This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To extend Dynatrace diagnostic visibility into networktraffic, we’ve added out-of-the-box DNS request tracking to our infrastructure monitoring capabilities. While our competitors only provide generic traffic monitoring without artificial intelligence, Dynatrace automatically analyzes DNS-related anomalies.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. If the network is sluggish, an application may also be slow, frustrating users. Worse, a malicious attacker may gain access to the network, compromising sensitive application data.
In the past 15+ years, online video traffic has experienced a dramatic boom utterly unmatched by any other form of content. It must be said that this video traffic phenomenon primarily owes itself to modernizations in the scalability of streaming infrastructure, which simply weren’t present fifteen years ago.
Continuous cloud monitoring with automation provides clear visibility into the performance and availability of websites, files, applications, servers, and network resources. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Cloud storage monitoring.
They can also develop proactive security measures capable of stopping threats before they breach network defenses. For example, an organization might use security analytics tools to monitor user behavior and networktraffic. Dehydrated data has been compressed or otherwise altered for storage in a data warehouse.
The network latency between cluster nodes should be around 10 ms or less. Minimized cross-data center networktraffic. For Premium HA, this has been extended from 10 ms latency (in the same network region) to around 100 ms network latency due to asynchronous data replication between regions.
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
To address potentially high numbers of requests during online shopping events like Singles Day or Black Friday, it’s crucial that this online shop have a memory storage strategy that allows for speed, scaling, and resilience of all microservices, especially the shopping cart service.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
This new service enhances the user visibility of network details with direct delivery of Flow Logs for Transit Gateway to your desired endpoint via Amazon Simple Storage Service (S3) bucket or Amazon CloudWatch Logs. The newly introduced VPC Flow Logs for Transit Gateway service brings a new network dimension to application monitoring.
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. It involves both the collection and storage of logs, as well as aggregation, analysis, and even the long-term storage and destruction of log data.
Reconstructing a streaming session was a tedious and time consuming process that involved tracing all interactions (requests) between the Netflix app, our Content Delivery Network (CDN), and backend microservices. A second job taps the data feed from the first job, does tail sampling of data and writes traces to the storage system.
Resource consumption & traffic analysis. While most of our cloud & platform partners have their own dependency analysis tooling, most of them focus on basic dependency detection based on network connection analysis between hosts. How much traffic is sent between two processes hosting a certain service?
Challenges At Netflix, temporal data is continuously generated and utilized, whether from user interactions like video-play events, asset impressions, or complex micro-service network activities. Handling Bursty Traffic : Managing significant traffic spikes during high-demand events, such as new content launches or regional failovers.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
As Dynatrace deployments grow rapidly, we’re making it easier for Dynatrace Managed customers to proactively monitor and plan their network, storage, and compute power requirements—so that we can deliver the SaaS experience on top of it. This means that you’ll get three dashboards per management zone , one for each focus area.
With DEM solutions, organizations can operate over on-premise network infrastructure or private or public cloud SaaS or IaaS offerings. STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables).
Dynatrace Synthetic Monitoring helps you quickly verify if your application is delivering the expected end user experience by offering an outside-in view of all your applications and services, independent of real traffic. Storage and management of credentials via the Synthetic Monitoring credential vault. But wait, there’s more!
One key requirement of a microservices architecture is the ability to make information of all kinds available wherever and whenever it’s needed, without putting undue traffic on corporate and public networks. Synchronous storage size. Async storage size. Storage read size rate. Storage read count rate.
Traffic This SLO measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. The traffic SLO targets the website’s ability to handle a high volume of transactional activity during periods of high demand. The Apdex score of 0.85
The process involves monitoring various components of the software delivery pipeline, including applications, infrastructure, networks, and databases. Infrastructure monitoring Infrastructure monitoring reviews servers, storage, network connections, virtual machines, and other data center elements that support applications.
1) depicts the migration of traffic from fixed bitrates to DO encodes. 1: Migration of traffic from fixed-ladder encodes to DO encodes. In spite of reaching higher qualities than the fixed ladder, the HDR-DO ladder, on average, occupies only 58% of the storage space compared to fixed-bitrate ladder. The graphic below (Fig.
Edgar captures 100% of interesting traces , as opposed to sampling a small fixed percentage of traffic. This difference has substantial technological implications, from the classification of what’s interesting to transport to cost-effective storage (keep an eye out for later Netflix Tech Blog posts addressing these topics).
As a result, the number of servers and the quantity of traffic have been exploding exponentially. The cohesive, albeit heterogeneous on-premises IT environments of the past have given way to a disaggregated, interdependent mélange of compute, network, and storage components, both on-premises and in the private and public clouds.
There are certain situations when an agent based approach isn’t possible, such as with network or storage devices, or a very old OS. Dynatrace OneAgent is great for monitoring the full stack. However, you can’t install OneAgents on every single type of device.
When a new leader is elected it loads all data from external storage. With traffic growth, a single leader node handling all request volume started becoming overloaded. Network propagation delays and stream processing times start to become a more important factor as the number of state change events and client requests increases.
With EC2, Amazon manages the basic compute, storage, networking infrastructure and virtualization layer, and leaves the rest for you to manage: OS, middleware, runtime environment, data, and applications. EC2 is ideally suited for large workloads with constant traffic. AWS Lambda.
Contact Dynatrace ONE if you wish to enable Cluster-side screenshot storage on pre-1.216 fresh-installed Clusters. To improve management of node capabilities , we added Enable/disable Web UI traffic operation for cluster node in Cluster Mission Control UI. APM-292756). APM-288329). APM-290353). APM-298915). APM-295508).
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. Technology advancements in content creation and consumption have also increased its data footprint. Wednesday?—?December
Compression in any database is necessary as it has many advantages, like storage reduction, data transmission time, etc. Storage reduction alone results in significant cost savings, and we can save more data in the same space. In this blog, we will discuss both data and network-level compression offered in MongoDB.
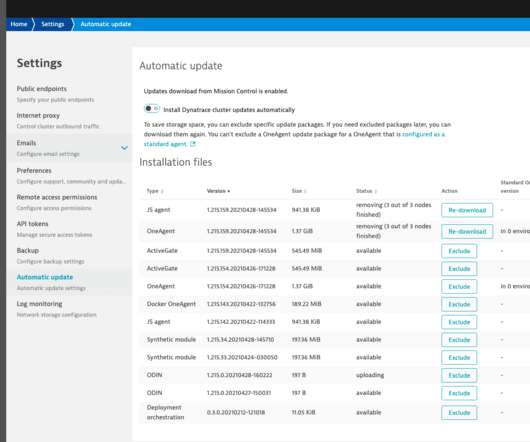
Consequently, each new version of OneAgent for Windows consumed double storage space: one for the *.exe This storage space was consumed not only on our own infrastructure but also on each of the Dynatrace cluster nodes in the case of Managed deployments. And it added to the networktraffic in terms of new version distribution.
Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. Message Broker vs. Distributed Event Streaming Platform RabbitMQ functions as a message broker, managing message confirmation, routing, storage, and delivery within a queue. What is RabbitMQ?
Traffic The traffic SLO example measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. The traffic SLO targets the website’s ability to handle a high volume of transactional activity during periods of high demand. The Apdex score of 0.85
pgBackrest on the Main site streams backups and Write Ahead Logs (WALs) to the object storage. Once installed, configure the Custom Resource manifest so that pgBackrest starts using the Object Storage of your choice. In this case, you can be sure that Main really failed, and it is not a network split situation.
Scenario 3 – Network Partition – Network Connectivity Breaks Down Between Master and Slave Nodes. This is a classical problem in any distributed system where each node thinks the other nodes are down, while in reality, only the network communication between the nodes is broken.
Figure 1: PMM Home Dashboard From the Amazon Web Services (AWS) documentation , an instance is considered over-provisioned when at least one specification of your instance, such as CPU, memory, or network, can be sized down while still meeting the performance requirements of your workload and no specification is under-provisioned.
The homepage needs to load in a reasonable amount of time, even in poor network conditions. This requires an asset storage solution. Asset Storage We refer to asset storage and management simply as asset management. We need to be able to easily determine what imagery is present for a given platform, region, and language.
. $40 million : Netflix monthly spend on cloud services; 5% : retention increase can increase profits 25%; 50+% : Facebook's IPv6 traffic from the U.S, using them to respond to storage events on s3 or database events or auth events is super easy and powerful. they can can be two orders of magnitude faster than FastBitSet.js.
This becomes an even more important lesson at scale: for example, as S3 processes trillions and trillions of storage transactions, anything that has even the slightest probability of error will become realistic. If customers have many tiny files, then storage and bandwidth don’t amount to much even if they are making millions of requests.
This article will explore how they handle data storage and scalability, perform in different scenarios, and, most importantly, how these factors influence your choice. It uses a hash table to manage these pairs, divided into fixed-size buckets with linked lists for key-value storage. Redis Database Management with ScaleGrid ScaleGrid.io
The DBMS is key to maintaining these aspects by offering a storage system that allows users to perform operations such as data insertion, deletion, and selection, thereby promoting enhanced data integration across diverse applications and platforms.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content