This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Over the past decade, DevOps has emerged as a new tech culture and career that marries the rapid iteration desired by software development with the rock-solid stability of the infrastructure operations team. As of August 2019, there are currently over 50,000 LinkedIn DevOps job listings in the United States alone.
The streaming data store makes the system extensible to support other use-cases (e.g. FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. System Components. Streaming Data Model. References.
While load testing may sound like an esoteric domain exclusive to softwareengineers or network administrators, it is, in fact, a silent superhero in our increasingly digital world. It's the silent force keeping the digital infrastructure wheel rotating smoothly, even during peak usage times.
Malicious attackers have gotten increasingly better at identifying vulnerabilities and launching zero-day attacks to exploit these weak points in IT systems. A zero-day exploit is a technique an attacker uses to take advantage of an organization’s vulnerability and gain access to its systems. half of all corporate networks.
This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. How site reliability engineering affects organizations’ bottom line SRE applies the disciplines of softwareengineering to infrastructure management, both on-premises and in the cloud.
The Android launch leveraged the open-source software decoder dav1d built by the VideoLAN, VLC, and FFmpeg communities and sponsored by AOMedia. We were very pleased to see that AV1 streaming improved members’ viewing experience, particularly under challenging network conditions.
As the number of Titus users increased over the years, the load and pressure on the system increased substantially. cell): Titus Job Coordinator is a leader elected process managing the active state of the system. For example, a batch workflow orchestration system may create multiple jobs which are part of a single workflow execution.
Snap: a microkernel approach to host networking Marty et al., This paper describes the networking stack, Snap , that has been running in production at Google for the last three years+. You need a lot of softwareengineers and the willingness to rewrite a lot of software to entertain that idea. SOSP’19.
OneAgent gives you all the operational and business performance metrics you need, from the front end to the back end and everything in between—cloud instances, hosts, network health, processes, and services. GPU-based machine learning system crashes, and you don’t know why? Example 1: Gain visibility into your NVIDIA GPUs.
Visibility into system activity and behavior has become increasingly critical given organizations’ widespread use of Amazon Web Services (AWS) and other serverless platforms. AWS Lambda makes it easy to design, run, and maintain application systems without having to provision or manage infrastructure. Dynatrace news. Amazon EC2.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN.
Join us and be a part of the amazing team that brought you this tech-blog; open positions: SoftwareEngineer, Cloud Gaming SoftwareEngineer, Live Streaming References [1] L. Krasula, A. Choudhury, S. Malfait, A. 263–1–8 (2023) [ online ] [2] A.
Application security is a softwareengineering term that refers to several different types of security practices designed to ensure applications do not contain vulnerabilities that could allow illicit access to sensitive data, unauthorized code modification, or resource hijacking. Dynatrace news. So, why is all this important?
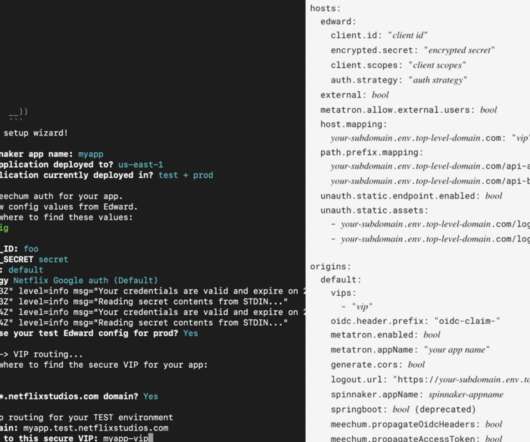
A few years ago, we decided to address this complexity by spinning up a new initiative, and eventually a new team, to move the complex handling of user and device authentication, and various security protocols and tokens, to the edge of the network, managed by a set of centralized services, and a single team.
Nearly all of the blockers related to systems in which (usually for historical reasons) some application team was solving both authentication and application routing in a custom way. A big part of their work is this idea of harvesting developer intent and automating the necessary touchpoints across our systems.
Data Scientists play a vital role in building automated systems that leverage causal inference to decide how we spend our advertising budget. One way we do this is through constantly improving the recommendation systems that produce a personalized home page experience for each of our members.
Migrating a privacy-safe information extraction system to a software 2.0 This is a comparatively short (7 pages) but very interesting paper detailing the migration of a softwaresystem to a ‘Software 2.0’ A really interesting thing happens when you go from developing a Software 1.0 (i.e.,
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN.
The first version of our logger library optimized for storage by deduplicating facts and optimized for network i/o using different compression methods for each fact. Hence, we designed a comprehensive system that monitors the quality of data flowing through Axion to detect corruptions, whether introduced by Axion or outside Axion.
In the same spirit as Paxos Made Live , this paper describes the details, choices and tradeoffs that are required to put a consensus system into production. Physalia is designed to offer consistency and high-availability, even under network partitions. In theory, systems built using this pattern can achieve extremely high availability.
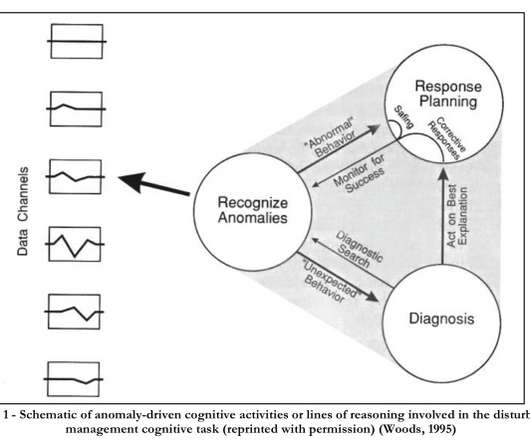
Allspaw highlights four key challenges: The systems are uniquely opaque, with multiple layers of abstraction hiding underlying complexity, performance variability under normal conditions, and an increasing interdependence between services, including across organisational boundaries. Moreover: Causality is complex and networked.
Second, the behavior of AI systems changes over time. Is it important to observe what happens on each layer of a neural network? Given source code and the training data, you could re-produce a model, but it almost certainly wouldn’t be the same because of randomization in the training process.
Wynter is looking for system administrators, engineers, and developers to join its research panel. SysOps Enginee r: As Kinsta ’s SysOps Engineer, you’ll play a key role in caring for the health of our servers, preventing issues, and responding immediately to mitigate any problems in our infrastructure. Apply here.
Wynter is looking for system administrators, engineers, and developers to join its research panel. SysOps Enginee r: As Kinsta ’s SysOps Engineer, you’ll play a key role in caring for the health of our servers, preventing issues, and responding immediately to mitigate any problems in our infrastructure. Apply here.
Teaching rigorous distributed systems with efficient model checking Michael et al., It describes the labs environment, DSLabs , developed at the University of Washington to accompany a course in distributed systems. Enabling students to build running performant versions of all of those systems in the time available is one challenge.
Using SQL Server’s SNITrace to Troubleshoot Networking Issues In the process of tracking down a few TCP 10054 issues (highlighted here: [link] ) I also used the SNITrace (SNI Trace) capabilities.
The homepage needs to load in a reasonable amount of time, even in poor network conditions. Let’s put it all together and review the system interaction diagram. We need to be able to easily determine what imagery is present for a given platform, region, and language.
However, we often hear anecdotes that the number of prospective graduate students applying to computer architecture/systems is small and shrinking. Networking sessions that create opportunities for students to interact with graduate students and established architects in academia and industry. Why is that?
Partitioning allows SQL Server to scale to the largest systems with record-setting performance. When promoted to a super-latch on a 64 CPU system the memory requirement becomes 32 + (32 *64) = 2080 bytes. However, on smaller systems and VMs the partitioning may not be required to maintain performance. Networking Pump Threads.
Scaling symbolic evaluation for automated verification of systems code with Serval Nelson et al., Serval is a framework for developing automated verifiers of systemssoftware. Serval enables us, with a reasonable effort, to develop multiple verifiers, apply the verifiers to a range of systems, and find previously unknown bugs.
Softwareengineers represent the largest cohort, comprising almost 20% of all respondents (see Figure 1 ). Technical leads and architects (about 11%) are next, followed by software and systems architects (9+%). For this audience, SRE’s future is brighter than AI’s, however. Respondent Demographics.
That’s right; I’ve parked day-to-day design work in favor of becoming someone very active in the design community, focusing on best practice design advice and scalable systems. Prioritize Networking Over Pushing Pixels. Prioritize networking over pushing pixels. A Design System Is Not A Sticker Sheet ,” by Corey Roth.
There may be alarm systems. The concept of Zero Trust Networks speaks to this problem. There have been cases of harassment, intimidation, and domestic abuse by people whose access should have been revoked: for example, an ex-partner turning off the heating system. It’s important to account for children from the beginning.
A site reliability engineer, or SRE, is a role that that encompasses aspects of both softwareengineering and operations/infrastructure. The term site reliability engineering first came into existence at Google in 2003 when a site reliability team was created. At that time, the team was made up of softwareengineers.
In the context of the papers we’ve been looking at recently, and for a constrained environment, Reverb is helping its users to form an accurate mental model of the system state, and to form and evaluate hypotheses in-situ. candidate bug-fixes) during replay.
Yet we continue to find new applications for software: it is increasingly a product differentiator (embedded systems) or a product category of its own (social networking). Economic and perhaps even political pressure will intensify to industrialize software development. But demand tends to be impatient.
finding good softwareengineers takes so long and requires so much effort… but it doesn’t have to. Improving your hiring fortunes is not just about optimising your hiring process, it’s about making systemic changes to your organisation. Hiring is so hard?—?finding Contact me if you are interested or would like to know more.
USENIX’s LISA conference is the premier event for topics in production systemengineering. We both have had long careers supporting system administration, and LISA has always felt like a homecoming, reuniting with old friends while welcoming newcomers. Join us for 3 days in Nashville at LISA'18.
Are you ready to take your system assurance programme to the next level? In all cases we need to be able to carefully monitor the impact on the system, and back out if things start going badly wrong. Netflix’s system is deployed on the public cloud as complex set of interacting microservices.
I thought the network trace might reveal a SYN, a long delay that exceeded the connection timeout and a close (RST) from the client. What was causing the SQL Server networking client to call the TCP open and then call TCP close without exceeding the connection timeout and without attempting the TDS login activities? Powershell Script.
USENIX’s LISA conference is the premier event for topics in production systemengineering. We both have had long careers supporting system administration, and LISA has always felt like a homecoming, reuniting with old friends while welcoming newcomers. Join us for 3 days in Nashville at LISA'18.
On Windows the system stores this in the registry and during startup increments the value. Mac Address: Is usually associated with a system component (network card) and for SQL Server on Linux, SQLPAL generates a pseudo-mac using a uuid (uuid_generate) and preserves the value in the instance_id file during the first startup.
Omnipresent connectivity is driving new disruptive business models which are further driving up demands on the networks. Virtualization of appliances and systems is seen as a necessary step to add the agility to meet these increasing and evolving service demands. John Abraham] I don’t think so. There is not a consensus yet.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content