This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
As software pipelines evolve, so do the demands on binary and artifact storage systems. While solutions like Nexus, JFrog Artifactory, and other package managers have served well, they are increasingly showing limitations in scalability, security, flexibility, and vendor lock-in.
Because of the emergence of cloud services, a broad range of storage choices are now easily available to fulfill the different demands of both organizations and people. These storage alternatives have been designed to meet a range of requirements, including performance, scalability, durability, and price.
Built on Azure Blob Storage, Azure Data Lake Storage Gen2 is a suite of features for big data analytics. Azure Data Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2. For instance, Data Lake Storage Gen2 offers scale, file-level security, and file system semantics.
One key factor that significantly affects the performance of data processing is the storage format of the data. This article explores the impact of different storage formats, specifically Parquet, Avro, and ORC on query performance and costs in big data environments on Google Cloud Platform (GCP).
This comprehensive guide will walk you through the crucial steps of setting up networking, managing storage, running containers, and installing Docker. Thanks to Docker, a leading containerization platform, applications can be packaged and distributed more easily in portable, isolated environments.
Using existing storage resources optimally is key to being able to capture the right data over time. Increased storage space availability. The compression of transaction data older than three days can free up to 50% more storage space in your Dynatrace Managed Cluster. Data compression is completed on June 12.
Finding a storage solution for our ultra-heterogeneous computing cluster was challenging. We tried two solutions: object storage with s3fs + network-attached storage (NAS) and Alluxio + Fluid + object storage , but they had limitations and performance issues.
In this guide, we’ll walk through the implementation of an LSM tree in Golang , discuss features such as Write-Ahead Logging ( WAL ), block compression, and BloomFilters , and compare it with more traditional key-value storage systems and indexing strategies.
Twilio is a call management system that provides excellent call recording capabilities, but often organizations are in need of automatically downloading and storing these recordings locally or in their preferred cloud storage. However, downloading large numbers of recordings from Twilio can be challenging.
As a developer, engineer, or architect, finding the right storage solution that seamlessly integrates with your infrastructure while providing the necessary scalability, security, and performance can be a daunting task. Whether you're a small startup or a large enterprise, StoneFly's storage solutions can grow with your business.
Simplify data ingestion and up-level storage for better, faster querying : With Dynatrace, petabytes of data are always hot for real-time insights, at a cold cost. Worsened by separate tools to track metrics, logs, traces, and user behaviorcrucial, interconnected details are separated into different storage.
This article analyzes the correlation between block sizes and their impact on storage performance. This paper deals with definitions and understanding of structured data vs unstructured data, how various storage segments react to block size changes, and differences between I/O-driven and throughput-driven workloads.
However, lurking beneath the surface lies a complex web of data storage and retrieval. That's why knowing how to debug mobile app database problems and optimize data storage performance is essential for developers seeking excellence. In the dynamic realm of mobile app development , a flawless user experience is the ultimate goal.
A shared vision At Dynatrace, weve built a comprehensive observability platform that already includes deep database visibility, the Top Database Statements view, and Grail for unified data storage and analysis.
By ensuring that all processes—from data collection to storage and usage—comply with regulatory requirements, organizations can better manage potential threats. Retention periods and access controls must be properly configured to protect such PII.
Acting as the middlemen, Collectors hide all the pesky little details, allowing OpenTelemetry exporters to focus on generating data, and OpenTel backends to focus on storage and analysis. Thats where the OpenTelemetry Collector can help. The Collector is expected to be ready for prime time in 2025, reaching the v1.0
As more organizations move their PostgreSQL databases onto Kubernetes, a common question arises: Which storage solution best handles its demands? For stateful workloads like PostgreSQL, storage must offer high availability and safeguard data integrity, even under intense, high-volume conditions.
The Grail™ data lakehouse provides fast, auto-indexed, schema-on-read storage with massively parallel processing (MPP) to deliver immediate, contextualized answers from all data at scale. Through Azure Native Dynatrace Service, customers can seamlessly adopt these technologies to modernize and enhance their cloud operations.
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Let’s examine some of the drawbacks of this approach: Lack of Idempotency : There is no idempotency key baked into the storage data-model preventing users from safely retrying requests.
Besides the need for robust cloud storage for their media, artists need access to powerful workstations and real-time playback. Local storage and compute services are connected through the Netflix Open Connect network (Netflix Content Delivery Network) to the infrastructure of Amazon Web Services (AWS).
Storage calculations assume that one terabyte consumes 1.2 Cloud storage is replicated twice, which doubles the energy consumption per terabyte. CPU calculations apply these assumptions: A virtual CPU (vCPU) on any cloud host equals one thread of a physical CPU core, with two threads per core.
Cost-efficient: Lowest upfront cost Charges are strictly based on query execution Scalability: Ideal for businesses with varying query demands Adapt dynamically to usage patterns Retention: Supports log storage from 1 day to 10 years Optimalfor longer-term log analytics needs Guidance on using both plans The Retain with Included Queries pricing option (..)
Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. Message Broker vs. Distributed Event Streaming Platform RabbitMQ functions as a message broker, managing message confirmation, routing, storage, and delivery within a queue. What is RabbitMQ?
Reduced storage and query overhead for business use cases. Sensitive business data is separated from IT observability data. Improved data management. Fine-grained permission and retention policies can be tailored to individual business use cases. Business events are a small, often negligible subset of log data.
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Polymorphic Data Storage. Greenplum’s polymorphic data storage allows you to control the configuration for your table and partition storage with the freedom to execute and compress files within it at any time.
Say hello to advanced trace an alytics and new data storage and capture options. Youcan share data in buckets with varying retention times depending on the use case, allowing you to target specific applications or error-prone services for longer storage. But why stop there?
In this article, I will walk through a comprehensive end-to-end architecture for efficient multimodal data processing while striking a balance in scalability, latency, and accuracy by leveraging GPU-accelerated pipelines, advanced neural networks , and hybrid storage platforms.
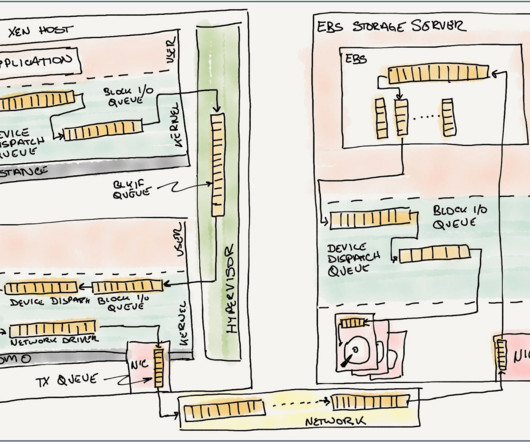
Marc Olson, a long-time Amazonian, discusses the evolution of EBS, highlighting hard-won lessons in queueing theory, the importance of comprehensive instrumentation, and the value of incrementalism versus radical changes. It's an insightful look at how one of AWS’s foundational services has evolved to meet the needs of our customers.
JSONB storage has some drawbacks vs. traditional columns: PostreSQL does not store column statistics for JSONB columns. JSONB storage results in a larger storage footprint. JSONB storage does not deduplicate the key names in the JSON. If that doesn’t work, the data is moved to out-of-line storage.
Microsoft Azure SQL is a robust, fully managed database platform designed for high-performance querying, relational data storage, and analytics. For a typical web application with a backend, it is a good choice when we want to consider a managed database that can scale both vertically and horizontally.
Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity. Fetching User Feed. Sample Queries supported by Graph Database. Optimization.
Operational resilience with observability and security Executives might not have considered the role that Dynatrace can play in their security compliance efforts because they see the platform as an observability solution. Were challenging these preconceptions.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
It is the second of a series of articles that is built on top of that project, representing experiments with various statistical and machine learning models, data pipelines implemented using existing DAG tools, and storage services, both cloud-based and alternative on-premises solutions.
The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table. This refined output is then structured using an Avro schema, establishing a definitive source of truth for Netflixs impression data.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
Therefore, they need an environment that offers scalable computing, storage, and networking. Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. What is hyperconverged infrastructure?
At first, data tiering was a tactic used by storage systems to reduce data storage costs. This involved grouping data that was not accessed as often into more affordable, if less effective, storage array choices. Even though they are quite costly, SSDs and flash can be categorized as high-performance storage classes.
Unlike full backups that duplicate everything, incremental backups store only changes since the last save, reducing storage needs and speeding up recovery. Key Benefits: Smaller Storage Footprint: Saves only modified data, cutting down backup size. How do incremental backups work in PostgreSQL 17?
Data migration involves transferring data from on-premise storage to the cloud. Data migration is the process of moving data from one location to another, which is an essential aspect of cloud migration. With the rapid adoption of cloud computing , businesses are moving their IT infrastructure to the cloud.
You quickly realize that it will take ages to fill up the overprovisioned database storage. Two days later, your database runs out of storage in the middle of the night. Therefore, you don’t know your current growth rate and can’t estimate the required storage for keeping the database up and running for the next month.
Masking at storage: Data is persistently masked upon ingestion into Dynatrace. Leverage three masking layers Masking at capture and masking at storage operations exclude targeted sensitive data points. When using Dynatrace OneAgent ® , captured data doesn’t leave the monitored environment.
This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storage systems (which are used by data lakes). This decoupling ensures the openness of data and storage formats, while also preserving data in context. Grail is built for such analytics, not storage.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content