This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This three-part article series will take you through the process of developing a network anomaly detection system using the Spring Boot framework in a robust manner. The series is organized as follows: Part 1: We’ll concentrate on the foundation and basic structure of our detection system, which has to be created.
Today, we’re excited to present the Distributed Counter Abstraction. In this context, they refer to a count very close to accurate, presented with minimal delays. Introducing sufficient jitter to the flush process can further reduce contention. The challenge lies in determining the appropriate number of buckets.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. The market is saturated with tools for building eye-catching dashboards, but ultimately, it comes down to interpreting the presented information.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
The Grail™ data lakehouse provides fast, auto-indexed, schema-on-read storage with massively parallel processing (MPP) to deliver immediate, contextualized answers from all data at scale. However, data overload and skills shortages present challenges that companies need to address to maximize the benefits of cloud and AI technologies.
As Netflix expanded globally and the volume of title launches skyrocketed, the operational challenges of maintaining this manual process became undeniable. Metadata and assets must be correctly configured, data must flow seamlessly, microservices must process titles without error, and algorithms must function as intended.
Through optimization methods, companies can present value propositions that engaged users will be able to navigate with minimal hiccups Lazy Loading: Efficient Content Delivery Lazy loading is a front-end optimization concept that loads front-end sources such as images, videos, iframes, and others on a website when the page is loaded.
The span metrics connector creates these measurements and presents them as histograms, which can be analyzed in Dynatrace for deeper insights. Moreover, the OpenTelemetry Collector can measure service span durations, categorized by span names, span kinds, and status codes.
Logs can also be transformed appropriately for presentation, for example, or further pipeline processing. We can select the right log streams and then filter to focus on the relevant logs. We can then parse structured log data to be formatted for our customized analysis needs.
This process involves: Identifying Stakeholders: Determine who is impacted by the issue and whose input is crucial for a successful resolution. This situation presents both challenges and opportunities; while it may be more difficult to make initial progress, there are plenty of easy wins to capitalize on.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
As a result, requests are uniformly handled, and responses are processed cohesively. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. This centralized format, defined and maintained by our team, ensures all endpoints adhere to a consistent protocol.
Introduction In a previous article , we presented the fundamentals of stream processing. Introductory note : This article has been co-authored by Federico Trotta and Karin Wolok.
This article is the second in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Each format has a different production process and different patterns of cash spend, called our Content Forecast. Need to catch up?
Kickstarting the dashboard creation process is, however, just one advantage of ready-made dashboards. There are cases where more flexible data presentation is needed. This allows platform engineers to focus on high-value tasks like resolving issues and optimizing performance rather than spending time on data discovery and exploration.
The resource is fetched and processed asynchronously while the browser is free to work on whatever other tasks there may be. Files that are render blocking prohibit the browser from presenting the page, but do permit the browser to at least construct it. The two key tasks that are not blocked are rendering and parsing.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Improved Vacuuming: A redesigned memory structure lowers resource use and speeds up the vacuum process. JSON_QUERY extracts JSON fragments based on query conditions.
Health information on SNMP devices is often isolated and discovered devices are not placed in the correct context, failing to fulfill the goal of the discovery process: associating SNMP device data with the IT environments where the devices reside. Start the configuration process for the SNMP Autodiscovery extension.
It’s an underlying web application architecture that makes this process possible. An Overview of Web Application Architecture A web app architecture presents a layout with all the software components (such as databases, applications, and middleware) and how they interact with each other.
Cybersecurity is an ever-present concern for organizations across all industries. Set Goals for Developers Writing code can be a time-consuming process. Threat actors continually seek ways to infiltrate businesses and sell stolen data to the highest bidder.
Dynatrace does this by automatically creating a dependency map of your IT ecosystem, pinpointing the technologies in your stack and how they interact with each other, including servers, processes, application services, and web applications across data centers and multicloud environments. asc | fields `Host`, `Recently Restarted?
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
The vulnerability, identified as CVE-2024-6632, allows the abuse of a form submission during the setup process to make unauthorized modifications of the database. So far, the vulnerability only appears to be exploitable by an authenticated user during the setup process. How could an attacker exploit the new SQL injection vulnerability?
When a question gets asked, run its text through this same embedding model, determine which chunks are nearest neighbors , then present these chunks as a ranked list to the LLM to generate a response. While the overall process may be more complicated in practice, this is the gist. What is GraphRAG? Do LLMs Really Adapt to Domains?
Each of these factors can present unique challenges individually or in combination. But gaining observability of distributed environments, such as Kubernetes, microservices, and containerized application deployments, presents formidable challenges.
Overcoming the barriers presented by legacy security practices that are typically manually intensive and slow, requires a DevSecOps mindset where security is architected and planned from project conception and automated for speed and scale throughout where possible. Challenge: Monitoring processes for anomalous behavior.
Note: The configuration settings present in mysqld-auto.cnf always overrides the values present in the my.cnf file. mysql> RESTART; ERROR 3707 (HY000): Restart server failed (mysqld is not managed by supervisor process). This may be confusing for those transitioning from MySQL 5.7
Keptn is currently leveraging Knative and installs Knative as well as other depending components such as Prometheus during the default keptn installation process. In my case, both prometheus.knative-monitoring pods jumped in Process CPU and I/O request bytes.
We present a systematic overview of the unexpected streaming behaviors together with a set of model-based and data-driven anomaly detection strategies to identify them. Data Featurization A complete list of features used in this work is presented in Table 1. The features mainly belong to two distinct classes.
Dynatrace provides server metrics monitoring in under five minutes, showing servers’ CPU, memory, and network health metrics all the way through to the process level, with no manual configuration necessary. How does Dynatrace help?
This traditional approach presents key performance metrics in an isolated and static way, providing little or no insight into the business impact or progress toward the goals systems support. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends.
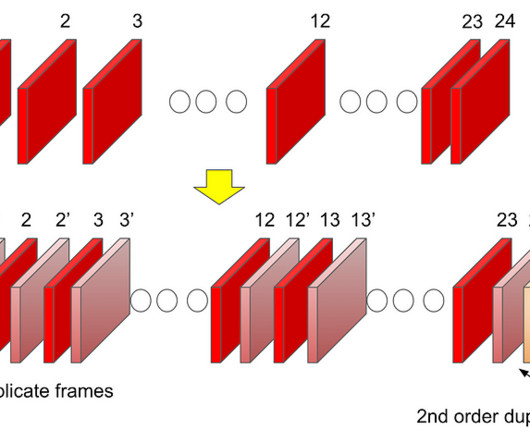
This essentially means that most of the time, our content goes through a process called frame rate conversion (aka FRC) on the source device which converts the content from its native frame rate to match the HDMI output frame rate by replicating frames. HDMI QMS is positioned to be the ideal solution to address the problem we are presenting.
Across both his day one and day two mainstage presentations, Steve Tack, SVP of Product Management, described some of the investments we’re making to continue to differentiate the Dynatrace Software Intelligence Platform. Dynatrace news.
As recent events have demonstrated, major software outages are an ever-present threat in our increasingly digital world. They may stem from software bugs, cyberattacks, surges in demand, issues with backup processes, network problems, or human errors. Outages can disrupt services, cause financial losses, and damage brand reputations.
DevSecOps presents organizations that are already practicing DevOps with an alternate, more proactive perspective on security. With DevSecOps, organizations can combine security and observability with automation, transforming the SDLC into a quicker, more secure, software release process. Challenges of adopting DevSecOps.
To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. This is especially true when the goal is to present information to non-technical users, but all technical teams can benefit from aligning raw metrics with higher-level KPIs and SLOs. Presentation matters.
Our previous blog post presented replay traffic testing — a crucial instrument in our toolkit that allows us to implement these transformations with precision and reliability. A process that doesn’t just minimize risk, but also facilitates a continuous evaluation of the rollout’s impact.
Our partner community plays a vital role in facilitating this transition by effectively communicating the benefits of SaaS and ensuring a seamless migration process. Dynatrace SaaS presents a lower total cost of ownership (TCO), enabling customers to consolidate various tools, thereby optimizing costs and enhancing internal user experiences.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
Observability data presents executives with new opportunities to achieve this, by creating incremental value for cloud modernization , improved business analytics , and enhanced customer experience. With the latest advances from Dynatrace, this process is instantaneous.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
While other methods typically rely on mere correlation and historical data analysis, weve further enhanced our capabilities by implementing causational analysis, which leverages contextual information automatically gathered during data ingestion and processing in addition to historical data analysis.
We accomplish this by paving the path to: Accessing and processing media data (e.g. We accomplish this by paving the path to: Accessing and processing media data (e.g. We will then present a case study of using these components in order to optimize, scale, and solidify an existing pipeline. mp4, clip1.mp4,
The risk of impact from an existing known vulnerability also depends on whether certain processes are using the vulnerable parts of a software component. The Dynatrace third-party vulnerabilities solution provides key capabilities for detailed and continuous insights into vulnerable software components present in an IT system.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content