This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the vast realm of software development, there's a pursuit for softwaresystems that are not only robust and efficient but can also "heal" themselves. Self-healing softwaresystems represent a significant stride towards automation and resilience. 4 Key Strategies for Building Self-Healing SoftwareSystems 1.
Scale to zero Scaling systems to match current demand prevents underutilized machines from consuming significant energy while idling. While building production systems that can scale to zero and reliably restart can be challenging, it’s often simpler in test stages and build pipelines, making this a great place to start.
To understand whats happening in todays complex software ecosystems, you need comprehensive telemetry data to make it all observable. In fact, observability is essential for shaping how we design smarter, more resilient systems for the future. First, it allows human operators to correctly interpret the data they’re seeing.
Software is everywhere these days - from our phones to cars and appliances. That means it's important that softwaresystems are dependable, robust, and resilient. Resilient systems can withstand failures or errors without completely crashing. It lets systems keep working properly even when problems occur.
As recent events have demonstrated, major software outages are an ever-present threat in our increasingly digital world. From business operations to personal communication, the reliance on software and cloud infrastructure is only increasing. Software bugs Software bugs and bad code releases are common culprits behind tech outages.
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. In this blog post, we delve into these challenges and explore how Dynatrace can address them to enhance the reliability of released software.
In today’s digital world, software is everywhere. Software is behind most of our human and business interactions. This, in turn, accelerates the need for businesses to implement the practice of software automation to improve and streamline processes. What is software automation? What is software analytics?
After years of working in the intricate world of software engineering, I learned that the most beautiful solutions are often those unseen: backends that hum along, scaling with grace and requiring very little attention. Developers could understand and manage the entire systems intricacies.
With companies striving to update and publish software rapidly, the learnings from this global panic stemming from one endpoint security software update are telling. The ramifications of the CrowdStrike outage showcase the difficulties in software development today.
Regarding contemporary software architecture, distributed systems have been widely recognized for quite some time as the foundation for applications with high availability, scalability, and reliability goals. Spring Boot Overview One of the most popular Java EE frameworks for creating apps is Spring.
Embedded systems have become an integral part of our daily lives, from smartphones and home appliances to medical devices and industrial machinery. These systems are designed to perform specific tasks efficiently, often in real-time, without the complexities of a general-purpose computer.
CPU isolation and efficient system management are critical for any application which requires low-latency and high-performance computing. These measures are especially important for high-frequency trading systems, where split-second decisions on buying and selling stocks must be made.
The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Most teams approach this like traditional software development but quickly discover it’s a fundamentally different beast. Traditional versus GenAI software: Excitement builds steadilyor crashes after the demo. The way out?
As display manufacturing continues to evolve, the demand for scalable software solutions to support automation has become more critical than ever. Scalable software architectures are the backbone of efficient and flexible production lines, enabling manufacturers to meet the increasing demands for innovative display technologies.
In the realm of modern software architecture, middleware plays a pivotal role in connecting various components of distributed systems. Efficient database operations in middleware can dramatically improve overall system performance, reduce latency, and enhance user experience.
When organizations implement SLOs, they can improve software development processes and application performance. SLOs improve software quality. Stable, well-calibrated SLOs pave the way for teams to automate additional processes and testing throughout the software delivery lifecycle. SLOs aid decision making. Saturation.
The evolution of enterprise software engineering has been marked by a series of "less" shifts — from client-server to web and mobile ("client-less"), data center to cloud ("data-center-less"), and app server to serverless.
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. ETL workflows), as well as downstream (e.g.
According to recent research from TechTarget’s Enterprise Strategy Group (ESG), generative AI will change software development activities, from quality assurance to debugging to CI/CD pipeline configuration. On the whole, survey respondents view AI as a way to accelerate software development and to improve software quality.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
This rising risk amplifies the need for reliable security solutions that integrate with existing systems. Membership in MISA is nomination-only and reserved for independent software vendors who develop security solutions that effectively integrate with MISA-qualifying Microsoft Security products.
Unit testing is an essential part of software development. Unit tests help to check the correctness of newly written logic as well as prevent a system from regression by testing old logic every time (preferably with every build). However, there are two different approaches (or schools) to writing unit tests: Classical (a.k.a
Shifting to customer-centric IT For observability data to be meaningful, it must connect the performance of IT systems to customer experience throughout their journey, across both digital and physical touchpoints. Only then can executives understand whether their software helps to deliver the intended business outcomes.
GPT (generative pre-trained transformer) technology and the LLM-based AI systems that drive it have huge implications and potential advantages for many tasks, from improving customer service to increasing employee productivity.
By automating root-cause analysis, TD Bank reduced incidents, speeding up resolution times and maintaining system reliability. To improve this, they turned to Dynatrace for AI-driven automation to accelerate problem detection and resolution. The result? This ability to innovate faster has given TD Bank a competitive edge in a complex market.
Discover how Livi navigated the complexities of transitioning MJog, a legacy healthcare system, to a cloud-native architecture, sharing valuable insights for successful tech modernization. Our experience illustrates that transitioning from legacy systems to cloud-based microservices is not a one-time project but an ongoing journey.
Microservices architecture has revolutionized modern software development, offering unparalleled agility, scalability , and maintainability. However, effectively implementing microservices necessitates a deep understanding of best practices to harness their full potential while avoiding common pitfalls.
Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable. Data often lacks context, hampering attempts to analyze full-stack, dependent services, across domains, throughout software lifecycles, and so on.
In this blog post, we will see how Dynatrace harnesses the power of observability and analytics to tailor a new experience to easily extend to the left, allowing developers to solve issues faster, build more efficient software, and ultimately improve developer experience!
Establish a proactive process to keep your products and systems as up-to-date as possible. Finally, establish a clear process to continuously and proactively prevent malicious attacks from entering your systems. Next, choose projects that are easily maintainable and securable, now and in the future. Stay up to date.
The cybersecurity industry was once again placed on high alert following the discovery of an insidious software supply chain compromise. Allowing remote code execution (RCE) in some instances if successfully exploited represents a high-severity issue with the ability to cause serious damage in established software build processes.
Observability has become a key component in software development as it enables the best customer experience by ensuring system health and performance and detecting systemic issues proactively. However, getting started can often feel overwhelming.
At QCon San Francisco 2024, software architecture is front and center, with two tracks dedicated to exploring some of the largest and most complex architectures today. Join senior software practitioners as they provide inspiration and practical lessons for architects seeking to tackle issues at a massive scale. By Artenisa Chatziou
To remain competitive in today’s fast-paced market, organizations must not only ensure that their digital infrastructure is functioning optimally but also that software deployments and updates are delivered rapidly and consistently. They help foster confidence and consistency throughout the entire software development lifecycle (SDLC).
Enhanced observability and release validation Dynatrace already excels at delivering full-stack, end-to-end observability of your systems and user journeys. Everyone involved in the software delivery lifecycle can work together more effectively with a single source of truth and a shared understanding of pipeline performance and health.
Failures in a distributed system are a given, and having the ability to safely retry requests enhances the reliability of the service. Implementing idempotency would likely require using an external system for such keys, which can further degrade performance or cause race conditions.
Heres more about the VMware security advisory and how you can quickly find affected systems using Dynatrace so you canautomate remediation efforts. With a TOCTOU vulnerability, an attacker can manipulate a system between the time a resource’s state is checked and when it’s used, also known as a race condition.
Our detailed analysis not only illuminates the specifics of CVE-2024-53677 but also offers practical measures to secure your softwaresystems against similar threats. Organizations can better protect their systems and data from exploitation by comprehensively addressing each phase.
TL;DR: Enterprise AI teams are discovering that purely agentic approaches (dynamically chaining LLM calls) dont deliver the reliability needed for production systems. The prompt-and-pray modelwhere business logic lives entirely in promptscreates systems that are unreliable, inefficient, and impossible to maintain at scale.
Observability is no longer just for IT Ops Observability is no longer just about monitoring IT systems. Today, observability is integral to the entire software development lifecycle. wanted to take a moment to expandon thekey themes we touched on in our conversation. Its aboutunderstandingand automating the entire digital ecosystem.
You can verify any system settings that might impact your tests and see them in action. Performance benchmarking Performance benchmarking is one of the unresolved mysteries of software engineering. Maybe you want to monitor performance under different system loads. In many ways, it’s more of an art than a science.
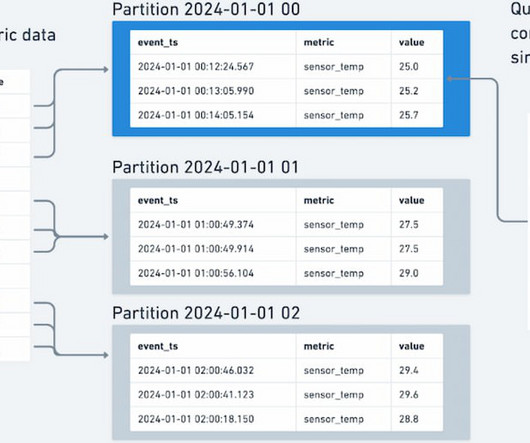
Editor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Database Systems: Modernization for Data-Driven Architectures. Time series data has become an essential part of data collection in various fields due to its ability to capture trends, patterns, and anomalies.
It doesn’t matter if you need typically used failure-rate or response-time metrics to ensure your system’s availability and performance or if you need to rely on abnormal log drops to gain insights into raising problems—SLOs leveraged with Grail provide all the information you need.
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes moved to the cloud in 2022.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content