This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you. For our example dashboard, we’ll only focus on some selected key infrastructure metrics. Click on Select metric. Change it now to sum.
Time To First Byte: Beyond Server Response Time Time To First Byte: Beyond Server Response Time Matt Zeunert 2025-02-12T17:00:00+00:00 2025-02-13T01:34:15+00:00 This article is sponsored by DebugBear Loading your website HTML quickly has a big impact on visitor experience. But actually, theres a lot more to optimizing this metric.
Metrics that offer measurable, repeatable insight into the user experience from the moment they arrive on a website from a mobile or desktop device. Great user experiences start with Core Web Vitals (CWVs) — a set of metrics defined by Google to help measure user experience at scale. When do these metrics matter?
These events are promptly relayed from the client side to our servers, entering a centralized event processing queue. We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression. This queue ensures we are consistently capturing raw events from our global userbase.
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. Speed index. Time to render. Visually complete. HTML downloaded.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
framework , the SNMP extensions are a bundle of everything that’s needed (DataSource configuration, a dashboard template, a unified analysis page template, topology definition, entity extraction rules, relevant metric definitions and more) to get going with monitoring. Virtual servers. Pool nodes. Interfaces.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical servermetrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
As businesses increasingly embrace these technologies, integrating IoT metrics with advanced observability solutions like Dynatrace becomes essential to gaining additional business value through end-to-end observability. Both methods allow you to ingest and process raw data and metrics.
However, if you’re an operations engineer who’s been tasked with migrating to HANA from a legacy database system, you’ll need to get up to speed quickly. Enable the Davis AI causation engine to automatically analyze every metric. No agent installation is required on your SAP server.
However, one metric I feel that front-end developers overlook all too quickly is Time to First Byte (TTFB). A lot of people surmise that TTFB is merely time spent on the server, but that is only a small fraction of the true extent of things. can all provide valuable insights. Expect closer to 75ms. It all gets added to your TTFB.
Kafka clusters can be deployed in Kubernetes using Helm charts to simplify scaling and management across multiple servers. Kafkas proprietary protocol is optimized for high-speed data transfer, ensuring minimal latency and efficient message distribution. This allows Kafka clusters to handle high-throughput workloads efficiently.
Answering Common Questions About Interpreting Page Speed Reports Answering Common Questions About Interpreting Page Speed Reports Geoff Graham 2023-10-31T16:00:00+00:00 2023-10-31T17:06:18+00:00 This article is sponsored by DebugBear Running a performance check on your site isn’t too terribly difficult. But it comes with caveats.
As I see it, there are two main issues when it comes to measuring performance changes (note, not improvements , but changes) in the lab: Site-speed is nondeterministic 1. As noted above, it’s not actually possible to improve certain metrics in their own right. There are myriad reasons for this that I won’t cover here. duration ).
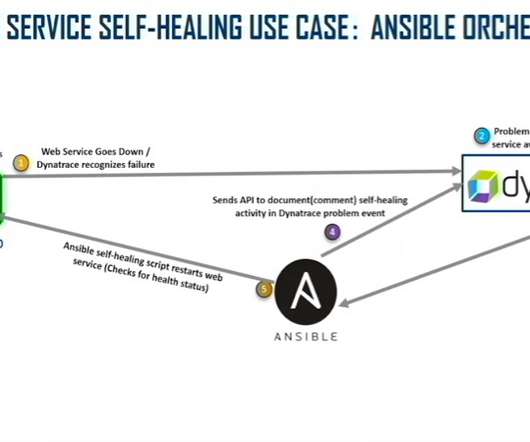
At Dynatrace Perform 2022 , David Walker, a Lockheed Martin Fellow, and William Swofford, a full-stack engineer at Lockheed Martin, discuss how to create a self-diagnosing and self-healing IT server environment using this AIOps combination for auto-baselining, auto-remediation, monitoring as code, and more. An example of the self-healing web.
The only way to address these challenges is through observability data — logs, metrics, and traces. IT pros want a data and analytics solution that doesn’t require tradeoffs between speed, scale, and cost. Your key business objectives will drive your strategy and metrics. But it doesn’t stop there.
We asked hundreds of developers, engineers, software architects, dev teams, and IT leaders at DeveloperWeek to discover the current NoSQL vs. SQL usage, most popular databases, important metrics to track, and their most time-consuming database management tasks. Most Important Metric Tracked For Database Performance. of responses!
Looking at our overall data set, we saw a small increase in some key metrics and performance indicators, but this wasn’t substantial. . It instantly uncovered a variety of client-side , browser – based Javascript errors (1,700+ per minute) as well as multiple 404 errors on its backend content server.
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. Without seeing syslog data in the context of your infrastructure, metrics, and transaction traces, you’re slowed down by manual work with siloed data.
Endpoints include on-premises servers, Kubernetes infrastructure, cloud-hosted infrastructure and services, and open-source technologies. A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. See observability in action!
IBM i, formerly known as iSeries, is an operating system developed by IBM for its line of IBM i Power Systems servers. Messages overview Monitor disks and disk pool utilization One of the most important functions of your mainframe infrastructure is reading and writing data at high speeds while making it readily available.
It’s true that what might be considered the “most important” or “best” web performance metrics can vary by industry. These six metrics were not chosen at random – they work together to give you a snapshot of your site’s performance and overall user experience so you can set a baseline and improve speed and usability.
Effective application development requires speed and specificity. Cloud providers then manage physical hardware, virtual machines, and web server software management. This code is then executed on remote servers in response to an event, such as users interacting with functional web elements. Dynatrace news.
If you have a distributed environment with multiple servers hosting your webservers, app servers, and database, I suggest you install the OneAgent on all these servers to get full end-to-end visibility. This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
Concatenating our files on the server: Are we going to send many smaller files, or are we going to send one monolithic file? Connection One thing we haven’t looked at is the impact of network speeds on these outcomes. Larger files compress much more effectively and thus download faster at all connection speeds.
As a result, site reliability has emerged as a critical success metric for many organizations. Microservices-based architectures and software containers enable organizations to deploy and modify applications with unprecedented speed. The following three metrics are commonly used to measure success: Service-level agreements (SLAs).
Put another way, file-size savings help you to cram data into lower bandwidth, but if you’re latency-bound, the speed at which those admittedly fewer chunks of data arrive will not change. Taking a very reductive and simplistic view of how files are transmitted from server to client, we need to look at TCP. packet loss).
But this is hard to achieve at scale: Development teams need specific insights into the microservices they are responsible for, reflecting particular metrics, dashboards, custom alerts, service-level objectives (SLOs), or even automatic remediation steps. , or “Did the last update cause the application issue or was it something else?”
RUM gathers information on a variety of performance metrics. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed).
Making applications observable—relying on metrics, logs, and traces to understand what software is doing and how it’s performing—has become increasingly important as workloads are shifting to multicloud environments. We also introduced our demo app and explained how to define the metrics and traces it uses.
The complexity of such deployments has accelerated with the adoption of emerging, open-source technologies that generate telemetry data, which is exploding in terms of volume, speed, and cardinality.
In contrast, a server application runs on servers which are typically identical and a routing abstraction can serve sampled traffic to new versions. And the signals to evaluate a new version are derived from comparatively few thousands of homogenous servers instead of millions of heterogeneous devices.
Observability analytics enables users to gain new insights into traditional telemetry data such as logs, metrics, and traces by allowing users to dynamically query any data captured and to deliver actionable insights. Metrics-based performance thresholds. What is observability analytics?
While speeding up development processes and reducing complexity does make the lives of Kubernetes operators easier, the inherent abstraction and automation can lead to new types of errors that are difficult to find, troubleshoot, and prevent. Metrics are a numeric representation of intervals over time.
The roles and responsibilities of ITOps team members include the following: A system administrator configures servers, installs applications, monitors the health of the system, and fixes and upgrades hardware. This includes response time, accuracy, speed, throughput, uptime, CPU utilization, and latency. Reliability. Performance.
With OneAgent installed on an application server, Davis, the Dynatrace AI causation engine, continuously analyzes all database statements within the context of your applications. With additional data from the database server, you’ll be able to resolve performance problems that are rooted deep in the database layer.
Dynatrace is fully committed to the OpenTelemetry community and to the seamless integration of OpenTelemetry data , including ingestion of custom metrics , into the Dynatrace open analytics platform. To address these types of challenges, organizations typically introduce third-party libraries and frameworks like Hazelcast IMDG.
It’s one of the most frequently asked questions I see asked, “I’ve tested my site speed, so now what do these metrics mean?” Here we’ll explain what each of the common web performance metrics mean, and how can you use that data to optimize your site and make it faster. Standard Website SpeedMetrics.
This increased automation, resilience, and efficiency helps DevOps teams speed up software delivery and accelerate the feedback loop — ultimately allowing them to innovate faster and more confidently. The deviating metric is response time. A huge advantage of this approach is speed. This is now the starting node in the tree.
These sets of tools are acquiring one or more different types of raw data (metrics, logs, traces, events, code-level details…) at various granularity, process them and create alerts (a threshold or learned baseline was breached, a certain log pattern occurred and so forth). Another huge advantage of that approach is speed.
Provide metrics for improved site reliability. It examines metrics like response times, application programming interface availability, and page load times to flag problems that affect the user experience. The Dynatrace platform also enables teams to monitor logs generated by applications, servers, and infrastructure components.
RTT data should be seen as an insight and not a metric. Note some of the counties in these URLs: this client has a truly international audience, and latency metrics are of great interest to me. Interestingly, latency only accounts for a small proportion of my overall TTFB metric. RTT isn’t a you-thing, it’s a them-thing.
Web performance metrics track the efficiency (or lack thereof) of any individual aspect of your website’s performance. Once you have started collecting some of these must-track web performance metrics for your website, inefficiencies will become clearer. Top 10 Web Perf Metrics to Track. Time to First Byte.
Measuring Performance With Server Timing. Measuring Performance With Server Timing. Without being able to measure the speed at which something is working, we can’t tell if the changes being made are improving the performance, having no effect, or even making things worse. That issue is slow server response times.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content