This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
Using existing storage resources optimally is key to being able to capture the right data over time. Increased storage space availability. The compression of transaction data older than three days can free up to 50% more storage space in your Dynatrace Managed Cluster. Data compression is completed on June 12.
Acting as the middlemen, Collectors hide all the pesky little details, allowing OpenTelemetry exporters to focus on generating data, and OpenTel backends to focus on storage and analysis. In 2025, we expect to see the first releases, so youll be able to test out this innovative technology.
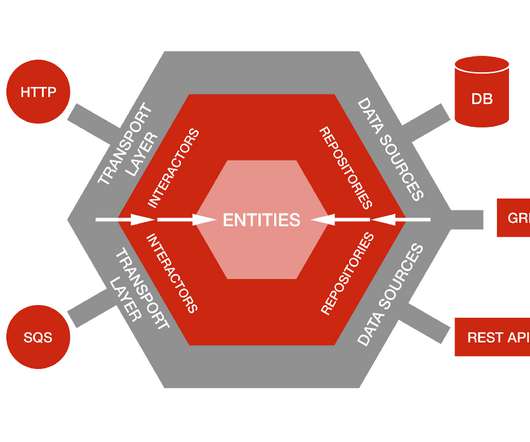
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. Our object storage service splits objects into many parts and stores them in S3.
Disclaimer: This publication may include references to the planned testing, release, and/or availability of Dynatrace products and services. Drive efficiency and get more value out your logs with this predictable pricing model while youre building your log analytics practices.
Why Load Testing Matters in Nebula Graph? The load testing for the database needs to be conducted usually so that the impact on the system can be monitored in different scenarios, such as query language rule optimization, storage engine parameter adjustment, etc. The operating system in this article is the x86 CentOS 7.8.
To resolve the problem it was suggested to find more suitable data storage. The choice affected the project's unit test base. It's still not possible to continue using light-weighted databases such as HSQL or H2 to implement tests. For some internal reasons well known Amazon S3 bucket was chosen for this purpose.
Industry certification for Dynatrace Cost & Carbon Optimization To enhance the trust our customers and partners have in our approach, we commissioned the Sustainable Digital Infrastructure Alliance (SDIA) to test and certify the Cost & Carbon Optimization app. Storage calculations assume that one terabyte consumes 1.2
Use Cases and Requirements At Netflix, our counting use cases include tracking millions of user interactions, monitoring how often specific features or experiences are shown to users, and counting multiple facets of data during A/B test experiments , among others. Let’s take a closer look at the structure and functionality of the API.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Why not just create a table with a JSONB blob and get rid of all columns like the schema below: CREATE TABLE test(id int, data JSONB, PRIMARY KEY (id)); At the end of the day, columns are still the most efficient technique to work with your data. JSONB storage results in a larger storage footprint. This is the default option.
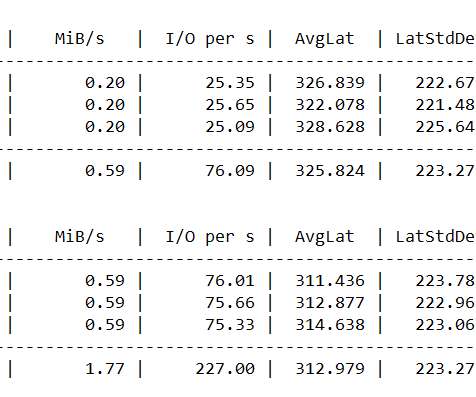
In this article, we will learn how to test our storage subsystems performance using Diskspd. The storage subsystem is one of the key performance factors for SQL Server because SQL Server storage engine stores database objects, tables, and indexes on the physical files.
This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Infrastructure as a service (IaaS) handles compute, storage, and network resources. Increased testing complexity. But how does FaaS fit in? These include the following: Reduced control.
Progressive rollouts, rollbacks, storage orchestration, bin packing, self-healing, cost efficiency, and access to the Cloud Native Computing Foundation (CNCF) ecosystem carry heavy observability challenges. Inadequately tested container images deployed to production. Incidents are harder to solve.
Cosmos DB is a multimodal database in Azure that supports schema-less storage. For key object storage, RU tends to be less, but it still depends on the payload size. Performance tests conducted on 100 partitions and 100K records gave a P95 between 25-30ms for read and write. Cosmos DB cost is measured in RU.)
Additionally, an HTTP API tool, Postman, is used to interact with our application and to test the API functionality. By the end of the tutorial, you’ll have a running Spring Boot app that serves as an HTTP API server with ScyllaDB as the underlying data storage. And you’ll learn how ScyllaDB can be used to store time series data.
DJ stands out as an open source solution that is actively developed and stress-tested at Netflix. DJ has a strong pedigreethere are several prior semantic layers in the industry (e.g. Minerva at Airbnb; dbt Transform, Looker, and AtScale as paid solutions). Wed love to see DJ easing your metric creation and consumption painpoints!
Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage. An additional implication of a lenient sampling policy is the need for scalable stream processing and storage infrastructure fleets to handle increased data volume. Storage: don’t break the bank!
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
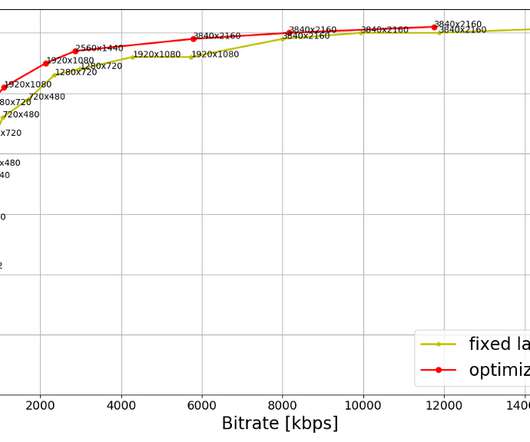
For example, two 1080p points with identical VMAF score or four 4K points with identical VMAF score, resulting in wasted bits and increased storage footprint. The optimized ladder entails a smaller storage footprint compared to the fixed-bitrate ladder. Acknowledgements We thank Lishan Zhu for help rendered during A/B testing.
It differentiates Dynatrace as an AWS Partner Network (APN) member with a fully tested product on AWS Outposts. “We The AWS Service Ready Program was established to support the seamless integration and deployment of AWS services. We are delighted to welcome Dynatrace to the AWS Outposts Ready Program. What is AWS Outposts?
This blog post will provide a detailed analysis of replay traffic testing, a versatile technique we have applied in the preliminary validation phase for multiple migration initiatives. In this testing strategy, we execute a copy (replay) of production traffic against a system’s existing and new versions to perform relevant validations.
Streamline privacy requirements with flexible retention periods Data retention is a critical aspect of data handling, and it’s not just about privacy compliance—it’s about having the flexibility to optimize data storage times in Grail for your Dynatrace use cases. Other data types will be available soon). What’s next?
New processors: Introducing new processors, including Metric Selector and Content Modifier, for selective data processing and metadata adjustment, improving data relevance and storage efficiency. By default, you have a storage type memory, but you may exceed this buffer limit if you have a lot of data.
One of the main advantages we also saw in having an app with clear boundaries is our testing strategy?—?the the majority of our tests can verify our business logic without relying on protocols that can easily change. We knew that a prerequisite to great development velocity was to have a test suite that is reliable and super fast.
Improving testing by using real traffic from production ( Hacker News). Simpler UI Testing with CasperJS ( Architects Zone – Architectural Design Patterns & Best Practices). Email Reveals Google App Engine Search API About Ready For Preview Release, Charges Planned For Storage, Operations ( TechCrunch). Hacker News).
Data Overload and Storage Limitations As IoT and especially industrial IoT -based devices proliferate, the volume of data generated at the edge has skyrocketed. Key issues include: Limited storage capacity on edge devices. Leverage tiered storage systems that dynamically offload data based on priority.
To enhance reliability, testing the software under these conditions is crucial to prepare for potential issues by leveraging chaos engineering or similar tools. Chaos engineering is a practice that extends beyond traditional failure testing by identifying unpredictable issues.
using RL agents for test case scheduling By: Stanislav Kirdey , Kevin Cureton , Scott Rick , Sankar Ramanathan Introduction Netflix brings delightful customer experiences to homes on a variety of devices that continues to grow each day. Detect a regression in a test case. These problems could be solved in several different ways.
Automatically run thousands of automated tests. Ensure manual penetration testing. Every storage location involving data at rest is encrypted as well. Annual independent penetration tests are performed as well, which prove the effectiveness of our security controls with a low number of findings.
Practices include continuous security testing, promoting a mature DevSecOps culture, and more. ” This data is excluded from storage, but teams can still gain value from data enrichment beforehand. ” This data is excluded from storage, but teams can still gain value from data enrichment beforehand. Encryption.
A vital aspect of such development is subjective testing with HDR encodes in order to generate training data. The pandemic, however, posed unique challenges in conducting a conventional in-lab subjective test with HDR encodes. A/B testing also allows us to get a read on the improvement in quality of experience (QoE).
This step is crucial as this environment is used for the final validation and testing phase before the code is released into production. Furthermore, augmenting test coverage to mirror the scenarios encountered in production is imperative. This stage ensures the code meets the required quality standards before it goes live.
This extra cluster, known as a follower cluster, can be leveraged for multiple use cases, including for analyzing, optimizing and testing your application performance for MongoDB , MySQL and PostgreSQL. The ‘follower’ system is writable, so you can use it as a staging environment to test your application changes.
On average, ScaleGrid provides over 30% more storage vs. DigitalOcean for PostgreSQL at the same affordable price. PostgreSQL DigitalOcean Performance Test. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL. ScaleGrid PostgreSQL provides on average 42.3% Single Node.
We rewrote almost all of the storage used for storing code analysis results while maintaining backwards compatibility and without any outages. It took several weeks of intense collaboration, designing, iterative implementation, and testing in production.
Standalone deployments are a single node without any replication, and should really only be used for development or testing environments. Your performance tests may also show that you need more I/O (input/output), you can move to a disk-intensive instance type. MySQL Dev/Test Environments: Standard Disks.
There is no need to think about schema and indexes, re-hydration, or hot/cold storage. Dynatrace Grail™ data lakehouse is schema-on-read and indexless, built with scaling in mind. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new logs app.
Since database hosting is more dependent on memory (RAM) than storage, we are going to compare various instance sizes ranging from just 1GB of RAM up to 64GB of RAM so you can see how costs vary across different application workloads. See performance tests to determine the impact of the Meltdown CPU kernel patch on your MongoDB servers.
Our previous blog post presented replay traffic testing — a crucial instrument in our toolkit that allows us to implement these transformations with precision and reliability. Compared to replay testing, canaries allow us to extend the validation scope beyond the service level.
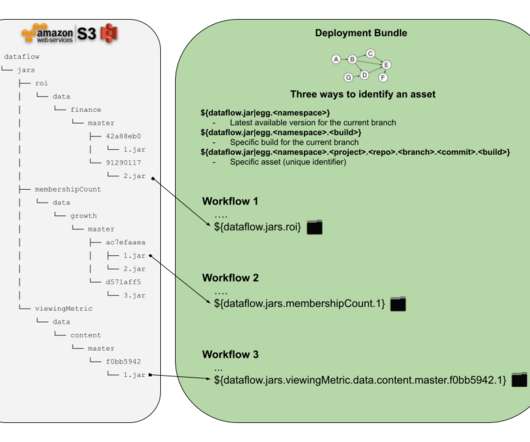
Previous solutions The basic approach to pulling down arbitrary workflow resources during workflow execution has been known to mankind since the invention of cron, and with the advent of “infinite” cloud storage systems like S3, this approach has served us for many years. Where should this alternative location be in S3?
Finally, just 50% are confident their applications have been tested for vulnerabilities before going into production. Dehydrated data has been compressed or otherwise altered for storage in a data warehouse. Observability starts with the collection, storage, and accessibility of multiple sources.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content