This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Logs, metrics, and traces make up the bulk of all telemetry data. Pools the data using SDKs, and transports it for processing and exporting.
The sidecar has been implemented by leveraging the highly performant eBPF along with carefully chosen transport protocols to consume less than 1% of CPU and memory on any instance in our fleet. The choice of transport protocols like GRPC, HTTPS & UDP is runtime dependent on characteristics of the instance placement.
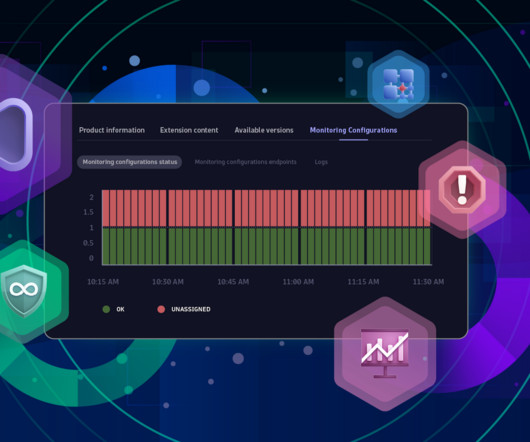
Calling it a console of transportation hubs seems reasonable, as the extension itself is only one way to get the data. Extensions bring you a load of metrics. Knowing what each metric means is crucial to selecting the most suitable ones. Monitoring configuration outages leading to metric gaps might let crucial errors slip away.
Mining and public transportation organizations commonly rely on IoT to monitor vehicle status and performance and ensure fuel efficiency and operational safety. Both methods allow you to ingest and process raw data and metrics.
It reads events from the upstream transports and applies some business logic to each of them. An intermediate processor writes data to another transport. Processors A processor is a Flink Job. It contains a reusable unit of data processing logic.
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. Speed index. How quickly visible parts of the page are rendered.
These include Source IP, destination IP, transport protocol, source port, and destination port. A full list of metrics can be found here and include dimensions such as the following: Packets. When it comes to logs and metrics, the Dynatrace platform provides direct access to the log content of all mission-critical processes.
Improve cloud platform management with deeper insights into platform metrics. Automatically monitor all important Go metrics. Upon checking the Go-specific metrics of the foxy process, a suspicious, continuous increase of goroutines can be observed. Transports should be reused instead of created as needed. Do much more.
With siloed data sources, heterogeneous data types—including metrics, traces, logs, user behavior, business events, vulnerabilities, threats, lifecycle events, and more—and increasing tool sprawl, it’s next to impossible to offer users real-time access to data in a unified, contextualized view. Understanding the context.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
The rental car : Preferring the privacy of a rental car over public transportation or Uber, I reserved a car for a short city vacation. The hotel’s rental subsidiary limits their IT monitoring to internal system metrics, with no visibility into user journeys or business transactions. The rental car company monitors user journeys.
ESG metrics are increasingly important to investors as they evaluate risk; in turn, these metrics are increasingly important to organizations because they measure and disclose their performance. The app translates utilization metrics, including CPU, memory, disk, and network I/O, into their CO2 equivalent (CO2e).
RTT data should be seen as an insight and not a metric. Note some of the counties in these URLs: this client has a truly international audience, and latency metrics are of great interest to me. Interestingly, latency only accounts for a small proportion of my overall TTFB metric. RTT isn’t a you-thing, it’s a them-thing.
Why browser and HTTP monitors might not be sufficient In modern IT environments, which are complex and dynamically changing, you often need deeper insights into the Transport or Network layers. A set of metrics allowing query results with Data Explorer and creating advanced reporting using Dynatrace Dashboards.
The rental car : Preferring the privacy of a rental car over public transportation or Uber, I reserved a car for a short city vacation. The hotel’s rental subsidiary limits their IT monitoring to internal system metrics, with no visibility into user journeys or business transactions. The rental car company monitors user journeys.
In the first part of this three-part series, The road to observability with OpenTelemetry demo part 1: Identifying metrics and traces with OpenTelemetry , we talked about observability and how OpenTelemetry works to instrument applications across different languages and platforms.
Just like shipping containers revolutionized the transportation industry, Docker containers disrupted software. An orchestration platform needs to expose data about its internal states and activities in the form of logs, events, metrics, or transaction traces. Observability.
In general, metrics collectors and providers are most common, followed by log and tracing projects. These customers are among the world’s largest 15,000 organizations from all major industries, including financial services, retail and e-commerce, technology, transportation, manufacturing, healthcare, and public-sector organizations.
This was the most important question we considered when building our infrastructure because data sampling policy dictates the amount of traces that are recorded, transported, and stored. Our trace data collection agent transports traces to Mantis job cluster via the Mantis Publish library.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can billing).
These components include schools; transportation; energy; water; and communications such as the accuracy, timeliness, and transparency of election reporting. In contrast, observability enables teams to understand a system’s internal state by analyzing the data it generates, including logs, metrics, and traces.
MQTT is an OASIS standard messaging protocol for the Internet of Things (IoT) and was designed as a highly lightweight yet reliable publish/subscribe messaging transport that is ideal for connecting remote devices with a small code footprint and minimal network bandwidth.
For example, while HTTP deals with URLs and data interpretation, Transport Layer Security (TLS) ensures security by encryption, TCP enables reliable data transport by retransmitting lost packets, and Internet Protocol (IP) routes packets from one endpoint to another across different devices in between (middleboxes). What Is QUIC?
Below is a snapshot of our Kibana dashboard which shows the workflow execution metrics over a typical 7-day period. This addition also provides the option to use the Elasticsearch RestClient instead of the Transport Client which was enforced in the previous version. Cassandra persistence module is a partial implementation.
In order to design, operate, and measure these networks, we must collect metrics and state data from the thousands of devices that compose them. The mechanisms by which the data is retrieved may not be inherently reliable (in the case of SNMP’s UDP transport) and always require active polling by the collector?—?which,
This generalized message means that device teams are able to define their own protocols on top of these messages — Pushy would just be the transport layer, happily forwarding messages back and forth. As a networking team, we naturally lean towards abstracting the communication layer with encapsulation wherever possible.
It’s why the company has racked up so many industry firsts across transportation, defense and beyond. Flow Metrics , as set out in the Flow Framework, are helping Cubic to see into their product value streams with a language that everyone can understand. Business Insights with Tasktop Viz and Flow Metrics. “If Subscribe now.
Data Quality Data Mesh provides metrics and dashboards at both the processor and pipeline level for operational observability. However, it is paramount that we validate the complete set of identifiers such as a list of movie ids across producers and consumers for higher overall confidence in the data transport layer of choice.
Encryption at both the transport level (using SSL/TLS) and message level is crucial for safeguarding data in transit and at rest, ensuring confidentiality and integrity within RabbitMQ deployments. By implementing security measures at the transport and protocol levels, RabbitMQ ensures robust safeguards are in place.
This allowed the interviewees’ organizations to seamlessly integrate their toolchains across departments and teams, generating a consistent set of Flow Metrics. hours per week by no longer needing to manually develop and report their own metrics. Product managers saved an average of 2.5
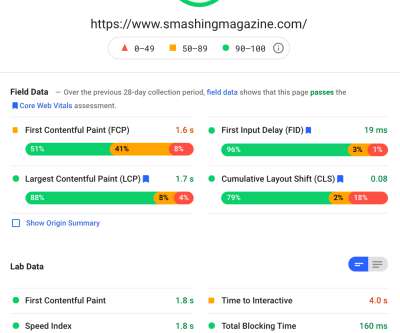
Google has announced that from 1st May, they will start to consider “Page Experience” as part of Search ranking , as measured by a set of metrics called Core Web Vitals. The Core Web Vitals are a set of three metrics designed to measure the “core” experience of whether a website feels fast or slow to the users, and so gives a good experience.
While not quite the same experience as dining in, if you close your eyes you can almost transport yourself into your favorite haunt. The below steps give you an idea of just some of the effort, time and costs that go into building a Flow Metrics solution that can scale across your portfolio and organization: . Development Team.
While not quite the same experience as dining in, if you close your eyes you can almost transport yourself into your favorite haunt. The below steps give you an idea of just some of the effort, time and costs that go into building a Flow Metrics solution that can scale across your portfolio and organization: . Development Team.
As an online booking platform, we connect travelers with transport providers worldwide, offering bus, ferry, train, and car transfers in over 30 countries. We aim to eliminate the complexity and hassle associated with travel planning by providing a one-stop solution for all transportation needs. Core Web Vital metrics definitions.
Investments in infrastructure, whether public transport or IT applications, tend to lack hard numbers because they are a means to an end and not an end in themselves. We have transport to enable people to travel to work and allow goods to reach markets. In the absence of hard measures, we concoct soft ones.
Adopting open-source standards and tools like Kubernetes lays the groundwork for creating adaptable and transportable solutions that promote application deployment and management in various cloud environments. The challenges in integration come from varying APIs, data structures, and unique deployment schemes specific to each cloud platform.
An essential component of Tasktop Hub , the Flow Fabric is the data transportation backbone between data siloes. One of the first steps in this journey was the realization that Tasktop had this information through the Flow Fabric.
Technological advancements now allow you to easily locate everything from a tiny store to a large transportation hub and even virtual explore these facilities from the inside and out. The platforms can record a host of metrics, including the number and frequency of visits, wait time, traffic hotspots, and more.
This helps support executive sponsors who then have meaningful metrics to point to in justifying the investments being made. Very rarely have we seen a team succeed that doesn’t set budgets, gather RUM metrics, and carry representative customer devices. Teams with budgets also find it easier to track and graph progress.
In order for enterprise IT to adopt this approach, this means shifting focus away from traditional project management metrics and plans towards a lean product development mindset. Managing product better to deliver faster time-to-value to the customer (instead of focusing on internal project metrics).
Relying only on high-level metrics is very dangerous because these could be skewed by a plethora of factors (such as unrealistic network emulation, a lack of features on clients or servers, only partial HTTP/3 usage, etc.). First, in part 1 , we discussed that HTTP/3 was needed mainly because of the new underlying QUIC transport protocol.
It might yet sue its way to curtailing the potential size and scope of the market that will allow for the web to actually compete, and if it succeeds in that, no amount of fast catch-up in the next few quarters will pose a true threat to native.
This difference has substantial technological implications, from the classification of what’s interesting to transport to cost-effective storage (keep an eye out for later Netflix Tech Blog posts addressing these topics). Tracing as a foundation Logs, metrics, and traces are the three pillars of observability.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content