This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As an open-source project, OpenTelemetry sets standards for telemetry data sets and works with a wide range of systems and platforms to collect and export telemetry data to backend systems. Second, it enables efficient and effective correlation and comparison of data between various sources.
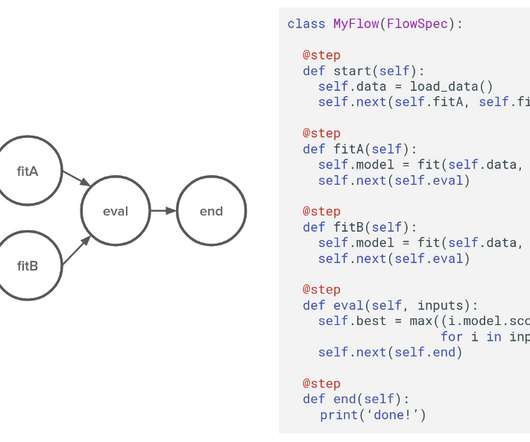
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! We heard many stories about difficulties related to data access and basic data processing. both for compute and storage. Get started at metaflow.org. Metaflow is a cloud-native framework.
These are just a few of the open-source technologies you may encounter as you research observability solutions for managing complex multicloud IT environments and the services that run on them. Of these open-source observability tools, one stands out. Dynatrace news. OpenCensus, OpenTracing, and OpenTelemetry.
In today's data-driven world, efficient data processing plays a pivotal role in the success of any project. Apache Spark , a robust open-source data processing framework, has emerged as a game-changer in this domain.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. What Exactly is Greenplum? Greenplum Advantages.
Netflix has open-sourced Escrow Buddy, which helps Security and IT teams ensure they have valid FileVault recovery keys for all their Macs in MDM. The agent also enables rotation of recovery keys after use, local storage and validation of recovery keys, and other features.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ?
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. With OpenPipeline, you can easily collect data from Dynatrace OneAgent®, opensource collectors such as OpenTelemetry, or other third-party tools.
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! We heard many stories about difficulties related to data access and basic data processing. both for compute and storage. Get started at metaflow.org. Metaflow is a cloud-native framework.
The use of opensource databases has increased steadily in recent years. Past trepidation — about perceived vulnerabilities and performance issues — has faded as decision makers realize what an “opensource database” really is and what it offers. What is an opensource database?
As a result, requests are uniformly handled, and responses are processed cohesively. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. This centralized format, defined and maintained by our team, ensures all endpoints adhere to a consistent protocol.
Open-source software drives a vibrant Kubernetes ecosystem. Opensource software drives a vibrant Kubernetes ecosystem. Across all categories in the Kubernetes survey, opensource projects rank among the most frequently used solutions. Dynatrace’s investment in opensource technologies keeps growing.
Migrating a proprietary database to opensource is a major decision that can significantly affect your organization. It’s a complex process involving various factors and meticulous planning. Flexibility and scalability Opensource databases provide much greater flexibility regarding customization and configuration.
Apache Kafka and Apache Flink are increasingly joining forces to build innovative real-time stream processing applications. The core of Kafka is messaging at any scale in combination with a distributed storage (= commit log) for reliable durability, decoupling of applications, and replayability of historical data.
Kubernetes has become the leading container orchestration platform for organizations adopting opensource solutions to manage, scale, and automate application deployment. Kubernetes is an opensource container orchestration platform for managing, automating, and scaling containerized applications. What is Kubernetes?
This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storage systems (which are used by data lakes). This decoupling ensures the openness of data and storage formats, while also preserving data in context. Ingest and process with Grail.
Reconstructing a streaming session was a tedious and time consuming process that involved tracing all interactions (requests) between the Netflix app, our Content Delivery Network (CDN), and backend microservices. The process started with manual pull of member account information that was part of the session.
Here we present a list of 10 open-source Kubernetes tools to make your SRE and Ops teams more effective to achieve their service level objectives. everything between nodes and processes including deployments, services, replica sets, pods, and containers. The backup files are stored in an object storage service (e.g.
The unstoppable rise of opensource databases. One database in particular is causing a huge dent in Oracle’s market share – opensource PostgreSQL. See how opensource PostgreSQL Community version costs compare to Oracle Standard Edition and Oracle Enterprise Edition. What’s causing this massive shift?
PostgreSQL graphical user interface (GUI) tools help these opensource database users to manage, manipulate, and visualize their data. It supports all PostgreSQL operations and features while being free and open-source. pgAdmin Cost: Free (opensource). Let’s start with the first and most popular one.
The first challenge of effective security analytics involves distributed data sources. The nature of “anytime, anywhere” data generation means data is no longer confined to structured processes and can’t always be defined by existing policies. How do companies reliably find, review, and analyze this data?
Traditionally, though, to gain true business insight, organizations had to make tradeoffs between accessing quality, real-time data and factors such as data storage costs. Additionally, it provides index-free storage and direct analytics access to source data without requiring data rehydration. Don’t reinvent the wheel.
JSON is faster to ingest vs. JSONB – however, if you do any further processing, JSONB will be faster. JSONB storage has some drawbacks vs. traditional columns: PostreSQL does not store column statistics for JSONB columns. JSONB storage results in a larger storage footprint. whitespace) and ordering of the keys.
BindPlane OP is a powerful open-source tool that makes it easy to build and manage telemetry pipelines to ship data from IT environments of any kind and size to any analysis tool or storage destination.
Container orchestration is a process that automates the deployment and management of containerized applications and services at scale. Container orchestration enables organizations to manage and automate the many processes and services that comprise workflows. How does container orchestration work?
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit and Fluentd were created for the same purpose: collecting and processing logs, traces, and metrics. Ask yourself, how much data should Fluent Bit process? What is Fluent Bit?
With these release candidate APIs available, instrumentation for web frameworks, storage clients, and much more can be built. We at Dynatrace understand the importance of contributing our expertise in enterprise-grade intelligent observability to the opensource community. Dynatrace fully embraces OpenTelemetry.
DevOps enables developers to rapidly and frequently release new features and services by using continuous integration and continuous delivery (CI/CD) , suites of collaboration tools, and version control practices, most often with the opensource Git software at its core. GitOps also requires extensive approvals for any development.
I developed many batch and real-time data pipelines using opensource technologies for AOL Advertising and eBay. Over the years, I followed the big data open-source community and Netflix tech blogs closely, and learned a lot about Netflix’s innovative engineering solutions and active contributions to the open-source ecosystem.
These processes are only possible with a distributed architecture and parallel processing mechanisms that Big Data tools are based on. One of the top trending open-source data storage that responds to most of the use cases is Elasticsearch.
Avoid lock-in with open-source technologies. The platform automatically manages all the computing resources required in those processes, freeing up DevOps teams to focus on developing and delivering features and functions. GCF also has relevance in IoT and file processing tasks. How Google Cloud Functions works.
There are many things I love about it – PL/ PG SQL, smart defaults, replication (that actually works out of the box), and an active and vibrant opensource community. Hopefully we can generate enough interest in the opensource community to prioritize these features.
In spite of reaching higher qualities than the fixed ladder, the HDR-DO ladder, on average, occupies only 58% of the storage space compared to fixed-bitrate ladder. For a given rate-quality operating point, the DO process helps allocate bits among the various shots while maximizing an overall objective function.
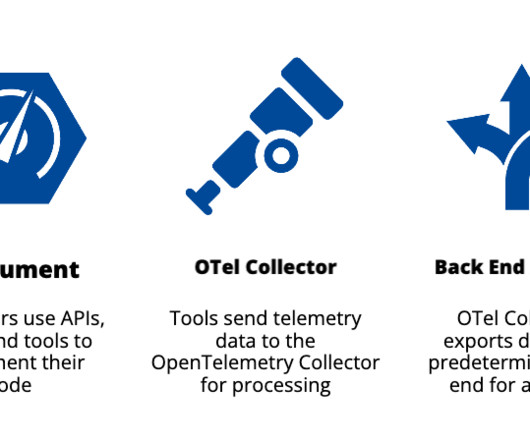
OpenTelemetry is an opensource framework that provides agents, APIs, and SDKs that automatically instrument, generate, and gather telemetry data. The collector processes the data and exports it to a predetermined monitoring, tracing, or logging back end, such as Dynatrace, for analysis. What is OpenTelemetry?
Weaving DevOps and the related disciplines of DevSecOps and AIOps tightly into the development process can also accelerate the process. These reduce the need to hire specialists while providing a unified view of processes and infrastructure that make SRE more focused and effective.
As an opensource database, it’s a highly popular choice for enterprise applications looking to modernize their infrastructure and reduce their total cost of ownership, along with startup and developer applications looking for a powerful, flexible and cost-effective database to work with. ScaleGrid PostgreSQL provides on average 42.3%
Managing storage and performance efficiently in your MySQL database is crucial, and general tablespaces offer flexibility in achieving this. In contrast to the single system tablespace that holds system tables by default, general tablespaces are user-defined storage containers for multiple InnoDB tables.
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. Technology advancements in content creation and consumption have also increased its data footprint.
In a distributed processing environment, message queuing is similar, although the speed and volume of messages are much greater. A producer creates the message, and a consumer processes it. Consumers store messages in a queue — usually in a buffer or on a storage medium — until they can process and delete them.
In a distributed processing environment, message queuing is similar, although the speed and volume of messages are much greater. A producer creates the message, and a consumer processes it. Consumers store messages in a queue — usually in a buffer or on a storage medium — until they can process and delete them.
Many AWS services and third party solutions use AWS S3 for log storage. To date, some customers have used opensource or community-backed components to forward logs from S3 to Dynatrace. This is achieved either by Dynatrace AWS S3 forwarder or log processing mechanisms in Dynatrace.
While speeding up development processes and reducing complexity does make the lives of Kubernetes operators easier, the inherent abstraction and automation can lead to new types of errors that are difficult to find, troubleshoot, and prevent. Configuring storage in Kubernetes is more complex than using a file system on your host.
Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. A database could start executing a storage management process that consumes database server resources. In this case, the best option may be to stop the process and execute it when system load is low.
Fluentd is an open-source data collector that unifies log collection, processing, and consumption. It collects, processes, and outputs log files to and from a wide variety of technologies. Processing plugins parse (normalize), filter, enrich (tagging), format, and buffer log streams. Dynatrace news.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content