This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here are five strategies executives can pursue to reduce tool sprawl, lower costs, and increase operational efficiency. Break data silos and add context for faster, more strategic decisions : Unifying metrics, logs, traces, and user behavior within a single platform enables real-time decisions rooted in full context, not guesswork.
Read on to learn more about how Dynatrace and Microsoft leverage AI to transform modern cloud strategies. Race to the cloud As cloud technologies continue to dominate the business landscape, organizations need to adopt a cloud-first strategy to keep pace.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. It’s about uncovering insights that move business forward. The result?
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
The COVID-19 pandemic accelerated the speed at which organizations digitally transform — especially in industries such as eCommerce and healthcare — as expectations for a great customer experience dramatically increased. Crafting a successful digital transformation strategy. ” The post What is digital transformation?
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
We can experiment with different content placements or promotional strategies to boost visibility and engagement. Analyzing impression history, for example, might help determine how well a specific row on the home page is functioning or assess the effectiveness of a merchandising strategy.
Given that 66% of all websites (and 77% of all requests ) are running HTTP/2, I will not discuss concatenation strategies for HTTP/1.1 We need to learn a little bit more about the rest of our setup before we can make a final decision about our concatenation strategy. ?️ What happens when we adjust our compression strategy?
How to improve digital experience monitoring Implementing a successful DEM strategy can come with challenges. It can help understand the flow of user interactions, identify areas for improvement, and drive a user experience strategy that better engages customers to meet their needs. Speed index. Load event start. Load event end.
Teams derive business metrics from many sources. Dynatrace Business Analytics , powered by Grail and the Dynatrace core platform technologies , aligns the goals of business and IT teams through shared context, speed, and precision to deliver the answers you need to drive better business outcomes.
Observability requires complete access to metrics, traces, and logs. Having siloed systems that only provide visibility into one or two of these sources won’t result in an effective observability strategy. OpenTelemetry is an open source standard for gathering observability signals, including metrics, traces, and logs.
And according to recent data from Enterprise Strategy Group, 59% of survey respondents indicated spending on public cloud applications would increase in 2023. The company made these changes to support its ONETractor strategy, which seeks to deliver personalized, convenient shopping experiences anytime, anywhere.
Further, automation has become a core strategy as organizations migrate to and operate in the cloud. More than 70% of respondents to a recent McKinsey survey now consider IT automation to be a strategic component of their digital transformation strategies. DevOps metrics and digital experience data are critical to this.
Annie leads the Chrome SpeedMetrics team at Google, which has arguably had the most significant impact on web performance of the past decade. It's really important to acknowledge that none of this would have been possible without the great work from Annie and her small-but-mighty SpeedMetrics team at Google.
Buckle up as we delve into the world of Redis monitoring, exploring the most important Redis metrics, discussing essential tools, and even peering into the future of Redis performance management. Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
Serverless functions extend applications to accelerate speed of innovation. Full integration with existing Dynatrace capabilities for AWS Lambda (for example, metric ingestion via AWS Cloud Watch). Fully integrated with existing Dynatrace capabilities for AWS Lambda, including metric ingestion via AWS Cloud Watch.
Customer lifetime value (CLV) has long been established as the key metric financial services firms use to gauge their profitability and competitive position in the market. It is also central to helping leaders develop best-practice strategies to attract and retain new customers.
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality.
Staying ahead of customer needs requires speed and agility from all phases of the software development life cycle (SDLC). DevOps automation tools speed up delivery cycles by reducing human error and bottlenecks, resulting in fewer and shorter feedback loops. It helps to assess the long- and short-term efficiency and speed of DevOps.
Buckle up as we delve into the world of Redis® monitoring, exploring the most important Redis® metrics, discussing essential tools, and even peering into the future of Redis® performance management. Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring.
Mastering Hybrid Cloud Strategy Are you looking to leverage the best private and public cloud worlds to propel your business forward? A hybrid cloud strategy could be your answer. Understanding Hybrid Cloud Strategy A hybrid cloud merges the capabilities of public and private clouds into a singular, coherent system.
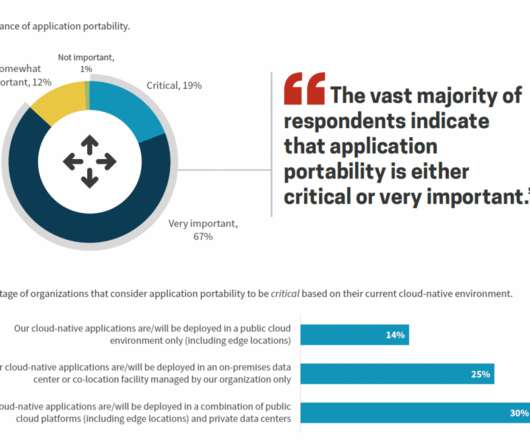
To address these challenges, organizations are adopting cloud-first strategies and cloud-native application development practices. As part of its Distributed Cloud research series , the Enterprise Strategy Group (ESG) surveyed 387 North American IT professionals responsible for managing application infrastructure.
This traditional approach presents key performance metrics in an isolated and static way, providing little or no insight into the business impact or progress toward the goals systems support. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends.
The only way to address these challenges is through observability data — logs, metrics, and traces. IT pros want a data and analytics solution that doesn’t require tradeoffs between speed, scale, and cost. Here are five steps to creating a modern data stack and AI strategy for observability, AIOps, and application security.
Dynatrace is fully committed to the OpenTelemetry community and to the seamless integration of OpenTelemetry data , including ingestion of custom metrics , into the Dynatrace open analytics platform. To address these types of challenges, organizations typically introduce third-party libraries and frameworks like Hazelcast IMDG.
Reducing downtime, improving user experience, speed, reliability, and flexibility, and ensuring IT investments are delivering on promised ROI across local IT stacks and in the cloud. ” Here, collecting metrics and monitoring performance help evaluate the efficacy of services rather than simply identifying their state.
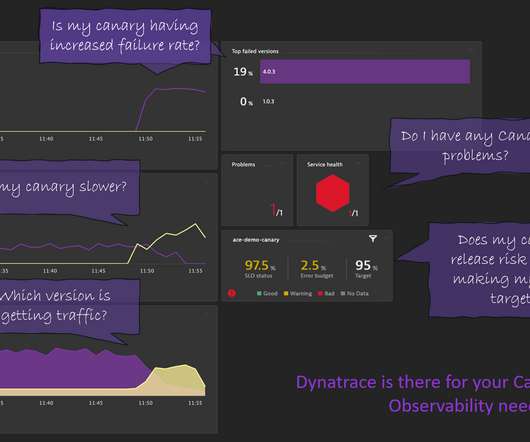
Progressive Delivery enables speeding up while managing the risk of software deployments and configuration changes. One of the aspects of progressive delivery is using new zero-downtime deployment strategies such as Canary, Blue-Green, or Feature Flags. Having metrics with version information, e.g, Dynatrace news. Step 3: SLOs.
Digital transformation is only going to speed up, not slow down, and companies must remain on top of it. The speed of change is only going to accelerate, thus requiring more innovation. Observability is inherent to any cloud strategy. The culmination of all this is pressuring organizations on multiple fronts.
These criteria include operational excellence, security and data privacy, speed to market, and disruptive innovation. Ally is an agile, modern financial services enterprise that has etched unified observability, AI, and analytics into the core of its cloud strategy. This resulted in significant savings and much faster ROI.
In this article, we explore recent survey data from Enterprise Strategy Group (ESG), sponsored by Dynatrace, on how organizations approach IT automation, as well as the benefits and challenges they encounter as they adopt it. And for DevOps, it means accelerating DevOps processes, improving agility, and speeding time to market.
We asked hundreds of developers, engineers, software architects, dev teams, and IT leaders at DeveloperWeek to discover the current NoSQL vs. SQL usage, most popular databases, important metrics to track, and their most time-consuming database management tasks. Most Important Metric Tracked For Database Performance. How much so?
RUM gathers information on a variety of performance metrics. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed).
As organizations look to speed their digital transformation efforts, automating time-consuming, manual tasks is critical for IT teams. But AIOps also improves metrics that matter to the bottom line. Create a cloud observability strategy with automatic and intelligent AIOps. Dynatrace news.
With its exchange feature, RabbitMQ enables advanced routing strategies, making it well-suited for workflows that require controlled message flow and guaranteed delivery. Kafkas proprietary protocol is optimized for high-speed data transfer, ensuring minimal latency and efficient message distribution.
Because Google offers its own Google Cloud Architecture Framework and Microsoft its Azure Well-Architected Framework , organizations that use a combination of these platforms triple the challenge of integrating their performance frameworks into a cohesive strategy. which shows your operational efficiency in your software delivery pipeline.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
With multiple iterations, the team arrived at a recipe that significantly speeds up the encoding with negligible compression efficiency changes. Besides speeding up the encoder, the total CPU hours could also be reduced if we can use compute resources more efficiently. Challenge 4: How do we continuously monitor AV1 streaming?
As a result, they may fail to consider the importance of full-stack observability, dashboards, AI-driven automation, application security, and other factors when designing their security operations strategy. Telemetry data — such as metrics, logs, and traces — gives IT teams crucial context to understand how all entities are connected.
Streamline development and delivery processes Nowadays, digital transformation strategies are executed by almost every organization across all industries. Thus, Site Reliability Guardian supports DevOps and SREs in speeding up release delivery and improving release quality.
Deployment Strategies We are all familiar with the advantages of releasing frequently and in smaller chunks. Depending on the type of client, we need to determine the right strategy to sample consumer devices, and provide a system that can enable various client engineering teams to look for their signals.
Artificial intelligence for IT operations, or AIOps, combines big data and machine learning to provide actionable insight for IT teams to shape and automate their operational strategy. The deviating metric is response time. A huge advantage of this approach is speed. SecOps: Applying AIOps to secure applications in real time.
In the past, the answer would be based on the load time of a page, but over the years, we have evolved our approach to site speed to incorporate new metrics, alone or in combination with existing metrics. The next evolution of performance brought in paint metrics. This is where so-called interactivity metrics come in.
Modern observability has evolved from simple metric telemetry monitoring to encompass a wide range of data, including logs, traces, events, alerts, and resource attributes. This is why precisely showing the root cause ultimately helps to speed up problem resolution. CPU throttling root cause shown in Kubernetes context.
This integrated approach represents significant time savings, drastically reducing MTTI and speeding mean time to resolution (MTTR). In a unified strategy, logs are not limited to applications but encompass infrastructure, business events, and custom metrics. Set up processing rules. and/or its affiliates in the U.S.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content