This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
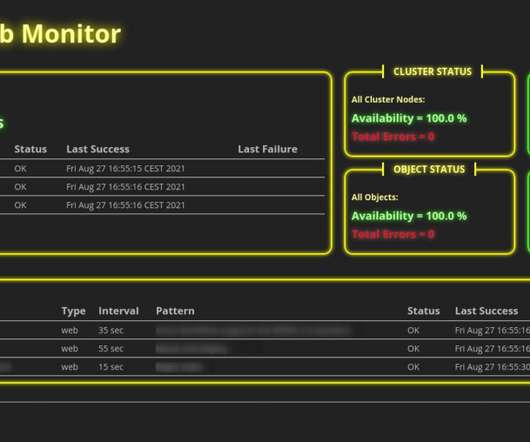
If you run several web servers in your organization or even public web servers on the internet, you need some kind of monitoring. If your servers go down for some reason, this may not be funny for your colleagues, customer, and even for yourself. For that reason, we use monitoring tools. Introduction.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
Applications and services are often slowed down by under-performing DNS communications or misconfigured DNS servers, which can result in frustrated customers uninstalling your application. While our competitors only provide generic trafficmonitoring without artificial intelligence, Dynatrace automatically analyzes DNS-related anomalies.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
Over the last two month s, w e’ve monito red key sites and applications across industries that have been receiving surges in traffic , including government, health insurance, retail, banking, and media. Monitoring with ?the The following day, a normally mundane Wednesday , traffic soared to 128,000 sessions.
In fact, according to a Dynatrace global survey of 1,300 CIOs , 99% of enterprises utilize a multicloud environment and seven cloud monitoring solutions on average. What is cloud monitoring? Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
As businesses compete for customer loyalty, it’s critical to understand the difference between real-user monitoring and synthetic user monitoring. However, not all user monitoring systems are created equal. What is real user monitoring? Real-time monitoring of user application and service interactions.
Dynatrace OneAgent is great for monitoring the full stack. While this will give you a lot of information about the health of these components, sometimes a simple synthetic monitor is sufficient. Third-party synthetic monitors. Visualize your synthetic monitor data. Easy and flexible infrastructure monitoring.
Digital experience monitoring (DEM) allows an organization to optimize customer experiences by taking into account the context surrounding digital experience metrics. What is digital experience monitoring? Primary digital experience monitoring tools.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Initial access An attacker discovers an exposed Kubernetes API server during a routine scan. Misconfiguration : Exposed API server + overly permissive RBAC settings Attacker technique : The attacker uses automated tools to authenticate as the default service account and begins reconnaissance of the cluster resources.
Picture this: A notification appears on a monitoring dashboard indicating the production Kubernetes cluster has been compromised. An attacker has gained access through security misconfigurations in an API server, escalated privileges, and deployed cryptocurrency mining pods that consume massive resources. Real-world impact.
Before GraphQL: Monolithic Falcor API implemented and maintained by the API Team Before moving to GraphQL, our API layer consisted of a monolithic server built with Falcor. A single API team maintained both the Java implementation of the Falcor framework and the API Server. To launch Phase 1 safely, we used AB Testing.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Why monitor F5 BIG-IP load balancers? That’s why monitoring every BIG-IP instance is crucial to ensure smooth operation.
A standard Docker container can run anywhere, on a personal computer (for example, PC, Mac, Linux), in the cloud, on local servers, and even on edge devices. This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. Built-in monitoring. What is Docker?
Read Also: Best PostgreSQL GUI Incremental Backups PostgreSQL 17 introduces incremental backups , a game-changer for large and high-traffic databases. Reduced Server Load: Running backups on a secondary server keeps the primary database running smoothly. What are the security and monitoring improvements in PostgreSQL 17?
In my last blog , I’ve provided an example of this happening, whereby the traffic spiked and quadrupled the usual incoming traffic. These are all interesting metrics from marketing point of view, and also highly interesting to you as they allow you to engage with the teams that are driving the traffic against your IT-system.
Such monitoring data is critical to providing satisfying digital experiences and services to customers. OpenTelemetry complements OneAgent by enabling you to: Enrich local monitoring data with project-specific additions (for example, using custom instrumentation to add business data or capture developer-specific diagnostics points).
RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. Kafka clusters can be deployed in Kubernetes using Helm charts to simplify scaling and management across multiple servers. However, performance can decline under high traffic conditions.
Complex syslog ecosystems can be challenging Monitoring devices and applications that provide output via the syslog protocol is a must-have for many organizations. These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email.
Once your cluster setup is complete, Patroni will actively monitor the cluster and ensure it’s in a healthy state. Standby Server Tests. Reboot the server. patronictl list did not display this server. Master/Primary Server Tests. Reboot the server. Test Scenario. Observation. Test Scenario.
If the primary server encounters issues, operations are smoothly transitioned to a standby server with minimal interruption. Key Takeaways PostgreSQL automatic failover enhances high availability by seamlessly switching to standby servers during primary server failures, minimizing downtime, and maintaining business continuity.
Since “hope is not a strategy” when it comes to running software services, you need to eliminate bad monitoring and instead establish an observability strategy for your services, as well as for involved third-party libraries and frameworks, that provides actionable answers instead of just more data.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
Real-time monitoring with out-of-the-box features Real-time data and monitoring are crucial for maintaining situational awareness of IT environment stability and performance, especially during a crisis. For example, a good course of action is knowing which impacted servers run mission-critical services and remediating those first.
Application servers use connection pools to maintain connections with the databases that they communicate with. New extensions enable AI-powered monitoring of connection pool performance. A traffic spike can be another root cause (for example, if a new marketing promotion drives lots of new customer traffic to your site).
Unlike other solutions on the market that force you to manually deploy and configure monitoring, Dynatrace gives you out-of-the-box service-level insights with full end-to-end traces into your microservices. This is especially important as these are the gatekeepers for all incoming and outgoing traffic. Get started.
For example, to handle traffic spikes and pay only for what they use. However, serverless applications have unique characteristics that make observability more difficult than in traditional server-based applications. Scale automatically based on the demand and traffic patterns. What are serverless applications?
As a result, it has an advantage over others in terms of visibility, brand image, and driving traffic. Web performance testing is executed, so that accurate information is provided on the application's readiness by monitoring the server-side application and testing the website. What Is Web Performance Testing?
For two decades, Dynatrace NAM—Network Application Monitoring, formerly known as DC RUM—has been successfully monitoring the user experience of our customers’ enterprise applications. All-trafficmonitoring, analysis on demand—network performance management started to grow as an independent engineering discipline.
While most government agencies and commercial enterprises have digital services in place, the current volume of usage — including traffic to critical employment, health and retail/eCommerce services — has reached levels that many organizations have never seen before or tested against. So how do you know what to prepare for?
Highlighting NewReleases For new content, impression history helps us monitor initial user interactions and adjust our merchandising efforts accordingly. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios. Minimized cross-data center network traffic. Achieve high SLOs with seamless monitoring when entire data centers experience outages. Dynatrace Premium HA allows monitoring to continue with near-zero data loss in failover scenarios.
Constantly monitoring infrastructure health state and making ongoing optimizations are essential for Ops teams, SREs (site-reliability engineers), and IT admins. Quick and easy network infrastructure monitoring. Tired of constantly switching between all your monitoring tools? Start monitoring in minutes. Virtual servers.
The monitoring challenges of on-premises environments. To keep infrastructure and bare metal servers running smoothly, a long list of additional devices are used, such as UPS devices, rack cases that provide their own cooling, power sources, and other measures that are designed to prevent failures.
This eliminates certain timeout issues with Windows Server 2019 at boot. Outage-handling settings of browser monitors and HTTP monitors can now be managed via the Settings API. You can override these at the monitor level. Real user traffic has been added to the world map on the browser monitor details page.
Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable. Possible scenarios A retail website crashes during a major sale event due to a surge in traffic. These attacks can be orchestrated by hackers, cybercriminals, or even state actors.
In the web hosting service industry, it is commonly used for balancing the HTTP traffic across multiple servers which act together as a web front-end. A Load Balancer allows the users to distribute the traffic to a single IP across several servers by using a set of different protocols. How Does a Load Balancer Work?
We use monitored demo applications to deliver constant load and a defined set of business transactions. While the first guardian validates the traffic, the second guardian checks the business transactions generated during the observation period. The functionality is implemented via an automated workflow.
IoT is transforming how industries operate and make decisions, from agriculture to mining, energy utilities, and traffic management. Mining and public transportation organizations commonly rely on IoT to monitor vehicle status and performance and ensure fuel efficiency and operational safety.
Meeting the requirements of a tier-0 application demands the highest level of reliability and scalability, which Dynatrace enables through extensive self-monitoring and self-healing across the entire application stack down to the infrastructure level. Access your cluster health data in Dynatrace Managed.
In large organizations, it’s not uncommon to have hundreds of applications — each with its own specific infrastructure requirements based on architecture, function, traffic, and more. Address monitoring at scale. To do so, developers can use monitoring as code to define, deploy, and instrument observability as they build.
For example, an attacker could exploit a misconfigured firewall rule to gain access to servers on your network. Scanning the runtime environment of your services can help to identify unusual network traffic patterns. Common vulnerability management considerations.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content