This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. Software development is often at the center of this speed-quality tradeoff. Automating DevOps practices boosts development speed and code quality.
In an attempt to hold their place within the market, developers are having to speed their process up whilst delivering products of ever-increasing quality. Often speed and quality seem at odds with one another, but in reality, this isn’t the case. In 2019, according to Evans Data Corporation, there were 23.9
Dynatrace on Microsoft Azure allows enterprises to streamline deployment, gain critical insights, and automate manual processes. This local SaaS presence minimizes latency and maximizes the speed and reliability of data access. The result? Optimized performance and enhanced customer experiences.
While increasing both the precision and the recall of our secrets detection engine, we felt the need to keep a close eye on speed. In a gearbox, if you want to increase torque, you need to decrease speed. So it wasn’t a surprise to find that our engine had the same problem: more power, less speed.
The Grail™ data lakehouse provides fast, auto-indexed, schema-on-read storage with massively parallel processing (MPP) to deliver immediate, contextualized answers from all data at scale. Through Azure Native Dynatrace Service, customers can seamlessly adopt these technologies to modernize and enhance their cloud operations.
Dynatrace transforms this unstructured data into a strategic advantage, processing it automatically—no manual tagging required. By automating root-cause analysis, TD Bank reduced incidents, speeding up resolution times and maintaining system reliability. With over 2.5 The result?
Break data silos and add context for faster, more strategic decisions Data silos : When every team adopts their own toolset, organizations wind up with different query technologies, heterogeneous datatypes, and incongruous storage speeds.
Carefully planning and integrating new processes and tools is critical to ensuring compliance without disrupting daily operations. Visibility of all business processes starting from the back end and ending with customer experience is perhaps the biggest challenge.
Open vulnerability on process group: The total number of currently high-profile vulnerabilities related to a process group. Vulnerability score: The highest vulnerability risk score for a process group. This way, the travel agency can easily streamline, organize, and consolidate their quality gates and metric evaluation process.
Easily track threat-hunting twists and turns Threat hunting is a nonlinear process. Character precision on a petabyte scale Security Investigator increases the speed of investigation flows and the precision of evidence, leading to higher efficiency and faster results. Use filtering to narrow down results and focus your research.
The best thing: the whole process is performed on read when the query is executed, which means you have full flexibility and don’t need to define a structure when ingesting data. >> DPL Architect enables you to quickly create DPL patterns, speeding up the investigation flow and delivering faster results.
This shift is driving increased adoption of the Dynatrace platform, as our customers leverage our unified observability solutionpowered by Grail, our hyperscale data lakehouse, designed to store, process, and query massive volumes of observability, security, and business data with high efficiency and speed.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
A lack of automation and standardization often results in a labour-intensive process across post-production and VFX with a lot of dependencies that introduce potential human errors and security risks. The system facilitates large volumes of camera and sound media and is built for speed.
After optimizing containerized applications processing petabytes of data in fintech environments, I've learned that Docker performance isn't just about speed it's about reliability, resource efficiency, and cost optimization. Let's dive into strategies that actually work in production.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Incremental Backups: Speeds up recovery and makes data management more efficient for active databases.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
In the fourteen years that I've been working in the web performance industry, I've done a LOT of research, writing, and speaking about the psychology of page speed – in other words, why we crave fast, seamless online experiences. In fairness, that was in the early 2000s, and site speed was barely on anyone's radar.
It's time to automate you testing process! DZone Refcard: Automated Testing: Improving Application Speed and Quality — Learn more about mobile testing in Kotlin, go beyond what Selenium provides for web application testing, and take a deep dive into trends such as Behavioral-Driven Development and Visual Regression.
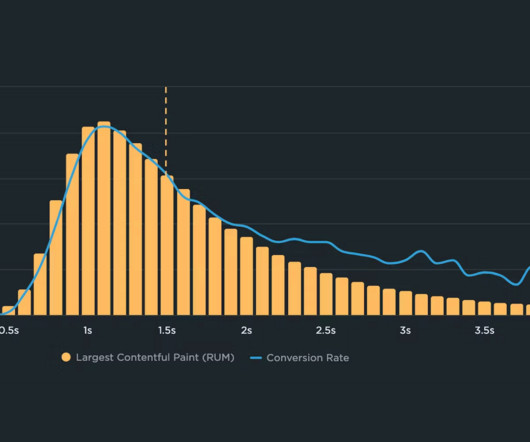
If you could measure the impact of site speed on your business, how valuable would that be for you? Here's the truth: The business folks in your organization probably don't care about page speed metrics. But that doesn't mean they don't care about page speed. Say hello to correlation charts – your new best friend.
Our latest enhancements to the Dynatrace Dashboards and Notebooks apps make learning DQL optional in your day-to-day work, speeding up your troubleshooting and optimization tasks. Kickstarting the dashboard creation process is, however, just one advantage of ready-made dashboards.
Efficient data processing is crucial for businesses and organizations that rely on big data analytics to make informed decisions. One key factor that significantly affects the performance of data processing is the storage format of the data.
Factors like read and write speed, latency, and data distribution methods are essential. But if your application primarily revolves around batch processing of large datasets, then focusing on write speed could mislead your selection process. Yet, they are often evaluated in isolation, removed from the business context.
In order for software development teams to balance speed with quality during the software development cycle (SDLC), development, security, and operations teams (or DevSecOps teams) need to ensure that their practices align with modern cloud environments. That can be difficult when the business climate can prioritize speed.
This is a scenario that is common in data processing applications running in Hadoop or Spark clusters. Given the size of these files, you can be looking at significant differences in parsing speed between libraries. We often don’t think about the JSON libraries we use, but there are some differences between them.
Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. Using a low-code visual workflow approach, organizations can orchestrate key services, automate critical processes, and create new serverless applications. Improving data processing.
In today’s rapidly evolving business and technology landscape, organizations often prioritize the speed of development over security. Modern solutions like Snyk and Dynatrace offer a way to achieve the speed of modern innovation without sacrificing security. Try Dynatrace and Snyk for free or purchase on the AWS Marketplace.
The DevOps playbook has proven its value for many organizations by improving software development agility, efficiency, and speed. This method known as GitOps would also boost the speed and efficiency of practicing DevOps organizations. GitOps improves speed and scalability. Dynatrace news. What is GitOps?
Cloud-native environments bring speed and agility to software development and operations (DevOps) practices. But with that speed and agility comes new complications and complexity, all while maintaining performance and reliability with less than 1% down-time per year. Both practices live by the same overarching tenets. Reduced latency.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing.
The key to upgrading an observability platform is to increase data processingspeed and reduce costs. However, I might have gone too far with that metaphor, because till these days, we have never invented a system as sophisticated as the human body, but we can always make advancements. This is based on two reasons:
The demand for faster, more reliable, and efficient testing processes has grown exponentially with the increasing complexity of modern applications. For more: Read the Report Artificial intelligence (AI) has revolutionized the realm of software testing, introducing new possibilities and efficiencies.
Multicloud automation challenge: Manual processes don’t scale Manual processes pose multiple problems for organizations looking for increased application performance and efficiency. First, manual processes are naturally error prone because they rely on humans to input, review, and confirm data. Consider security incidents.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
The goal is to help developers, technical managers, and business owners understand the importance of API performance optimization and how they can improve the speed, scalability, and reliability of their APIs. API performance optimization is the process of improving the speed, scalability, and reliability of APIs.
The scale and speed of the program triggered challenges for these banks that they had never before imagined. Speed up loan processing to deliver critically needed relief to small businesses? Full speed ahead. How can we… Scale to previously unheard-of loan volumes? Adapting to change. Jumpstart your transformation.
Overcoming the barriers presented by legacy security practices that are typically manually intensive and slow, requires a DevSecOps mindset where security is architected and planned from project conception and automated for speed and scale throughout where possible. Challenge: Monitoring processes for anomalous behavior.
“As code” means simplifying complex and time-consuming tasks by automating some, or all, of their processes. In turn, IAC offers increased deployment speed and cross-team collaboration without increased complexity. But this increased speed can’t come at the expense of control, compliance, and security.
We’re able to help drive speed, take multiple data sources, bring them into a common model and drive those answers at scale.”. Ability to create custom metrics and events from log data, extending Dynatrace observability to any application, script or process. We’ve seen a doubling of Kubernetes usage in the past six months,” Steve said.
Using vulnerability management, DevSecOps automation, and attack detection and blocking in your application security process can proactively improve your organization’s overall security posture. Vulnerability management Vulnerability management is the process of identifying, prioritizing, rectifying, and reporting software vulnerabilities.
In this post, I’m going to break these processes down into each of: ? Connection One thing we haven’t looked at is the impact of network speeds on these outcomes. Larger files compress much more effectively and thus download faster at all connection speeds. The former makes for a simpler build step, but is it faster?
A data lakehouse features the flexibility and cost-efficiency of a data lake with the contextual and high-speed querying capabilities of a data warehouse. However, organizations must structure and store data inputs in a specific format to enable extract, transform, and load processes, and efficiently query this data. Data management.
Staying ahead of customer needs requires speed and agility from all phases of the software development life cycle (SDLC). DevOps automation tools speed up delivery cycles by reducing human error and bottlenecks, resulting in fewer and shorter feedback loops. It helps to assess the long- and short-term efficiency and speed of DevOps.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content