This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performancetuning needs. The Collector is expected to be ready for prime time in 2025, reaching the v1.0
Site Reliability Engineers (SREs) also face significant challenges in maintaining database reliability, ensuring performance, and preventing disruptions in highly dynamic and distributed environments. Why this matters Databases are the backbone of modern applications, but they can also be a major source of performance bottlenecks.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table. Automating PerformanceTuning with Autoscalers Tuning the performance of our Apache Flink jobs is currently a manual process.
An open-source distributed SQL query engine, Trino is widely used for data analytics on distributed data storage. In this article, we will show you how to tune Trino by helping you identify performance bottlenecks and provide tuning tips that you can practice. But how do we do that?
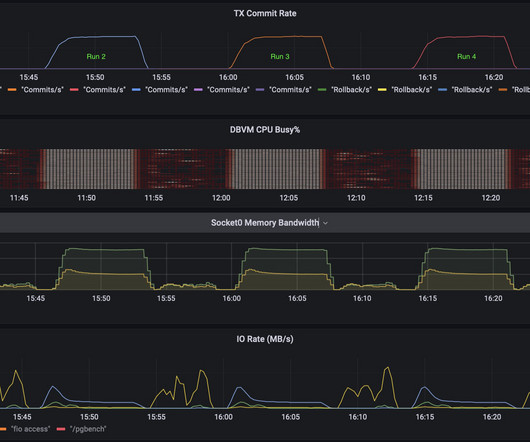
Recently I wanted to measure the impact of NUMA placement and Hugepages on the performance of postgres running in a VM on a Nutanix node. To do this I needed to drive postgres to do real transactions but have very little jitter/noise from the filesystem and storage.
This counting service, built on top of the TimeSeries Abstraction, enables distributed counting at scale while maintaining similar low latency performance. After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. What is RabbitMQ?
For the longest time, hosting static files on CDNs was the de facto standard for performancetuning website pages. The host offered browser caching advantages, better stability, and storage on fast edge servers across strategic geolocations. Not only did it have performance benefits, but it was also convenient for developers.
In this post, we are going to compare the performance and pricing of DigitalOcean PostgreSQL vs. ScaleGrid PostgreSQL to help you determine the best PostgreSQL hosting service on DigitalOcean. On average, ScaleGrid provides over 30% more storage vs. DigitalOcean for PostgreSQL at the same affordable price. Compare Pricing. Single Node.
As Netflix scaled, we faced the mounting challenge of providing accurate, timely answers to increasingly complex queries about title performance and discoverability. By logging all titles as they are displayed, we can process these logs to identify anomalies and gain insights into system performance.
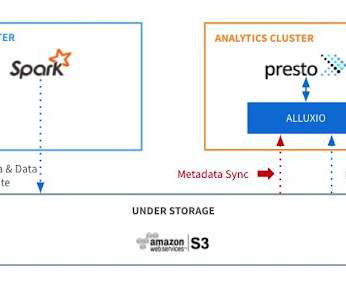
Metadata synchronization (sync) is a core feature in Alluxio that keeps files and directories consistent with their source of truth in under-storage systems, thus making it simple for users to reason the data retrieved from Alluxio. Meanwhile, understanding the internal process is important in order to tune the performance.
Data storage and distribution through HollowFeeds Netflix Hollow is an Open Source java library and toolset for disseminating in-memory datasets from a single producer to many consumers for high performance read-only access.
ScaleGrid provides 30% more storage on average vs. DigitalOcean for MySQL at the same affordable price. MySQL DigitalOcean Performance Benchmark. We are going to use a common, popular plan size using the below configurations for this performance benchmark: Comparison Overview. Compare Pricing. DigitalOcean. Instance Type.
Firstly, developers struggled to reason about consistency, durability and performance in this complex global deployment across multiple stores. This flexibility allows our Data Platform to route different use cases to the most suitable storage system based on performance, durability, and consistency needs.
There are a wealth of options on how you can approach storage configuration in Percona Operator for PostgreSQL , and in this blog post, we review various storage strategies — from basics to more sophisticated use cases. For example, you can choose the public cloud storage type – gp3, io2, etc, or set file system.
Flexible Storage : The service is designed to integrate with various storage backends, including Apache Cassandra and Elasticsearch , allowing Netflix to customize storage solutions based on specific use case requirements. DistinctAggregation) , this endpoint performs the given aggregation within a given time interval.
This blog is in reference to our previous ones for ‘Innodb Performance Optimizations Basics’ 2007 and 2013. Although there have been many blogs about adjusting MySQL variables for better performance since then, I think this topic deserves a blog update since the last update was a decade ago, and MySQL 5.7
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
Dynatrace Grail™ is a data lakehouse optimized for high performance, automated data collection and processing, and queries of petabytes of data in real time. You can use the Grail Storage Record Deletion API to trigger a deletion request. To delete the records, use the Storage Record Deletion API.
The ProRes codec family provides great editing performance and image quality. From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step. Uploading and downloading data always come with a penalty, namely latency.
Iceberg is widely adopted in Netflix as a data warehouse table format that addresses many of the usability and performance problems with Hive tables. Then the KV DAL handles writing to the appropriate underlying storage engines depending on latency, availability, cost, and durability requirements.
Managing storage and performance efficiently in your MySQL database is crucial, and general tablespaces offer flexibility in achieving this. In contrast to the single system tablespace that holds system tables by default, general tablespaces are user-defined storage containers for multiple InnoDB tables.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
Storage mount points in a system might be larger or smaller, local or remote, with high or low latency, and various speeds. Sometimes these locations landed on mount points which, due to capacity, availability, or access constraints, weren’t well suited for large runtime storage. Customizable location of large runtime files.
Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage. An additional implication of a lenient sampling policy is the need for scalable stream processing and storage infrastructure fleets to handle increased data volume. Storage: don’t break the bank!
At Dynatrace Perform 2023 , Maciej Pawlowski, senior director of product management for infrastructure monitoring at Dynatrace, and a senior software engineer at a U.K.-based Business leaders can decide which logs they want to use and tunestorage to their data needs. Seamless integration.
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. There are a wide range of tools and extensions for every conceivable scenario, like performance profiling, auditing, etc. pg_repack – reorganizes tables online to reclaim storage. Compare Ease of Use.
This growth was spurred by mobile ecosystems with Android and iOS operating systems, where ARM has a unique advantage in energy efficiency while offering high performance. Huge performance leaps in recent years The top priority is often performance, where ARM resources have improved significantly.
This challenge has given rise to the discipline of observability engineering, which concentrates on the details of telemetry data to fine-tune observability use cases. But often, we use additional services and solutions within our environment for backups, storage, networking, and more. Observability engineering success!
In addition, we were able to perform a handful of A/B tests to validate or negate our hypotheses for tuning the search experience. Users have flexibility to perform multimodal search with input being a simple text term, image or short video. This service leverages Cassandra and Elasticsearch for data storage and retrieval.
Indexes are generally considered to be the panacea when it comes to SQL performancetuning, and PostgreSQL supports different types of indexes catering to different use cases. I keep seeing many articles and talks on “tuning” discussing how creating new indexes speeds up SQL but rarely ones discussing removing them.
Azure Data Lake Storage Gen1. Understand the performance and status of Azure Logic Apps workflows. We’ll release additional monitoring support for new services soon, so stay tuned for further updates. Azure Logic Apps. Azure Container Instance. Azure Data Factory v1. Azure Data Factory v2. Azure Data Lake Analytics. What’s next?
This post was co-authored by Jean-Louis Lormeau, Digital Performance Architect at Dynatrace. . You’ll learn how to create production SLOs, to continuously improve the performance of services, and I’ll guide you on how to become a champion of your sport by: Creating calculated metrics with the help of multidimensional analysis.
Virtualization has revolutionized system administration by making it possible for software to manage systems, storage, and networks. By removing physical dependencies, automation can help perform SRE at scale. Design, implement, and tune effective SLOs. This number will likely increase as the SRE discipline matures.
As an app developer analyzing a crash detected by Dynatrace, you can see the sequence of steps that were performed by the user along with the crash stack trace: With this information in hand, you can immediately see in which method the error occurred. The masking API we provide allows you to fine-tune the masking configuration to your needs.
In addition, compute and storage are increasingly being separated causing larger latencies for queries. Alluxio is leveraged as compute-side virtual storage to improve performance. But to get the best performance, like any technology stack, you need to follow the best practices. A Note on Data Locality.
Among these, you can find essential elements of application and infrastructure stacks, from app gateways (like HAProxy), through app fabric (like RabbitMQ), to databases (like MongoDB) and storage systems (like NetApp, Consul, Memcached, and InfluxDB, just to name a few). documentation. Prometheus Data Source documentation.
Tuning In terms of tuning, two parameters can be tuned, the size of the bitmap and the number of bits set by every value. For good performance, the filter blocks are cached in the RocksDB block cache and normally stay there since they are accessed frequently. In most cases a bitmap of a few hundred bytes is sufficient.
Dynatrace Digital Experience Monitoring , as part of the Dynatrace Software Intelligence Platform, connects front-end monitoring and the outside-in user perspective with application performance to understand the impact of performance issues across your full stack on user experience and business outcomes. So stay tuned!
In his keynote address on the first day of Perform 2023 in Las Vegas, Dynatrace Chief Technology Officer Bernd Greifeneder and his colleagues discussed how organizations struggle with this problem and how Dynatrace is meeting the moment. Grail combines the big-data storage of a data warehouse with the analytical flexibility of a data lake.
With the help of log monitoring software, teams can collect information and trigger alerts if something happens that affects system performance and health. Log monitoring and analytics work in conjunction to ensure an application is performing as it should be, and to determine how a system could be improved. Increased collaboration.
Understanding why a user is experiencing transactional or performance issues enables organizations to achieve greater observability that goes beyond metrics, traces and logs. Digital experience monitoring (DEM) allows an organization to optimize customer experiences by taking into account the context surrounding digital experience metrics.
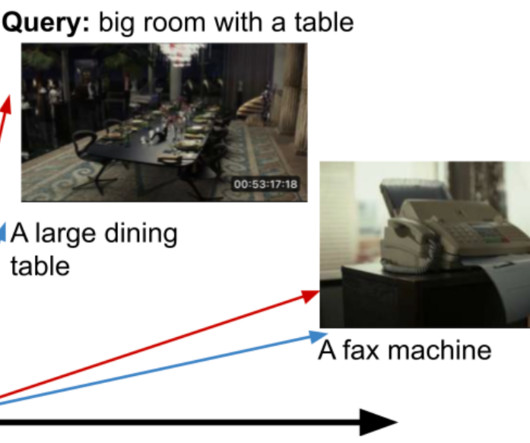
We have built an internal system that allows someone to perform in-video search across the entire Netflix video catalog, and we’d like to share our experience in building this system. During GPU computation, we stream mp4 video shots from S3 directly to the GPUs using a data loader that performs prefetching and preprocessing.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content