This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
Multimodal data processing is the evolving need of the latest data platforms powering applications like recommendation systems, autonomous vehicles, and medical diagnostics. Handling multimodal data spanning text, images, videos, and sensor inputs requires resilient architecture to manage the diversity of formats and scale.
Business processes support virtually all aspects of an organizations operations. Theyre often categorized by their function; core processes directly create customer value, support processes increase departmental efficiency, and management processes drive strategic goals and compliance.
In fact, observability is essential for shaping how we design smarter, more resilient systems for the future. As an open-source project, OpenTelemetry sets standards for telemetry data sets and works with a wide range of systems and platforms to collect and export telemetry data to backend systems. milestone.
There’s a goldmine of business data traversing your IT systems, yet most of it remains untapped. Other data sources, including APIs and log files — are used to expand access, often to external or proprietary systems. Dynatrace OpenPipeline is a new stream processing technology that ingests and contextualizes data from any source.
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Failures in a distributed system are a given, and having the ability to safely retry requests enhances the reliability of the service.
The Federal Reserve Regulation HH in the United States focuses on operational resilience requirements for systemically important financial market utilities. Carefully planning and integrating new processes and tools is critical to ensuring compliance without disrupting daily operations.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. On the other hand, these optimizations themselves need to be sufficiently inexpensive to justify their own processing cost over the gains they bring.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems.
The Grail™ data lakehouse provides fast, auto-indexed, schema-on-read storage with massively parallel processing (MPP) to deliver immediate, contextualized answers from all data at scale. Through Azure Native Dynatrace Service, customers can seamlessly adopt these technologies to modernize and enhance their cloud operations.
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. Log analytics, on the other hand, is the process of using the gathered logs to extract business or operational insight.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Messaging systems can significantly improve the reliability, performance, and scalability of the communication processes between applications and services. In serverless and microservices architectures, messaging systems are often used to build asynchronous service-to-service communication. Dynatrace news.
One main advantage of using a product in SaaS mode is the automatic scaling of resources based on system load. Using existing storage resources optimally is key to being able to capture the right data over time. Increased storage space availability. Compression of data that’s older than three days utilizes one virtual CPU.
A distributed storagesystem is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. Actions resulting from the evaluation The certification process surfaced a few recommendations for improving the app.
To achieve this, we are committed to building robust systems that deliver comprehensive observability, enabling us to take full accountability for every title on ourservice. Each title represents countless hours of effort and creativity, and our systems need to honor that uniqueness. Yet, these pages couldnt be more different.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. The MPP system leverages a shared-nothing architecture to handle multiple operations in parallel.
This article analyzes the correlation between block sizes and their impact on storage performance. This paper deals with definitions and understanding of structured data vs unstructured data, how various storage segments react to block size changes, and differences between I/O-driven and throughput-driven workloads.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Performance Optimizations PostgreSQL 17 significantly improves performance, query handling, and database management, making it more efficient for high-demand systems.
The streaming data store makes the system extensible to support other use-cases (e.g. System Components. The system will comprise of several micro-services each performing a separate task. There are two major processes which gets executed when a user posts a photo on Instagram. Fetching User Feed.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storagesystems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
We accomplish this by paving the path to: Accessing and processing media data (e.g. To streamline this process, we standardized media assets with pre-processing steps that create and store dedicated quality-controlled derivatives with associated snapshotted metadata.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
By Xiaomei Liu , Rosanna Lee , Cyril Concolato Introduction Behind the scenes of the beloved Netflix streaming service and content, there are many technology innovations in media processing. Packaging has always been an important step in media processing. Uploading and downloading data always come with a penalty, namely latency.
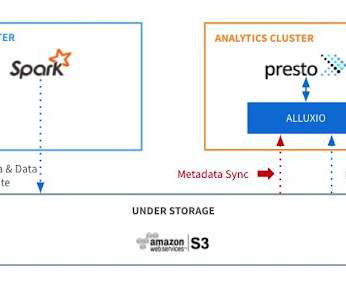
Metadata synchronization (sync) is a core feature in Alluxio that keeps files and directories consistent with their source of truth in under-storagesystems, thus making it simple for users to reason the data retrieved from Alluxio. Meanwhile, understanding the internal process is important in order to tune the performance.
With the latest advances from Dynatrace, this process is instantaneous. That’s because it does not require any pre-prepared schemas, and access to cold/hot storage is fully automatic and with zero latency. Moreover, it is fast, powered by its massively parallel processing data lakehouse.
which is difficult when troubleshooting distributed systems. Reconstructing a streaming session was a tedious and time consuming process that involved tracing all interactions (requests) between the Netflix app, our Content Delivery Network (CDN), and backend microservices. Stream Processing: to sample or not to sample trace data?
Our company uses artificial intelligence (AI) and machine learning to streamline the comparison and purchasing process for car insurance and car loans. But this also caused storage challenges like disk failures and data recovery. To avoid extensive maintenance, we adopted JuiceFS, a distributed file system with high performance.
Application and system logs are often collected in data silos using different tools, with no relationships between them, and then correlated in manual and often meaningless ways. Each process could generate multiple log entries, adding up to terabytes of data every day. Clearly, this works against the goal of digital transformation.
This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storagesystems (which are used by data lakes). This decoupling ensures the openness of data and storage formats, while also preserving data in context. Ingest and process with Grail.
Operating Systems are not always set up in the same way. Storage mount points in a system might be larger or smaller, local or remote, with high or low latency, and various speeds. Starting with OneAgent version 1.199, the runtime folder is configurable and consequently you can retain your storage mount point setup as-is.
Log analytics is the process of viewing, interpreting, and querying log data so developers and IT teams can quickly detect and resolve application and system issues. Cold storage and rehydration. Cold storage and rehydration. This can vastly reduce an organization’s storage costs and improve data efficiency.
Information related to user experience, transaction parameters, and business process parameters has been an unretrieved treasure, now accessible through new and unique AI-powered contextual analytics in Dynatrace. Lack of visibility into business processes to improve, optimize, and remediate issues and systems harms business success.
Often times an external system is providing data as JSON, so it might be a temporary store before data is ingested into other parts of the system. JSON is faster to ingest vs. JSONB – however, if you do any further processing, JSONB will be faster. JSONB storage results in a larger storage footprint.
Log analytics is the process of viewing, interpreting, and querying log data so developers and IT teams can quickly detect and resolve application and system issues. Cold storage and rehydration. Cold storage and rehydration. This can vastly reduce an organization’s storage costs and improve data efficiency.
User provides a sample image to find other similar images Prior engineering work Approach #1: on-demand batch processing Our first approach to surface these innovations was a tool to trigger these algorithms on-demand and on a per-show basis. Processing took several hours to complete. Maintaining disparate systems posed a challenge.
Therefore, they need an environment that offers scalable computing, storage, and networking. Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. What is hyperconverged infrastructure?
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
Data processing in the cloud has become increasingly popular due to its scalability, flexibility, and cost-effectiveness. This article will explore how these technologies can be used together to create an optimized data pipeline for data processing in the cloud.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content