, memory, and storage. If you see concurrency issues, you can tune this variable.
This may help tune your table level autovacuum settings appropriately. Tuning Autovacuum in PostgreSQL. How do we identify the tables that need their autovacuum settings tuned ? . In order to tune autovacuum for tables individually, you must know the number of inserts/deletes/updates on a table for an interval.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content