This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Let’s explore some of the advantages of monitoring GitHub runners using Dynatrace. By integrating Dynatrace with GitHub Actions, you can proactively monitor for potential issues or slowdowns in the deployment processes. The post Monitoring GitHub-hosted runners with Dynatrace appeared first on Dynatrace news.
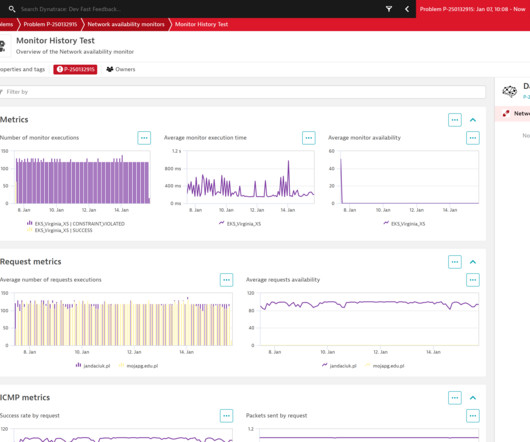
Traditional insight into HTTP monitor execution details For nearly two thousand Dynatrace customers, Dynatrace Synthetic HTTP monitors provide insights into the health of monitored endpoints worldwide and around the clock. It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors.
Fortunately, the Spring Boot framework offers a powerful observability stack that streamlines real-time monitoring and performance analysis. Diagnosing issues within complex microservice architectures can quickly become a time-consuming and daunting task.
We’re excited to announce that Dynatrace has been named a Leader in the inaugural 2024 Gartner® Magic Quadrant™ for Digital Experience Monitoring. Dynatrace digital experience monitoring (DEM) monitors and analyzes the quality of digital experiences for users across digital channels by collecting data from multiple sources.
Horizontally scalable data stores like Elasticsearch , Cassandra , and CockroachDB distribute their data across multiple nodes using techniques like consistent hashing. As nodes are added or removed, the data is reshuffled to ensure that the load is spread evenly across the new set of nodes.
Event-driven Ansible offers a way to automatically monitor and manage configuration files. Manually checking configuration files takes a lot of time, is prone to mistakes, and isnt reliable, especially in complex IT systems.
Expectations for network monitoring In today’s digital landscape, businesses rely heavily on their IT infrastructure to deliver seamless services to customers. Traditional monitoring tools often fall short of providing deep insights into network layers, leaving gaps in understanding the root causes of performance issues.
In this article, Ill walk you through an example of using Ansible to monitor and manage a Nginx web server specifically, to demonstrate how to use a URL check module to trigger a node restart playbook that will automatically start the Nginx server when a particular URL becomes unreachable.
Digital experience monitoring (DEM) is crucial for organizations to meet this demand and succeed in today’s competitive digital economy. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels. The time taken to complete the page load.
With the pace of digital transformation continuing to accelerate, organizations are realizing the growing imperative to have a robust application security monitoring process in place. What are the goals of continuous application security monitoring and why is it important?
Synthetic monitoring enhances observability by enabling proactive testing and monitoring systems to identify potential issues before they quickly impact users. Returning to the Jenga metaphor, synthetic monitoring observes the tower from a distance, from the end user’s perspective, and triggers instability warnings immediately.
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performance tuning needs. The Collector is expected to be ready for prime time in 2025, reaching the v1.0
However, with great power comes great responsibility — the responsibility to monitor and understand your Kubernetes clusters effectively. Understanding Kubernetes and KIND Before diving into the monitoring aspect, let's understand Kubernetes.
Zabbix is a universal monitoring tool that combines data collection , data visualization , and problem notification. My first encounter with this monitoring system was in 2014 when I joined a project where Zabbix was already in use for monitoring network devices (routers, switches).
Service-level objectives are typically used to monitor business-critical services and applications. However, due to the fact that they boil down selected indicators to single values and track error budget levels, they also offer a suitable way to monitor optimization processes while aligning on single values to meet overall goals.
While Docker makes it easier to execute apps, it is also critical to monitor and log your Dockerized environments to ensure they are working properly and stay safe.
Monitoring and observability are two key concepts that facilitate this process, offering valuable visibility into the health and performance of systems. In this article, we will explore the differences between monitoring and observability, provide examples to illustrate their applications and highlight their respective benefits.
Current synthetic capabilities Dynatrace Synthetic Monitoring is a powerful tool that provides insight into the health of your applications around the clock and as they’re perceived by your end users worldwide. Compared to other solutions I have tested, Dynatrace NAM monitors are the most configurable which is to my liking.
It is critical to develop good logging and monitoring practices while running workloads on AWS to ensure the health, security, and performance of your cloud-based infrastructure.
Effective logging and monitoring are critical for ensuring the performance, security, and cost-effectiveness of your Azure cloud services. Microsoft Azure is a major cloud computing platform that provides a comprehensive set of services for developing, deploying, and managing applications and infrastructure.
Monitoring business processes is one thing organizations can do to help improve the key business processes that enable them to provide great customer experiences. Business process monitoring refers to continuously tracking and analyzing key performance indicators (KPIs) from relevant process milestones.
As teams moved their deployment infrastructure to containers, monitoring and logging methods changed a lot. Storing logs in containers or VMs just doesn’t make sense – they’re both way too ephemeral for that. This is where solutions like Kubernetes DaemonSet come in. Since pods are ephemeral as well, managing Kubernetes logs is challenging.
While Docker Swarm provides strong capabilities for deploying and scaling applications, it’s also critical to monitor and report the performance and health of your Swarm clusters.
Cloud-native technologies are driving the need for organizations to adopt a more sophisticated IT monitoring approach to satisfy the competitive demands of modern business. As a result, organizations need to shift toward more sophisticated models of monitoring and managing IT operations.
Observability Integration Observability is the cornerstone of reliability and trust in any production-grade retrieval-augmented generation (RAG) pipeline.
It’s all monitored remotely ! Default dashboard for IBM I monitoring The default dashboard provides an overview of all monitored systems and how many different entities are created by IBM i components. It’s crucial to monitor the performance of these jobs, including their CPU usage, number of instances, and status.
In the dynamic world of cloud-native technologies, monitoring and observability have become indispensable. However, managing its health and performance efficiently necessitates a robust monitoring solution. Kubernetes, the de-facto orchestration platform, offers scalability and agility.
Tools for monitoring the cloud in this situation are useful. With the help of these potent tools, businesses can monitor the performance, availability, and security of their cloud resources in real-time. Tools for cloud monitoring are now indispensable allies in the management of complicated cloud environments.
Effective monitoring and troubleshooting are critical for maintaining the performance and reliability of Atlassian products like Jira and Confluence and software configuration management (SCM) tools like Bitbucket. Before we discuss the monitoring tools, let's clarify the importance of monitoring.
For more: Read the Report Agile development practices must be supported by an agile monitoring framework. This is an article from DZone's 2023 Observability and Application Performance Trend Report.
Shift-left is an approach to software development and operations that emphasizes testing, monitoring, and automation earlier in the software development lifecycle. The goal of the shift-left approach is to prevent problems before they arise by catching them early and addressing them quickly.
The urgency of monitoring these batch jobs can’t be overstated. Monitor batch jobs Monitoring is critical for batch jobs because it ensures that essential tasks, such as data processing and system maintenance, are completed on time and without errors. This blog post offers further details about DPL architect.
The cybersecurity landscape is undergoing a significant shift, moving from security tools monitoring applications running within userspace to advanced, real-time approaches that monitor system activity directly and safely within the kernel by using eBPF. The open-source project Falco exemplifies this trend.
Most business processes are not monitored. Business processes can be quite complex, often including conditional branches and loops; many business process monitoring initiatives are abandoned or simplified after attempting to map the process flow. First and foremost, it’s a data problem.
As the world becomes increasingly interconnected with the proliferation of IoT devices and a surge in applications, digital transactions, and data creation, mobile monitoring — monitoring mobile applications — grows ever more critical.
As per the saying If you dont measure it, you cant manage it by Deming , observability and monitoring is our way to measure our services. But the way containers are continuously created and destroyed can sometimes present challenges with monitoring.
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. By treating processes as assets with measurable key performance indicators (KPIs), business process monitoring helps IT and business teams align toward shared business goals.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
By automating OneAgent deployment at the image creation stage, organizations can immediately equip every EC2 instance with real-time monitoring and AI-powered analytics. This integration allows organizations to correlate AWS events with Dynatrace automatic dependency mapping, real-time performance monitoring, and root-cause analysis.
The integration of Dynatrace with Tenable Vulnerability Management and the Tenable One platform brings a comprehensive approach to vulnerability management and user activity monitoring. Monitor and detect suspicious user activity: Analyze and detect suspicious user activity within the Tenable platform.
For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline. Using a seasonal baseline, you can monitor sales performance based on the past fourteen days. For instance, in a web shop, sales might vary by day of the week.
Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications. The post Container monitoring for VA Platform One helps VA achieve workload performance appeared first on Dynatrace news.
Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics. All other default policies on the service level, for example, “AutomationEngine – User” access, are now marked as Legacy.
By providing a dedicated service layer to facilitate service discovery and how applications share information with each other, they provide security, tracing, monitoring, and traffic control. A service mesh is a pattern that aims to mitigate some of these challenges when architecting an application on Kubernetes.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content