This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
API resilience is about creating systems that can recover gracefully from disruptions, such as network outages or sudden traffic spikes, ensuring they remain reliable and secure. In this article, Ill share practical strategies for designing APIs that scale, handle errors effectively, and remain secure over time.
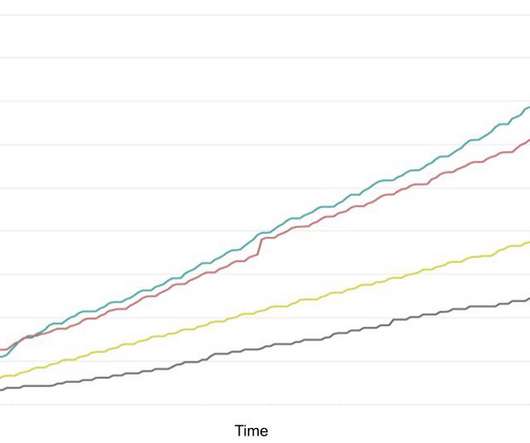
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline. An anomaly will be identified if traffic suddenly drops below 200 Mbps or above 800 Mbps, helping you identify unusual spikes or drops.
The complexity of these operational demands underscored the urgent need for a scalable solution. To detect issues proactively, we need to simulate traffic and predict system behavior in advance. Once artificial traffic is generated, discarding the response object and relying solely on logs becomes inefficient.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. We call this capability TimeTravel.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Youll also learn strategies for maintaining data safety and managing node failures so your RabbitMQ setup is always up to the task. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount.
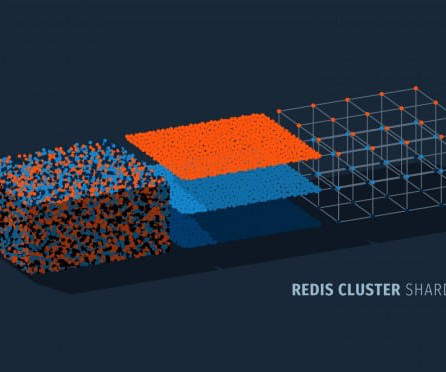
In this article, we’ll dive deep into the concept of database sharding, a critical technique for scaling databases to handle large volumes of data and high levels of traffic. This section will provide insights into the architecture and strategies to ensure efficient query processing in a sharded environment.
The breadth of fully-featured services, the pay-as-you-go scalability, and the agility of cloud platforms enable organizations to expand their modern approaches to building and managing digital services in a way they can’t with on-premises apps and infrastructure. Increased scalability. Reduced cost.
This decoupling simplifies system architecture and supports scalability in distributed environments. Kafka stores and distributes data through a partitioned log system, which spans multiple brokers to provide fault tolerance and scalability. What is RabbitMQ? This allows Kafka clusters to handle high-throughput workloads efficiently.
It’s also critical to have a strategy in place to address these outages, including both documented remediation processes and an observability platform to help you proactively identify and resolve issues to minimize customer and business impact. Outages can disrupt services, cause financial losses, and damage brand reputations.
Confused about multi-cloud vs hybrid cloud and which is the right strategy for your organization? Key Takeaways Multi-cloud involves using services from multiple cloud providers to gain flexibility and reduce vendor lock-in, while hybrid cloud combines private and public cloud resources to balance control and scalability.
PostgreSQL 17 provides faster processing, greater efficiency, and better scalability for modern database needs. Read Also: Best PostgreSQL GUI Incremental Backups PostgreSQL 17 introduces incremental backups , a game-changer for large and high-traffic databases.
Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. An effective IT infrastructure monitoring strategy includes the following best practices: Determine the best cloud tooling and services for your specific cloud environment. Website monitoring. Cloud-server monitoring.
In many ways, the shift to cloud computing and the adoption of cloud-native architectures have enabled organizations to realize greater resiliency alongside scalability. But in a cloud-native world, resiliency must expand to include the ability for organizations to recover quickly from failures and ensure business continuity.
The Key-Value Abstraction offers a flexible, scalable solution for storing and accessing structured key-value data, while the Data Gateway Platform provides essential infrastructure for protecting, configuring, and deploying the data tier. Let’s dive into the various aspects of this abstraction.
In reality, only highly scalable RUM solutions can collect data on all user actions, while less scalable tools must sample user actions and make inferences from partial data. RUM, however, has some limitations, including the following: RUM requires traffic to be useful. Real user monitoring limitations.
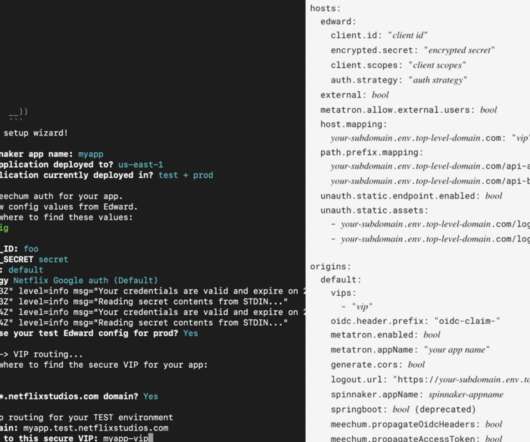
com and the strategies we use to keep it up and running with high availability. The number of services that compose our product in order to scale our organization and handle the increases in traffic went from under 10 to over 30 services. A lot has changed since then in Auth0.
An additional implication of a lenient sampling policy is the need for scalable stream processing and storage infrastructure fleets to handle increased data volume. The next challenge was to stream large amounts of traces via a scalable data processing platform. Mantis is our go-to platform for processing operational data at Netflix.
That’s why traceability, scalability, and reliability are crucial aspects of a cloud strategy, and for this county, OpenShift and Dynatrace delivered on these needs. Dynatrace’s AI engine, Davis automatically identified high traffic surges on the county website as the fire took hold. High Traffic Notification.
For example, an organization might use security analytics tools to monitor user behavior and network traffic. Bolstered by powerful AI and intelligent automation, Dynatrace can help your organization stay secure, efficient, and scalable.
Existing data got updated to be backward compatible without impacting the existing running production traffic. Data Sharding strategy in elasticsearch is updated to provide low search latency (as described in blog post) Design of new Cassandra reverse indices to support different sets of queries.
Let’s delve deeper into how these capabilities can transform your observability strategy, starting with our new syslog support. It also enhances syslog messages with additional context and optimizes network traffic, improving overall system resilience and security.
Resource consumption & traffic analysis. If you want to read up on migration strategies check out my blog on 6-R Migration Strategies. What is the network traffic going to be between services we migrate and those that have to stay in the current data center? Step 3: Detailed Traffic Dependency Analysis.
With traffic growth, a single leader node handling all request volume started becoming overloaded. Doing so would require a substantial migration effort to move all clients off the old API with questionable value to the affected teams (except for helping us solve Titus' internal scalability problems). queries/sec.
Research by the Enterprise Strategy Group in 2020 shows 60% of reported breached production applications in the past 12 months involved a known and unpatched vulnerability. It inherits the automation, AI, scalability, and enterprise-grade robustness of the Dynatrace platform.
They utilize a routing key mechanism that ensures precise navigation paths for message traffic. Scalability : Message queues can handle multiple requests and messages simultaneously, making it easier to scale an application to meet increasing demands. This scalability is essential for applications that experience fluctuating workloads.
This article delves into the specifics of how AI optimizes cloud efficiency, ensures scalability, and reinforces security, providing a glimpse at its transformative role without giving away extensive details. Exploring artificial intelligence in cloud computing reveals a game-changing synergy.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. By implementing data replication strategies, distributed storage systems achieve greater.
Deployment Strategies We are all familiar with the advantages of releasing frequently and in smaller chunks. Depending on the type of client, we need to determine the right strategy to sample consumer devices, and provide a system that can enable various client engineering teams to look for their signals.
Supporting developers through those checklists for edge cases, and then validating that each team’s choices resulted in an architecture with all the desired security properties, was similarly not scalable for our security engineers. an application deployment strategy that guarantees authentication for services behind it.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Blocking write traffic by locking tables. Writing events to any output.
Automatic failover is a critical strategy to achieve this. No Test Scenario Observation 1 Network isolate the standby server from other servers Corosync traffic was blocked on the standby server. 2 Network isolate the master server from other servers (split-brain scenario) Corosync traffic was blocked on the master server.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Blocking write traffic by locking tables. Writing events to any output.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. These strategies help maintain system performance, reduce read overhead, and meet SLOs by minimizing the impact of deletes.
This article cuts through the complexity to showcase the tangible benefits of DBMS, equipping you with the knowledge to make informed decisions about your data management strategies. Scalability and Flexibility Scalability in DBMS refers to the system’s capacity to expand and accommodate the growing data needs of an organization.
But for those who are not so familiar, in this post, we will discuss how Kubernetes has emerged as the unsung hero in an industry where agility and scalability are critical success factors. Applications can be horizontally scaled with Kubernetes by adding or deleting containers based on resource allocation and incoming traffic demands.
As VMAF evolves and is integrated with more encoding and streaming workflows within Netflix, we need scalable ways of fostering video quality innovations. The Reloaded system is a well-matured and scalable system, but its monolithic architecture can slow down rapid innovation.
We were pushing the limits of what was a leading commercial database at the time and were unable to sustain the availability, scalability and performance needs that our growing Amazon business demanded. We had an advanced team of database administrators and access to top experts within Oracle.
It enhances scalability and manages traffic surges, though it requires specific client support and limits multi-key operations to a single hash slot. It offers automatic data sharding, master-replica configurations for high availability, and a scalable and flexible architecture to maintain consistent performance.
implement a M-CDN, organizations can use traffic management tools or Multi-CDN switching solutions that distribute and route content across the various CDN providers. Network RedundancyThe primary and most important advantage of a Multi-CDN strategy is redundancy, and, consequently, improved reliability.
It employs the Advanced Message Queuing Protocol (AMQP) to provide reliable, scalable message passing, crucial for modern applications dealing with large-scale, complex data flows. Additionally, the low coupling between sender and receiver applications allows for greater flexibility and scalability in the system.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. can enhance Redis by handling management tasks, backups, and scalability, facilitating global reach and easy cloud integration for global businesses.
Strategic allocation of these resources plays a crucial role in achieving scalability, cost savings, improved performance, and staying ahead of advancements in the field. This also aids scalability down the line. Just like a conductor orchestrating an ensemble of instruments to play at specific times for optimal performance.
At its heart it uses Istio (for traffic control) and Knative (for event driven tool orchestration) and stores all configuration in Git – following the GitOps approach. Pitometer is used to validate a deployment after it was successfully tested based on the defined testing strategy. It takes your artifacts (e.g:
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content