This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
In Kubernetes , Ingress resources are frequently used as traffic controllers, providing external access to services within the cluster. This blog post will walk you through the process of blocking your site's indexing on Kubernetes Ingress using robots.txt file, preventing search engine bots from crawling and indexing your content.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience.
What’s the problem with Black Friday traffic? But that’s difficult when Black Friday traffic brings overwhelming and unpredictable peak loads to retailer websites and exposes the weakest points in a company’s infrastructure, threatening application performance and user experience. Why Black Friday traffic threatens customer experience.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
API resilience is about creating systems that can recover gracefully from disruptions, such as network outages or sudden traffic spikes, ensuring they remain reliable and secure. However, it often introduces new challenges in the process. This has become critical since APIs serve as the backbone of todays interconnected systems.
Turnkey cluster overload protection with adaptive traffic management and control. By vastly increasing the number of PurePaths that are processed by a Dynatrace Managed cluster, your initial sizing considerations for Dynatrace Managed nodes and clusters may however end up being inadequate for supporting such volume.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. Actions resulting from the evaluation The certification process surfaced a few recommendations for improving the app.
As Netflix expanded globally and the volume of title launches skyrocketed, the operational challenges of maintaining this manual process became undeniable. Metadata and assets must be correctly configured, data must flow seamlessly, microservices must process titles without error, and algorithms must function as intended.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
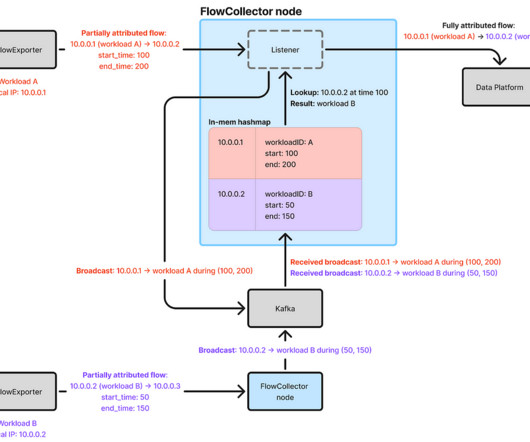
FlowCollector , a backend service, collects flow logs from FlowExporter instances across the fleet, attributes the IP addresses, and sends these attributed flows to Netflixs Data Mesh for subsequent stream and batch processing. 2xlarge instances, we can process 5 million flows per second across the entire Netflixfleet. With 30 c7i.2xlarge
Our "serverless" order processing system built on AWS Lambda and API Gateway was humming along, handling 1,000 transactions/minute. A sudden spike in traffic caused Lambda timeouts, API Gateway threw 5xx errors, and customers started tweeting, Why cant I check out?! Then, disaster struck.
FortiGate traffic logs store data elements in key-value pairs while NGINX custom access logs store events in arrays. Advanced processing on your observability platform unlocks the full value of log data. Advanced processing on your observability platform unlocks the full value of log data.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
Accurately Reflecting Production Behavior A key part of our solution is insights into production behavior, which necessitates our requests to the endpoint result in traffic to the real service functions that mimics the same pathways the traffic would take if it came from the usualcallers. We call this capability TimeTravel.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
Event Prioritization Considering the use cases were wide ranging both in terms of their sources and their importance, we built segmentation into the event processing. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
While most government agencies and commercial enterprises have digital services in place, the current volume of usage — including traffic to critical employment, health and retail/eCommerce services — has reached levels that many organizations have never seen before or tested against. So how do you know what to prepare for?
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
Even when the staging environment closely mirrors the production environment, achieving a complete replication of all potential scenarios, such as simulating extremely high traffic volumes to assess software performance, remains challenging. This can lead to a lack of insight into how the code will behave when exposed to heavy traffic.
It’s also critical to have a strategy in place to address these outages, including both documented remediation processes and an observability platform to help you proactively identify and resolve issues to minimize customer and business impact. These attacks can be orchestrated by hackers, cybercriminals, or even state actors.
This becomes even more challenging when the application receives heavy traffic, because a single microservice might become overwhelmed if it receives too many requests too quickly. Management processes make up the control plane, which coordinates the proxies’ behavior. Why do you need a service mesh?
In this article, we’ll dive deep into the concept of database sharding, a critical technique for scaling databases to handle large volumes of data and high levels of traffic. This section will provide insights into the architecture and strategies to ensure efficient query processing in a sharded environment.
Your next challenge is ensuring your DevOps processes, pipelines, and tooling meet the intended goal. For example, by measuring deployment frequency daily or weekly, you can determine how efficiently your team is responding to process changes. Lead time for changes helps teams understand how effective their processes are.
With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control. OneAgent implements network zones to create traffic routing rules and limit cross data-center traffic. Upgrade OpenTracing instrumentation with high-fidelity data provided by OneAgent.
Cloud migration is the process of transferring some or all your data, software, and operations to a cloud-based computing environment that offers unlimited scale and high availability. A key step in digital transformation is migrating from traditional on-prem IT processes to adopting cloud services. What is cloud migration?
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. Logs and background requests are examples of this type of traffic.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Detect and respond to security threats like DDoS attacks or web application attacks by monitoring application traffic and logs.
Open vulnerability on process group: The total number of currently high-profile vulnerabilities related to a process group. Vulnerability score: The highest vulnerability risk score for a process group. This way, the travel agency can easily streamline, organize, and consolidate their quality gates and metric evaluation process.
This article delves deep into the essence of Istio, illustrating its pivotal role in a Kubernetes (KIND) based environment, and guides you through a Helm-based installation process, ensuring a comprehensive understanding of Istio's capabilities and its impact on microservices architecture.
Response time Response time refers to the total time it takes for a system to process a request or complete an operation. This ensures that customers can quickly navigate through product listings, add items to their cart, and complete the checkout process without experiencing noticeable delays. or above for the checkout process.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Improved Vacuuming: A redesigned memory structure lowers resource use and speeds up the vacuum process.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
Scanning the runtime environment of your services can help to identify unusual network traffic patterns. For example, you can detect traffic from outside your network going to a server that normally receives traffic from internal servers. The vulnerability management process. Timely detection.
To ensure high standards, it’s essential that your organization establish automated validations in an early phase of the software development process—ideally when code is written. While the first guardian validates the traffic, the second guardian checks the business transactions generated during the observation period.
Google has a pretty tight grip on the tech industry: it makes by far the most popular browser with the best DevTools, and the most popular search engine, which means that web developers spend most of their time in Chrome, most of their visitors are in Chrome, and a lot of their search traffic will be coming from Google. Why This Is a Problem.
With its ability to handle large amounts of traffic and complex data, the Apollo router is quickly becoming a popular choice among developers seeking a reliable and efficient routing solution. This self-hosted graph routing solution is highly configurable, making it an ideal choice for developers who require a high-performance routing system.
With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control. OneAgent implements network zones to create traffic routing rules and limit cross-data-center traffic. Our OneAgent OpenTelemetry for Go integration currently focuses on capturing and enrichment of in-process spans.
With the pace of digital transformation continuing to accelerate, organizations are realizing the growing imperative to have a robust application security monitoring process in place. Incident detection and response In the event of a security incident, there is a well-defined incident response process to investigate and mitigate the issue.
In addition to being available as metrics in custom charts , you can view these metrics at the process group instance level in the Dynatrace web UI. Aggregated connection pool metrics are available on the process group overview page. A Davis detected problem identifies an increase in traffic as a possible root cause.
These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success. Generally, response times measure the total duration of receiving, processing, and completing a request. One template explicitly targets service performance monitoring.
Digitizing internal processes can improve information flow and enhance collaboration among employees. However, digital transformation requires significant investment in technology infrastructure and processes. Previously, they had 12 tools with different traffic thresholds. Enhanced business operations.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content