This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, we’re excited to present the Distributed Counter Abstraction. In this context, they refer to a count very close to accurate, presented with minimal delays. After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods.
The Grail™ data lakehouse provides fast, auto-indexed, schema-on-read storage with massively parallel processing (MPP) to deliver immediate, contextualized answers from all data at scale. However, data overload and skills shortages present challenges that companies need to address to maximize the benefits of cloud and AI technologies.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. On the other hand, these optimizations themselves need to be sufficiently inexpensive to justify their own processing cost over the gains they bring.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
As Netflix expanded globally and the volume of title launches skyrocketed, the operational challenges of maintaining this manual process became undeniable. Metadata and assets must be correctly configured, data must flow seamlessly, microservices must process titles without error, and algorithms must function as intended.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ?
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Improved Vacuuming: A redesigned memory structure lowers resource use and speeds up the vacuum process. JSON_QUERY extracts JSON fragments based on query conditions.
As a result, requests are uniformly handled, and responses are processed cohesively. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. This centralized format, defined and maintained by our team, ensures all endpoints adhere to a consistent protocol.
Observability data presents executives with new opportunities to achieve this, by creating incremental value for cloud modernization , improved business analytics , and enhanced customer experience. With the latest advances from Dynatrace, this process is instantaneous. This is inefficient and creates avoidable risks.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
We accomplish this by paving the path to: Accessing and processing media data (e.g. We accomplish this by paving the path to: Accessing and processing media data (e.g. We will then present a case study of using these components in order to optimize, scale, and solidify an existing pipeline.
Note: If a particular key is always present in your document, it might make sense to store it as a first class column. JSON is faster to ingest vs. JSONB – however, if you do any further processing, JSONB will be faster. JSONB storage results in a larger storage footprint. whitespace) and ordering of the keys.
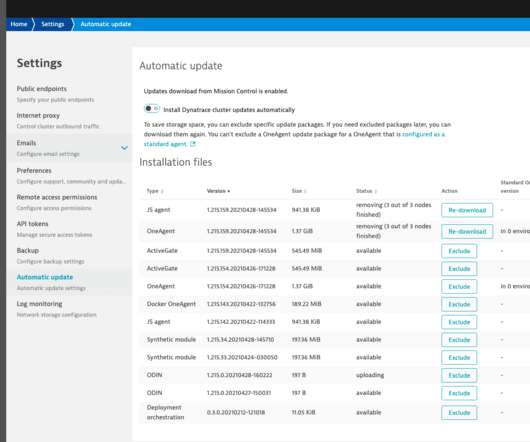
OneAgent processes rules precisely in this order, with host scope rules processed before host group and tenant scope rules. If a more granular rule is present on the host level, that rule will precede any blanket rule on, for example, the tenant level. Host group. Try it out yourself.
Log analytics is the process of viewing, interpreting, and querying log data so developers and IT teams can quickly detect and resolve application and system issues. At the same time, log analytics can present challenges as data volumes explode, particularly in traditional environments that lack end-to-end observability solutions.
Log analytics is the process of viewing, interpreting, and querying log data so developers and IT teams can quickly detect and resolve application and system issues. At the same time, log analytics can present challenges as data volumes explode, particularly in traditional environments that lack end-to-end observability solutions.
These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Cloud storage monitoring. Cloud monitoring types and how they work.
I wanted to present as much information as possible. Before we dive into the technical implementation, let me explain the visual concept of this “Global Status Page”: Another requirement for this status page was that it has to be lightweight, with no data storage at all. Real-time problem visualization of lots of environments.
But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Each process could generate multiple log entries, adding up to terabytes of data every day. Traditionally, teams struggle to centralize all these data silos through the process of indexing.
Secondly, determining the correct allocation of resources (CPU, memory, storage) to each virtual machine to ensure optimal performance without over-provisioning can be difficult. This presents a challenge for IT operations teams, specifically in identifying and addressing performance issues or planning how to prevent future issues.
Track changes via our change management process. Every storage location involving data at rest is encrypted as well. The signatures are automatically verified during the update process on the customer infrastructure. The security controls presented above are audited on an annual basis by independent security assessors.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) joins) during query processing.
Our partner community plays a vital role in facilitating this transition by effectively communicating the benefits of SaaS and ensuring a seamless migration process. Dynatrace SaaS presents a lower total cost of ownership (TCO), enabling customers to consolidate various tools, thereby optimizing costs and enhancing internal user experiences.
Edgar helps Netflix teams troubleshoot distributed systems efficiently with the help of a summarized presentation of request tracing, logs, analysis, and metadata. When a problem occurs, we put on our detective hats and start our mystery-solving process by gathering evidence. by Elizabeth Carretto Everyone loves Unsolved Mysteries.
Data volumes are growing all the time, making it harder to orchestrate, process, and analyze to turn information into insight. Data scale and silos present challenges to DevOps maturity DevOps teams often run into problems trying to drive better data-driven decisions with observability and security data. What is DevOps maturity?
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as data warehouse tables in AWS S3.
Building on the success of DevOps practices, GitOps is a relatively new way to manage infrastructure through code and automation, around a single Git repository (or a storage system for all the changes and files that relate to a given project). These practices can be a boon to infrastructure management, but GitOps presents challenges.
Our previous blog post presented replay traffic testing — a crucial instrument in our toolkit that allows us to implement these transformations with precision and reliability. A process that doesn’t just minimize risk, but also facilitates a continuous evaluation of the rollout’s impact.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. While it is powerful, it presents several challenges that affect its adoption. This blog post explores the Reliability metric , which measures modern operational practices. Why reliability?
Contact Dynatrace ONE if you wish to enable Cluster-side screenshot storage on pre-1.216 fresh-installed Clusters. To better present default values, we changed the position of session replay permissions in group details page. . Consumption and storage now returned correctly when using Environment API with paging. APM-290353).
We present two sets. On the other hand, the optimized ladder presents a sharper increase in quality with increasing bitrate. In spite of reaching higher qualities than the fixed ladder, the HDR-DO ladder, on average, occupies only 58% of the storage space compared to fixed-bitrate ladder. The first set (Fig.
In a distributed processing environment, message queuing is similar, although the speed and volume of messages are much greater. A producer creates the message, and a consumer processes it. Consumers store messages in a queue — usually in a buffer or on a storage medium — until they can process and delete them.
In a distributed processing environment, message queuing is similar, although the speed and volume of messages are much greater. A producer creates the message, and a consumer processes it. Consumers store messages in a queue — usually in a buffer or on a storage medium — until they can process and delete them.
However, storing and querying such data presents a unique set of challenges: High Throughput : Managing up to 10 million writes per second while maintaining high availability. Storage Layer The storage layer for TimeSeries comprises a primary data store and an optional index data store. Note : With Cassandra 4.x
Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. A platform approach, on the other hand, presents a more effective option for understanding observability as a whole. In this case, the best option may be to stop the process and execute it when system load is low.
The immense growth of Kubernetes presents new security challenges in runtime and increased complexity in hardening CI/CD pipelines in development. Redis is an in-memory key-value store and cache that simplifies processing, storage, and interaction with data in Kubernetes environments.
” But, he continues, ” Today’s environments present a completely different picture. They need to automate manual tasks, streamline processes, and invest in new technologies. And according to 451 Research, 83% of organizations plan to adapt their monitoring process. during 2021–2026.
With Amazon Web Services, the main sources from which to ingest logs—Simple Storage Service, or S3, and CloudWatch —come with an additional cost. Processing logs is now streamlined, enabling customers to enrich log metadata with insightful context that is important for delivering pipelines to single Firehose delivery streams.
This new service enhances the user visibility of network details with direct delivery of Flow Logs for Transit Gateway to your desired endpoint via Amazon Simple Storage Service (S3) bucket or Amazon CloudWatch Logs. A feature that enables you to present log data in a filterable table that is easy to work with. Why Dynatrace?
Among these, you can find essential elements of application and infrastructure stacks, from app gateways (like HAProxy), through app fabric (like RabbitMQ), to databases (like MongoDB) and storage systems (like NetApp, Consul, Memcached, and InfluxDB, just to name a few). Customizable dashboard. Specialized Unified Analysis page.
Grail handles data storage, data management, and processes data at massive speed, scale, and cost efficiency,” Singh said. Davis enables users to go deeper into the details of the underlying processes running on a particular host. An overview of the Dynatrace unified observability and security platform. This is Davis CoPilot.
In the keynote by Christina Yakomin and Steve Prazenica from Vanguard, the presenters recounted their journey from a monolith with alert-based incident reporting and no positive health signals to an observable microservice architecture. Trace-based sampling can help you save storage costs.
Logs are presented in the context of the applications that generate them, with the capability to run queries and open queried log entries directly in the Logs app. Even more importantly, how was the error handled, and did the process end successfully for the customer?
I wonder if any of my code is still present in todays Netflixapps?) At some point a storage cupboard was taken over with a combination lock on the door, no-one was allow to ask or discuss what was going on, as Apple insisted on absolute secrecy. It worked really well as a stress test, and the launch had noissues.
Edge computing has transformed how businesses and industries process and manage data. Data Overload and Storage Limitations As IoT and especially industrial IoT -based devices proliferate, the volume of data generated at the edge has skyrocketed. Key issues include: Limited storage capacity on edge devices.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content