This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
API resilience is about creating systems that can recover gracefully from disruptions, such as network outages or sudden traffic spikes, ensuring they remain reliable and secure. This has become critical since APIs serve as the backbone of todays interconnected systems.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. Networktraffic power calculations rely on static power estimations for both public and private networks.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
System resilience stands as the key requirement for e-commerce platforms during scaling operations to keep services operational and deliver performance excellence to users. We have developed a microservices architecture platform that encounters sporadic system failures when faced with heavy traffic events.
For example, if you’re monitoring networktraffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline. An anomaly will be identified if traffic suddenly drops below 200 Mbps or above 800 Mbps, helping you identify unusual spikes or drops.
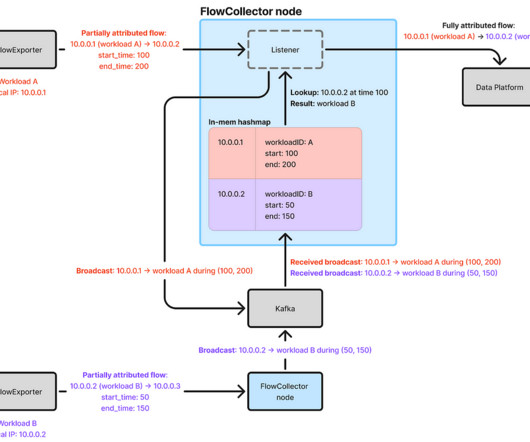
By Cheng Xie , Bryan Shultz , and Christine Xu In a previous blog post , we described how Netflix uses eBPF to capture TCP flow logs at scale for enhanced network insights. Delays and failures are inevitable in distributed systems, which may delay IP address change events from reaching FlowCollector.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. If the network is sluggish, an application may also be slow, frustrating users. Worse, a malicious attacker may gain access to the network, compromising sensitive application data.
Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable. This enables proactive changes such as resource autoscaling, traffic shifting, or preventative rollbacks of bad code deployment ahead of time.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. Distributed cloud systems are complex, dynamic, and difficult to manage without the proper tools. What is log management?
For retail organizations, peak traffic can be a mixed blessing. While high-volume traffic often boosts sales, it can also compromise uptimes. The nirvana state of system uptime at peak loads is known as “five-nines availability.” How can IT teams deliver system availability under peak loads that will satisfy customers?
They may stem from software bugs, cyberattacks, surges in demand, issues with backup processes, network problems, or human errors. Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable.
With the advent of cloud computing, managing networktraffic and ensuring optimal performance have become critical aspects of system architecture. Amazon Web Services (AWS), a leading cloud service provider, offers a suite of load balancers to manage networktraffic effectively for applications running on its platform.
Service meshes are becoming increasingly popular in cloud-native applications as they provide a way to manage networktraffic between microservices. It offers several features, including: Prioritized load shedding: Drops traffic that is deemed less important to ensure that the most critical traffic is served.
The control group’s traffic utilized the legacy Falcor stack, while the experiment population leveraged the new GraphQL client and was directed to the GraphQL Shim. The AB experiment results hinted that GraphQL’s correctness was not up to par with the legacy system. The Replay Tester tool samples raw traffic streams from Mantis.
HAProxy is one of the cornerstones in complex distributed systems, essential for achieving efficient load balancing and high availability. This open-source software, lauded for its reliability and high performance, is a vital tool in the arsenal of network administrators, adept at managing web traffic across diverse server environments.
The Qualys Threat Research Unit (TRU) has discovered a Remote Unauthenticated Code Execution (RCE) vulnerability in OpenSSH server (sshd) in glibc-based Linux systems. This can result in a complete system takeover, malware installation, data manipulation, and the creation of backdoors for persistent access.
Without having network visibility, it’s not possible to improve our reliability, security and capacity posture. Network Availability: The expected continued growth of our ecosystem makes it difficult to understand our network bottlenecks and potential limits we may be reaching. 43416 5001 52.213.180.42 43416 5001 52.213.180.42
This becomes even more challenging when the application receives heavy traffic, because a single microservice might become overwhelmed if it receives too many requests too quickly. A service mesh enables DevOps teams to manage their networking and security policies through code. Why do you need a service mesh?
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. Networking. What is Docker?
In our Dynatrace Dashboard tutorial, we want to add a chart that shows the bytes in and out per host over time to enhance visibility into networktraffic. By tracking these metrics, we can identify any unusual spikes or drops in network activity, which might indicate performance issues or bottlenecks. Expand the Trend section.
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. A local endpoint in a protected network or DMZ is required to capture these messages. The key to success is making data in this complex ecosystem actionable, as many types of syslog producers exist.
The network latency between cluster nodes should be around 10 ms or less. Minimized cross-data center networktraffic. For Premium HA, this has been extended from 10 ms latency (in the same network region) to around 100 ms network latency due to asynchronous data replication between regions.
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. CRITICAL : This traffic affects the ability to play.
In the dynamic world of microservices architecture, efficient service communication is the linchpin that keeps the system running smoothly. Understanding Service Mesh A service mesh is essentially the invisible backbone of a network, connecting and empowering the various components of a microservices ecosystem.
But managing the breadth of the vulnerabilities that can put your systems at risk is challenging. Security vulnerabilities are weaknesses in applications, operating systems, networks, and other IT services and infrastructure that would allow an attacker to compromise a system, steal data, or otherwise disrupt IT operations.
Application security monitoring is the practice of monitoring and analyzing applications or software systems to detect vulnerabilities, identify threats, and mitigate attacks. Forensics focuses on the systemic investigation and analysis of digital evidence to determine root causes.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
Introduction to Message Brokers Message brokers enable applications, services, and systems to communicate by acting as intermediaries between senders and receivers. This decoupling simplifies system architecture and supports scalability in distributed environments.
The system could work efficiently with a specific number of concurrent users; however, it may get dysfunctional with extra loads during peak traffic. Performances testing helps establish the scalability, stability, and speed of the software application.
This new service enhances the user visibility of network details with direct delivery of Flow Logs for Transit Gateway to your desired endpoint via Amazon Simple Storage Service (S3) bucket or Amazon CloudWatch Logs. AWS Transit Gateway is a service offering from Amazon Web Services that connects network resources via a centralized hub.
They can also develop proactive security measures capable of stopping threats before they breach network defenses. For example, an organization might use security analytics tools to monitor user behavior and networktraffic. But, observability doesn’t stop at simply discovering data across your network.
As a Network Engineer, you need to ensure the operational functionality, availability, efficiency, backup/recovery, and security of your company’s network. But manual configuration of observability for systems like this is nearly impossible. Synthetic network monitoring. Events and alerts. A sneak peak. Give it a try!
Over the last two month s, w e’ve monito red key sites and applications across industries that have been receiving surges in traffic , including government, health insurance, retail, banking, and media. The following day, a normally mundane Wednesday , traffic soared to 128,000 sessions. Media p erformance .
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
Software performance can be compromised in many ways, including software bugs, cyberattacks, overwhelming demand, backup failures, network issues, and human error. Teams can use this information to optimize infrastructure and application performance, ensuring that systems can handle increased traffic without compromising user experience.
As the number of Titus users increased over the years, the load and pressure on the system increased substantially. cell): Titus Job Coordinator is a leader elected process managing the active state of the system. For example, a batch workflow orchestration system may create multiple jobs which are part of a single workflow execution.
As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. For most systems, an optimum MTTR could be less than one hour while others have an MTTR of less than one day.
It is also recommended that SSL connections be enabled to encrypt the client-database traffic. With MongoDB deployments, failovers aren’t considered major events as they were with traditional database management systems. 1305:12 @(shell):1:1 2019-04-18T19:44:42.261+0530 I NETWORK [thread1] trying reconnect to SG-example-1.servers.mongodirector.com:27017
As the world socially distances, we are seeing significant increases in website traffic as people turn to their phones and devices, to connect with loved ones, buy online, distance learn, work remotely, and continuously keep up with the news. . We are hopeful that the world can, and will, quickly return to normal. it’s not increasing!).
In a distributed system, consensus plays an important role in determining consistency, and Patroni uses DCS to attain consensus. This way, at any point in time, there can only be one master running in the system. Network Isolation Tests. Network-isolate the master server from other servers. Network Isolation Tests.
Open Connect Open Connect is Netflix’s content delivery network (CDN). video streaming) takes place in the Open Connect network. Various software systems are needed to design, build, and operate this CDN infrastructure, and a significant number of them are written in Python. are you logged in?
Malicious attackers have gotten increasingly better at identifying vulnerabilities and launching zero-day attacks to exploit these weak points in IT systems. A zero-day exploit is a technique an attacker uses to take advantage of an organization’s vulnerability and gain access to its systems. half of all corporate networks.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content