This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here are five strategies executives can pursue to reduce tool sprawl, lower costs, and increase operational efficiency. Traditional network-based security approaches are evolving. Enhanced security measures, such as encryption and zero-trust, are making it increasingly difficult to analyze security threats using network packets.
The following diagram shows a brief overview of some common security misconfigurations in Kubernetes and how these map to specific attacker tactics and techniques in the K8s Threat Matrix using a common attack strategy. Missing network policies + inadequate namespace isolation Attack technique. Misconfiguration.
As cloud networks continue to expand, security concerns become increasingly complex, making it critical to ensure robust protection without sacrificing performance. These advanced firewalls are integral to cloud security strategies, combining multiple layers of defense with optimized performance to tackle evolving threats.
“Set it and forget it” is the approach that most network teams follow with their authoritative Domain Name System (DNS). If the system is working and end-users find network connections to revenue-generating applications, services, and content, then administrators will generally say that you shouldn’t mess with success.
In this post I want to look at how CSS can prove to be a substantial bottleneck on the network (both in itself and for other resources) and how we can mitigate it, thus shortening the Critical Path and reducing our time to Start Render. Employ Critical CSS. This is on purpose. Test, test, test. It’s also very component friendly.
API resilience is about creating systems that can recover gracefully from disruptions, such as network outages or sudden traffic spikes, ensuring they remain reliable and secure. In this article, Ill share practical strategies for designing APIs that scale, handle errors effectively, and remain secure over time.
When communications aren’t properly encrypted, attackers who gain network access can intercept traffic between components. This could expose pod placement decisions, resource allocation information, service account tokens, and deployment strategies. Real-world impact. Common misconfiguration.
In response, many organizations are adopting a FinOps strategy. Observability tools can provide insights into resource utilization metrics, such as CPU usage, memory usage, and network throughput. Drive your FinOps strategy with Dynatrace In the simplest sense, FinOps is about optimizing and using cloud resources more efficiently.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. If the network is sluggish, an application may also be slow, frustrating users. Worse, a malicious attacker may gain access to the network, compromising sensitive application data.
Citizens need seamless digital experiences, which is why the concept of a total experience (TX) strategy is gaining traction among government institutions. A TX strategy is an innovative approach that seeks to overhaul the traditional paradigms of public service delivery. Everything impacts and influences each other.
In this preview video for Dynatrace Perform 2022, I talk to Ajay Gandhi, VP of product marketing at Dynatrace, about how adding a vulnerability management strategy to your DevSecOps practices can be key to handling threats posed by vulnerabilities. ?. Perform 2022 conference coverage , check out our guide.
With the complexity of today’s technology landscape, a modern observability strategy is critical for organizations to stay competitive. The post Accenture, AWS, and Dynatrace: Racing towards a modern observability strategy appeared first on Dynatrace news.
For IT teams seeking agility, cost savings, and a faster on-ramp to innovation, a cloud migration strategy is critical. Define the strategy, assess the environment, and perform migration-readiness assessments and workshops. The seven Rs of a cloud migration strategy with Dynatrace. Dynatrace news. Mobilize and plan.
One study found that 93% of companies have a multicloud strategy to enable them to use the best qualities of each cloud provider for different situations. Get to the root cause of issues Most AI today uses machine learning models like neural networks that find correlations and make predictions based on them.
For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline. Business: Using information on past order volumes, businesses can predict future sales trends, helping to manage inventory levels and effectively plan marketing strategies.
Youll also learn strategies for maintaining data safety and managing node failures so your RabbitMQ setup is always up to the task. They can be mirrored and configured for either availability or consistency, providing different strategies for managing network partitions.
It’s also critical to have a strategy in place to address these outages, including both documented remediation processes and an observability platform to help you proactively identify and resolve issues to minimize customer and business impact. Outages can disrupt services, cause financial losses, and damage brand reputations.
Compressing them over the network: Which compression algorithm, if any, will we use? Given that 66% of all websites (and 77% of all requests ) are running HTTP/2, I will not discuss concatenation strategies for HTTP/1.1 What happens when we adjust our compression strategy? in this article. If you are still running HTTP/1.1,
Mastering Hybrid Cloud Strategy Are you looking to leverage the best private and public cloud worlds to propel your business forward? A hybrid cloud strategy could be your answer. Understanding Hybrid Cloud Strategy A hybrid cloud merges the capabilities of public and private clouds into a singular, coherent system.
Continuous cloud monitoring with automation provides clear visibility into the performance and availability of websites, files, applications, servers, and network resources. This type of monitoring tracks metrics and insights on server CPU, memory, and network health, as well as hosts, containers, and serverless functions.
Learn best practices: Get expert recommendations on building a proactive Kubernetes security automation strategy. Discovery and inventory First, a KSPM platform ideally identifies all Kubernetes resources including nodes, pods, namespaces, RBAC roles, network policies and configurations. Why is KSPM important?
Border Gateway Protocol ( BGP ) is the cornerstone of the internet's routing architecture, enabling data exchange between different autonomous systems (AS’s) and ensuring seamless communication across diverse networks. However, the complexity of BGP can make troubleshooting a daunting task, even for experienced network engineers.
Therefore, they need an environment that offers scalable computing, storage, and networking. Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. What is hyperconverged infrastructure?
Confused about multi-cloud vs hybrid cloud and which is the right strategy for your organization? Real-world examples like Spotify’s multi-cloud strategy for cost reduction and performance, and Netflix’s hybrid cloud setup for efficient content streaming and creation, illustrate the practical applications of each model.
Dynatrace provides up-to-date network maps, identifies critical services, and highlights gaps in coverage. Integrating Dynatrace into organizations’ compliance strategy can be a valuable step for executives and senior management to help secure their organizations’ future.
A well-planned multi cloud strategy can seriously upgrade your business’s tech game, making you more agile. Key Takeaways Multi-cloud strategies have become increasingly popular due to the need for flexibility, innovation, and the avoidance of vendor lock-in. Thinking about going multi-cloud?
There are a wealth of options on how you can approach storage configuration in Percona Operator for PostgreSQL , and in this blog post, we review various storage strategies — from basics to more sophisticated use cases. This is done without downtime, but replication might introduce additional load on the primary node and the network.
This includes latency, which is a major determinant in evaluating the reliability and performance of your Redis instance, CPU usage to assess how much time it spends on tasks, operations such as reading/writing data from disk or network I/O, and memory utilization (also known as memory metrics). </p>
The Network and Information Systems 2 (NIS2) Directive, which goes into effect in Oct 2024, aims to enhance the security of network and information systems throughout the EU. NIS2 is an evolution of the Network and Information Systems (NIS) Security Directive, which has been in effect since 2016.
In this blog post, we will explore how network partitions impact group replication and the way it detects and responds to failures. In case you haven’t checked out my previous blog post about group replication recovery strategies, please have a look at them for some insight.
This operational data could be gathered from live running infrastructures using software agents, hypervisors, or network logs, for example. Additionally, ITOA gathers and processes information from applications, services, networks, operating systems, and cloud infrastructure hardware logs in real time.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. A network administrator sets up a network, manages virtual private networks (VPNs), creates and authorizes user profiles, allows secure access, and identifies and solves network issues.
In-depth testing, redundancy, and disaster recovery plans are just a few of the strategies that organizations are implementing to reduce the risks related to system failures. Businesses rely heavily on intricate systems and networks to run effectively in today's technology-driven world.
This includes latency, which is a major determinant in evaluating the reliability and performance of your Redis® instance, CPU usage to assess how much time it spends on tasks, operations such as reading/writing data from disk or network I/O, and memory utilization (also known as memory metrics). </p>
They collect data from multiple sources through real user monitoring , synthetic monitoring, network monitoring, and application performance monitoring systems. How to improve digital experience monitoring Implementing a successful DEM strategy can come with challenges.
Armed with an understanding of their monitoring maturity, organizations can develop a strategy for harnessing their data to automate more of their operations. Such a strategy relies on the ability to implement three capabilities: End-to-end observability across a broad spectrum of technologies. Out-of-the-box AIOps.
The three strategies we will discuss today are AB Testing , Replay Testing, and Sticky Canaries. Let’s discuss the three testing strategies in further detail. Doing this safely for 100s of millions of customers without disruption is exceptionally challenging, especially considering the many dimensions of change involved.
To address potentially high numbers of requests during online shopping events like Singles Day or Black Friday, it’s crucial that this online shop have a memory storage strategy that allows for speed, scaling, and resilience of all microservices, especially the shopping cart service.
Let’s delve deeper into how these capabilities can transform your observability strategy, starting with our new syslog support. Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases.
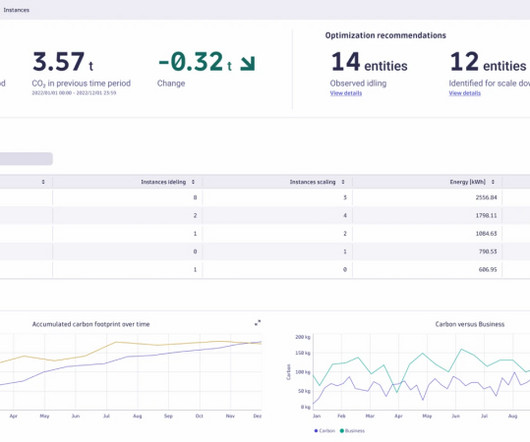
These metrics include CPU, memory, disk, and network I/O. As a result, this baseline measurement has become an important component of our sustainability strategy. Because it facilitates ongoing monitoring and tracks progress toward our sustainability goals, we can adjust our strategy to reduce our IT carbon footprint.
The attackers often exploit vulnerabilities to gain access to the organization's network and steal or encrypt data for ransom. That's why it's important to have a disaster recovery plan or recovery strategy ready to deal with such critical situations.
Software performance can be compromised in many ways, including software bugs, cyberattacks, overwhelming demand, backup failures, network issues, and human error. Each of these factors can present unique challenges individually or in combination.
In the paradigm of zero trust architecture , Privileged Access Management (PAM) is emerging as a key component in a cybersecurity strategy, designed to control and monitor privileged access within an organization. What Is a Privileged User and a Privileged Account?
Optimizing I/O workloads in Python typically involves understanding where the bottlenecks are and then applying strategies to reduce or manage these bottlenecks. Do they involve disk I/O, such as file read/write operations, network I/O, which includes data transmission over a network, or database I/O, comprising database interactions?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content