This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
Before a new version of the application is deployed, the software is subject to a series of load tests that evaluate capacity and performance under a series of simulated traffic and application demands. These metrics are latency, traffic, errors, and saturation, all of which must be key considerations when curating user experience.
For retail organizations, peak traffic can be a mixed blessing. While high-volume traffic often boosts sales, it can also compromise uptimes. The nirvana state of system uptime at peak loads is known as “five-nines availability.” How can IT teams deliver system availability under peak loads that will satisfy customers?
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. Performance Optimizations PostgreSQL 17 significantly improves performance, query handling, and database management, making it more efficient for high-demand systems.
Introduction to Message Brokers Message brokers enable applications, services, and systems to communicate by acting as intermediaries between senders and receivers. This decoupling simplifies system architecture and supports scalability in distributed environments.
In doing so, they automate build processes to speed up delivery, and minimize human involvement to prevent error. One is the currently-running production environment receiving all user traffic (let’s say the “blue” one), the other is a clone of it (“green”), but idle. Response time for blue/green environment traffic.
The system could work efficiently with a specific number of concurrent users; however, it may get dysfunctional with extra loads during peak traffic. Performances testing helps establish the scalability, stability, and speed of the software application.
As organizations digitally transform, they’re also accelerating the speed of software delivery. It represents the percentage of time a system or service is expected to be accessible and functioning correctly. Response time Response time refers to the total time it takes for a system to process a request or complete an operation.
Over the last two month s, w e’ve monito red key sites and applications across industries that have been receiving surges in traffic , including government, health insurance, retail, banking, and media. The following day, a normally mundane Wednesday , traffic soared to 128,000 sessions. Media p erformance .
SREs use Service-Level Indicators (SLI) to see the complete picture of service availability, latency, performance, and capacity across various systems, especially revenue-critical systems. Siloed teams and multiple tools make it difficult to align on a single version of the truth for overall system health.
In turn, IAC offers increased deployment speed and cross-team collaboration without increased complexity. But this increased speed can’t come at the expense of control, compliance, and security. Making the move to IAC offers multiple benefits, including the following: Speed. Consistency. A lignment.
This speeds up your teams’ mean time to identify (MTTI) issues and repair (MTTR), increasing business resiliency to disruptions. One change to send syslog to Dynatrace You can now use the syslog ingestion endpoint on Dynatrace Environment ActiveGate for performant network and system monitoring.
But managing the breadth of the vulnerabilities that can put your systems at risk is challenging. ” Moreover, as modern DevOps practices have increased the speed of software delivery, more than two-thirds (69%) of chief information security officers (CISOs) say that managing risk has become more difficult.
In today’s world, the speed of innovation is key to business success. WAFs protect the network perimeter and monitor, filter, or block HTTP traffic. Compared to intrusion detection systems (IDS/IPS), WAFs are focused on the application traffic. Dynatrace news. Unfortunately, they also introduce risk.
IoT is transforming how industries operate and make decisions, from agriculture to mining, energy utilities, and traffic management. They enable real-time tracking and enhanced situational awareness for air traffic control and collision avoidance systems. The ADS-B protocol differs significantly from web technologies.
Uptime Institute’s 2022 Outage Analysis report found that over 60% of system outages resulted in at least $100,000 in total losses, up from 39% in 2019. Microservices-based architectures and software containers enable organizations to deploy and modify applications with unprecedented speed. Make SLOs realistic.
While digital experience has many facets, transaction speed usually ranks among the most important. IT teams spend months preparing for the peak traffic they anticipate will arrive with holiday shopping. From first to lasting impressions But there’s more to digital experience than speed. Technology to the rescue?
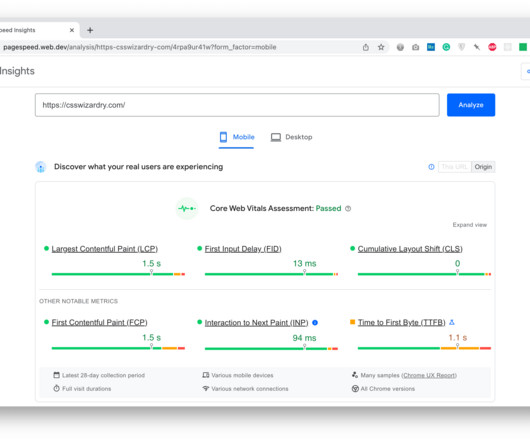
Google do strongly encourage you to focus on site speed for better performance in Search, but, if you don’t pass all relevant Core Web Vitals (and the applicable factors from the Page Experience report) they will not push you down the rankings. All Core Web Vitals data used to rank you is taken from actual Chrome-based traffic to your site.
However, not all user monitoring systems are created equal. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). RUM generates a lot of data.
For example, an organization might use security analytics tools to monitor user behavior and network traffic. Teams can then act before attackers have the chance to compromise key data or bring down critical systems. This data helps teams see where attacks began, which systems were targeted, and what techniques attackers used.
As the number of Titus users increased over the years, the load and pressure on the system increased substantially. cell): Titus Job Coordinator is a leader elected process managing the active state of the system. For example, a batch workflow orchestration system may create multiple jobs which are part of a single workflow execution.
Measuring application performance is increasingly important because as organizations digitally transform, they’re also accelerating the speed of software delivery. It represents the percentage of time a system or service is expected to be accessible and functioning correctly. Availability is typically expressed in 9’s, such as 99.9%.
Answering Common Questions About Interpreting Page Speed Reports Answering Common Questions About Interpreting Page Speed Reports Geoff Graham 2023-10-31T16:00:00+00:00 2023-10-31T17:06:18+00:00 This article is sponsored by DebugBear Running a performance check on your site isn’t too terribly difficult. Source: Source: DebugBear.
She was speaking about how her team is providing Visibility as a Service (VaaS) in order to continuously monitor and optimize their systems running across private and public cloud environments. A big factor in good Digital Performance is the back-end system that powers your digitally offered use-cases.
CLI tools The Cassandra systems were EC2 virtual machine (Xen) instances. Since instances of both CentOS and Ubuntu were running in parallel, I could collect flame graphs at the same time (same time-of-day traffic mix) and compare them side by side. Microbenchmark os::javaTimeMillis() on both systems. include <sys/time.h>
Today, the speed of software development has become a key business differentiator, but collaboration, continuous improvement, and automation are even more critical to providing unprecedented customer value. Resilience : Critical production business systems must not fail. Automated release inventory and version comparison.
In addition, monitoring DevOps processes provide the following benefits: Improve system performance. Monitoring provides a clearer, more consistent picture of DevOps system performance and overall health. Help systems meet SLAs. Increase system uptime. DevOps monitoring also helps teams meet their SLAs for system uptime.
In our increasingly digital world, the speed of innovation is key to business success. As a result, e xisting application security approaches can’t keep up with this speed and vari ability of modern development processes. . Dynatrace news. Organizations are rushing towards cloud-native application stacks for agility.
Think about items such as general system metrics (for example, CPU utilization, free memory, number of services), the connectivity status, details of our web server, or even more granular in-application tasks like database queries. Let’s take a look at what kind of additional telemetry data we will have at our fingertips with OneAgent.
I selfishly look at my blog posts (like this one) and see whether LinkedIn, or Twitter, drove more traffic! If I see tolerating and frustrated visitors, is it related to a region, country, device, or an operating system? Also, the speed at which people scroll means we will consider A/B testing pages with far less copy.
Resource consumption & traffic analysis. What is the network traffic going to be between services we migrate and those that have to stay in the current data center? How much traffic is sent between two processes hosting a certain service? Step 3: Detailed Traffic Dependency Analysis. What’s in your stack?”.
This test helps to measure the speed, scalability, reliability, and stability of software under varying loads, thus it ensures stable performance. Performance testing is a non-functional type of software testing technique that is performed to know the performance of the current system. What Is Performance Testing?
Exploratory data analytics is an analysis method that uses visualizations, including graphs and charts, to help IT teams investigate emerging data trends and circumvent issues, such as unexpected traffic spikes or performance degradations. Start by asking yourself what’s there, whether it’s logs, metrics, or traces.
Page slowdowns can cause as much damage as downtime While Amazon and other big players take pains to avoid outages, these companies also go to great effort to manage the day-to-day performance – in terms of page speed and user experience – of their sites. It’s a big piece, to be sure, but there are others.
Allows them to speed up MTTR (Mean Time to Repair) in order to minimize user impact. NYCM is pushing Dynatrace problems into their HelpDesk system, where new tickets get created and automatically populated with the problem context details. Delivers impact and root cause. 8:32 am Fix Confirmed – Problem Closed – User Impact Prevented!
This operational component places some cognitive load on our engineers, requiring them to develop deep understanding of telemetry and alerting systems, capacity provisioning process, security and reliability best practices, and a vast amount of informal knowledge about the cloud infrastructure.
Some of the largest enterprises and public sector organizations in Italy are using AWS to build innovations and power their businesses, drive cost savings, accelerate innovation, and speed time-to-market. To meet such large traffic numbers, they need a technology infrastructure that is secure, reliable, and flexible.
To speed up release frequency, they’re investing in delivery-pipeline automation. The flip side of speeding up delivery, however, is that each software release comes with the risk of impacting your goals of availability, performance, or any business KPIs.
VPC Flow Logs VPC Flow Logs is an AWS feature that captures information about the IP traffic going to and from network interfaces in a VPC. By default, each record captures a network internet protocol (IP) traffic flow (characterized by a 5-tuple on a per network interface basis) that occurs within an aggregation interval.
FlexBalancer makes it easy to manage traffic between multiple CDN providers, API’s, Databases or any custom endpoint helping you achieve better performance, ensure the availability of services and reduce vendor costs. View and analyze all your logs and system metrics from multiple sources in one place. Learn more today.
Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution. There are multiple tables MySQL internal system manages that come in handy, identifying the inefficient indexes, to name a few: sys.schema_unused_indexes, and information_schema.index_statistics.
This has a value of increasing competitive advantage through rapid, targeted feature delivery while at the same time ensuring system availability, stability and resilience. These deployment options are great because they allow businesses to embrace “continuous experimentation”.
FlexBalancer makes it easy to manage traffic between multiple CDN providers, API’s, Databases or any custom endpoint helping you achieve better performance, ensure the availability of services and reduce vendor costs. View and analyze all your logs and system metrics from multiple sources in one place. Learn more today.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content