This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
Multimodal data processing is the evolving need of the latest data platforms powering applications like recommendation systems, autonomous vehicles, and medical diagnostics. Handling multimodal data spanning text, images, videos, and sensor inputs requires resilient architecture to manage the diversity of formats and scale.
Simplify data ingestion and up-level storage for better, faster querying : With Dynatrace, petabytes of data are always hot for real-time insights, at a cold cost. Worsened by separate tools to track metrics, logs, traces, and user behaviorcrucial, interconnected details are separated into different storage.
Business processes support virtually all aspects of an organizations operations. Theyre often categorized by their function; core processes directly create customer value, support processes increase departmental efficiency, and management processes drive strategic goals and compliance.
Efficient data processing is crucial for businesses and organizations that rely on big data analytics to make informed decisions. One key factor that significantly affects the performance of data processing is the storage format of the data.
In today's data-driven world, efficient data processing plays a pivotal role in the success of any project. Apache Spark , a robust open-source data processing framework, has emerged as a game-changer in this domain. Optimizing Data Input Make Use of Data Forma t In most cases, the data being processed is stored in a columnar format.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. On the other hand, these optimizations themselves need to be sufficiently inexpensive to justify their own processing cost over the gains they bring.
By ensuring that all processes—from data collection to storage and usage—comply with regulatory requirements, organizations can better manage potential threats. Streamlined audits: End-to-end compliance simplifies the audit process. Retention periods and access controls must be properly configured to protect such PII.
Using existing storage resources optimally is key to being able to capture the right data over time. Increased storage space availability. The compression of transaction data older than three days can free up to 50% more storage space in your Dynatrace Managed Cluster. Data compression is completed on June 12.
Dynatrace OpenPipeline is a new stream processing technology that ingests and contextualizes data from any source. Business process monitoring and optimization. All of these steps are critical components of the process, likely to be implemented using different systems. Reduced storage and query overhead for business use cases.
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Let’s examine some of the drawbacks of this approach: Lack of Idempotency : There is no idempotency key baked into the storage data-model preventing users from safely retrying requests.
Finally, it empowers automated systems to process and analyze OpenTelemetry data, without requiring adaptations for every framework. Acting as the middlemen, Collectors hide all the pesky little details, allowing OpenTelemetry exporters to focus on generating data, and OpenTel backends to focus on storage and analysis.
Carefully planning and integrating new processes and tools is critical to ensuring compliance without disrupting daily operations. Visibility of all business processes starting from the back end and ending with customer experience is perhaps the biggest challenge. Were challenging these preconceptions.
In today's data-driven world, organizations need efficient and scalable data pipelines to process and analyze large volumes of data. Medallion Architecture provides a framework for organizing data processing workflows into different zones, enabling optimized batch and stream processing.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing.
By vastly increasing the number of PurePaths that are processed by a Dynatrace Managed cluster, your initial sizing considerations for Dynatrace Managed nodes and clusters may however end up being inadequate for supporting such volume. A Dynatrace Managed cluster may lack the necessary hardware to process all the additional incoming data.
A lack of automation and standardization often results in a labour-intensive process across post-production and VFX with a lot of dependencies that introduce potential human errors and security risks. Besides the need for robust cloud storage for their media, artists need access to powerful workstations and real-time playback.
The Grail™ data lakehouse provides fast, auto-indexed, schema-on-read storage with massively parallel processing (MPP) to deliver immediate, contextualized answers from all data at scale. Through Azure Native Dynatrace Service, customers can seamlessly adopt these technologies to modernize and enhance their cloud operations.
This article analyzes the correlation between block sizes and their impact on storage performance. This paper deals with definitions and understanding of structured data vs unstructured data, how various storage segments react to block size changes, and differences between I/O-driven and throughput-driven workloads.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ?
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. Actions resulting from the evaluation The certification process surfaced a few recommendations for improving the app.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Use cases Identifying misconfigurations: Continuously scanning cloud environments to detect misconfigurations (such as open network ports, missing security patches, and exposed storage buckets) to help maintain a secure, stable infrastructure. What is Kubernetes Security Posture Management?
Say hello to advanced trace an alytics and new data storage and capture options. Site reliability engineers, performance architects, and developers can now leverage dynamic analysis tools like dashboards and workflows to explore trends, automate processes, and maintain control at an unprecedented level. But why stop there?
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
There are two major processes which gets executed when a user posts a photo on Instagram. Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
As Netflix expanded globally and the volume of title launches skyrocketed, the operational challenges of maintaining this manual process became undeniable. Metadata and assets must be correctly configured, data must flow seamlessly, microservices must process titles without error, and algorithms must function as intended.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Improved Vacuuming: A redesigned memory structure lowers resource use and speeds up the vacuum process.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
Masking at storage: Data is persistently masked upon ingestion into Dynatrace. Leverage three masking layers Masking at capture and masking at storage operations exclude targeted sensitive data points. The selected rules can be configured for a whole environment or, more granularly, for specific process groups.
JSON is faster to ingest vs. JSONB – however, if you do any further processing, JSONB will be faster. JSONB storage has some drawbacks vs. traditional columns: PostreSQL does not store column statistics for JSONB columns. JSONB storage results in a larger storage footprint. whitespace) and ordering of the keys.
Data migration is the process of moving data from one location to another, which is an essential aspect of cloud migration. Data migration involves transferring data from on-premise storage to the cloud. With the rapid adoption of cloud computing , businesses are moving their IT infrastructure to the cloud.
Introduction With big data streaming platform and event ingestion service Azure Event Hubs , millions of events can be received and processed in a single second. Any real-time analytics provider or batching/storage adaptor can transform and store data supplied to an event hub.
With the latest advances from Dynatrace, this process is instantaneous. That’s because it does not require any pre-prepared schemas, and access to cold/hot storage is fully automatic and with zero latency. Moreover, it is fast, powered by its massively parallel processing data lakehouse.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storage systems (which are used by data lakes). This decoupling ensures the openness of data and storage formats, while also preserving data in context. Ingest and process with Grail. Retain data.
If country_iso_code doesnt already exist in the fact table, the metric owner only needs to tell DJ that account_id is the foreign key to an `users_dimension_table` (we call this process dimension linking ). DJ then can perform the joins to bring in any requested dimensions from `users_dimension_table`.
When dealing with IoT, one of the first things that come to mind is the limited processing, networking, and storage capabilities these devices operate with. A messaging protocol is a set of rules and formats that are agreed upon among entities that want to communicate with each other.
By Xiaomei Liu , Rosanna Lee , Cyril Concolato Introduction Behind the scenes of the beloved Netflix streaming service and content, there are many technology innovations in media processing. Packaging has always been an important step in media processing. Uploading and downloading data always come with a penalty, namely latency.
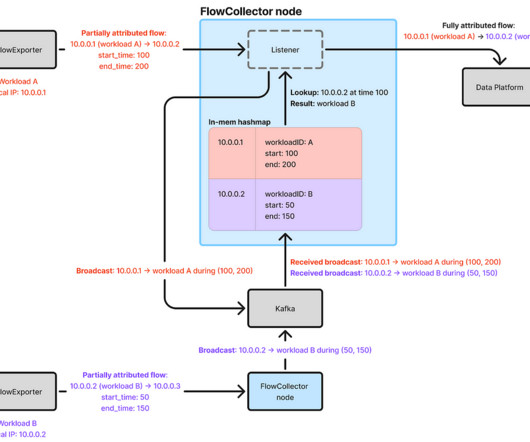
FlowCollector , a backend service, collects flow logs from FlowExporter instances across the fleet, attributes the IP addresses, and sends these attributed flows to Netflixs Data Mesh for subsequent stream and batch processing. 2xlarge instances, we can process 5 million flows per second across the entire Netflixfleet. With 30 c7i.2xlarge
Data warehouses offer a single storage repository for structured data and provide a source of truth for organizations. However, organizations must structure and store data inputs in a specific format to enable extract, transform, and load processes, and efficiently query this data. Massively parallel processing. Query language.
We accomplish this by paving the path to: Accessing and processing media data (e.g. To streamline this process, we standardized media assets with pre-processing steps that create and store dedicated quality-controlled derivatives with associated snapshotted metadata. either a movie or an episode within a show). mp4, clip1.mp4,
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content