This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For gaining maximum benefits out of automation testing , testers require hands-on experience in a minimum of one automation programming language. There are numerous programming languages available today, with new ones continuously emerging. Which Automation Programming Language Is the Best for Testing?
Full integration with existing Dynatrace capabilities for AWS Lambda (for example, metric ingestion via AWS Cloud Watch). Fully integrated with existing Dynatrace capabilities for AWS Lambda, including metric ingestion via AWS Cloud Watch. Before you begin, be sure to sign-up for the Preview program. Set up in 3 easy steps.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
Welcome to the blog series where we give you a deeper dive into the latest awesomeness around Dynatrace : how we bring scale, zero configuration, automatic AI driven alerting, and root cause analysis to all your custom metrics, including open source observability frameworks like StatsD, Telegraf, and Prometheus.
"Employing these Metrics to excel the performance of code directly impacts the profitability of the business. Achieving high-quality standards ultimately increases the ROI of the software. Consider it as a matter of choosing between investing excess time as well as resources initially or wasting the same later in fixing issues".
Finally, Dynatrace requires metrics data to be sent with delta temporality , not cumulative temporality. This means that youll need to include the cumulativetodelta processor in: Your Collector configuration ( cumulativetodelta ) Your metrics pipeline ( pipelines.metrics ) Never store your Dynatrace token and tenant name in plain text.
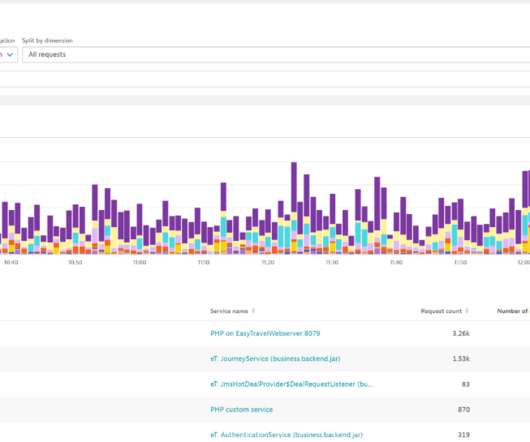
In an existing application landscape, however, it can be difficult to get to those metrics. A larger financial institution is using the analysis to report business metrics on dashboards and make them accessible via the Dynatrace API. Optimize your application and business performance by analyzing request- and service-based metrics.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough.
Because it includes examples of 10 programming languages that OpenTelemetry supports with SDKs, the application makes a good reference for developers on how to use OpenTelemetry. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
In a software system, in order to acquire observability, we mainly implement the following aspects: logging, metrics, and tracing. Observability is the ability to understand the internal state of your system by looking at what is happening externally.
The DORA metrics are pretty much an iceberg, with the five indicators sticking out above the surface and plenty of research hidden beneath the waves. With the amount of work that has been put into that program, the whole thing can seem fairly opaque when you start working with them.
Are you applying AI to the unique metrics and KPIs that matter most to the success of your digital business? Do you provide dashboards and analytics that combine technical and business metrics that are specific to your business? Dynatrace out-of-the-box metrics generally focus on availability, failure rate, and performance.
For example, you might be using: any of the 60+ StatsD compliant client libraries to send metrics from various programming languages directly to Dynatrace; any of the 200+ Telegraf plugins to gather metrics from different areas of your environment; Prometheus, as the dominant metric provider and sink in your Kubernetes space.
The report also reveals the leading programming languages practitioners use for application workloads. are the top 3 programming languages for Kubernetes application workloads. In general, metrics collectors and providers are most common, followed by log and tracing projects. are the top Kubernetes programming languages.
To emit a run queue latency metric, we leveraged three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch. kfuncs are kernel functions that can be called from eBPF programs. These functions ensure that our eBPF program remains safe and efficient while retrieving the cgroup ID from the task struct.
In addition to automatic full-stack monitoring, Dynatrace provides comprehensive support for all AWS services that publish metrics to Amazon CloudWatch, providing advanced observability for dynamic hybrid clouds. The AWS Service Ready Program was established to support the seamless integration and deployment of AWS services.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. Many technologies expose their metrics in the Prometheus data format. Easily gain actionable insights with the Dynatrace Extension for Prometheus metrics. Prometheus in Kubernetes ?and
Monitoring , by textbook definition, is the process of collecting, analyzing, and using information to track a program’s progress toward reaching its objectives and to guide management decisions. Monitoring focuses on watching specific metrics. Here’s a closer look at logs, metrics, and distributed traces.
US Paycheck Protection Program. To keep the US economy going, and avoid catastrophic impacts on people’s livelihoods and lives, the US government quickly deployed a program to deliver half a trillion dollars to small businesses. The scale and speed of the program triggered challenges for these banks that they had never before imagined.
When an incident occurs, developers need to know what data to look at, where the incident occurred, and other relevant metrics. In this example, Grabner saw that the adservice workload was running on EKS and could see the relevant metrics, logs, services, events, error logs, and more. Laifenfeld used a to-do list app as an example. “I
Today, AWS Compute Optimizer has expanded its metric ingest beyond Cloudwatch, which will be announced at the Amazon re:Invent 2022 conference in Las Vegas November 28-December 2. AWS Compute Optimizer now includes third-party metrics to further power user insights surrounding memory usage in Amazon Elastic Cloud Compute (EC2) Instances.
You’ll learn how to create production SLOs, to continuously improve the performance of services, and I’ll guide you on how to become a champion of your sport by: Creating calculated metrics with the help of multidimensional analysis. The training program to proactively improve your services. Metric 2: number of requests in error.
Dynatrace Mission Control collects the health monitoring observability metrics for both our Dynatrace SaaS as well as Dynatrace Managed customers. Metrics are provided for general host info like CPU usage and memory consumption, OneAgent traffic, and network latency. Currently, only metrics for individual nodes are available.
As an example, let’s start with the waveform of a program, shown below in Figure 1. Example program waveform To measure a program’s dynamic range, we break the waveform into short segments, such as half-second intervals, and compute the RMS level of each segment in dBFS. or when switching to any other program.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
With the release of Dynatrace 1.194, we’ve added CPU related infrastructure metrics for LPARs (host metrics) and regions (process metrics) and expanded our multidimensional analysis to IBM Z systems, including CICS, IMS, and the CICS transaction gateway. . This metric helps you to understand your current workload.
UK Home Office: Metrics meets service The UK Home Office is the lead government department for many essential, large-scale programs. When the UK Home Office first shut down these programs, the artificial intelligence-based tools had to adapt to the environment disappearing overnight.
Using environment automation from both AWS and Dynatrace, supported by the AWS Infrastructure Event Management program , Dynatrace University successfully delivered the required environments – these were three times more than the conference the year before. AWS Infrastructure Event Management program. Quite impressive!
These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards. Agentless monitoring, on the other hand, communicates directly with application programming interfaces (APIs). Identify key performance metrics specific to an organization.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
As organizations adopt more cloud-native technologies, observability data—telemetry from applications and infrastructure, including logs, metrics, and traces—and security data are converging. Let’s explore how a log auditing and log forensics program can benefit from the convergence of observability and security data. Incomplete.
Amplify PowerUP, our half-yearly global event to update our partner community, covered a lot of ground including key Partner Program announcements, Q2 earnings and partner contribution, market growth and momentum, Dynatrace platform capabilities, and the partner services offering the platform powers. Dynatrace news.
Then, they can split these services into functional application programming interfaces (APIs), rather than shipping applications as one large, collective unit. Microservice design patterns allow developers to use their preferred programming language or framework, which helps to prevent employee churn and the need for outsourced talent.
OpenTelemetry provides a set of vendor-agnostic application program interfaces (APIs) to create a common way to instrument applications and collect data from logs and traces across a wide variety of frameworks and languages. It uses standardized application program interfaces that a wide variety of vendors and user organizations can support.
Because it includes examples of 10 programming languages OpenTelemetry supports with SDKs, the application makes a good reference for developers on how to use OpenTelemetry. Jaeger and Prometheus backends for displaying the collected traces and metrics, but you can easily configure alternative backends. Dynatrace metrics exporter ?
If your customers don’t know what’s slowing them down, or why their Agile and DevOps transformations are hitting a wall, then the Flow Partner Program is for you. Now, with the revitalized Flow Partner Program , our partners can access the very latest solutions and training to enjoy the same success. . About the Flow Partner Program.
Most metrics are not atomic: FCP, for example, isn’t a metric we can optimise in isolation—it’s a culmination of other more atomic metrics such as connection overhead, TTFB, and more. As noted above, it’s not actually possible to improve certain metrics in their own right. mark ( ' HEAD Start ' ); performance. duration ).
ESG metrics are increasingly important to investors as they evaluate risk; in turn, these metrics are increasingly important to organizations because they measure and disclose their performance. The app translates utilization metrics, including CPU, memory, disk, and network I/O, into their CO2 equivalent (CO2e).
achieve application programming interface (API)-driven development. The following screenshot illustrates a scenario of an IT setup of z/OS Connect Enterprise Edition connecting to IMS programs. Additional infrastructure metrics. build microservices-based architecture. Java Message Service (JMS) interface tracing.
Although these COBOL applications operate with consistent performance, companies and governments are forced to transform them to new platforms and rewrite them in modern programming languages (like Java) for several reasons. Metrics for WebSphere Application Server and WebSphere Liberty. JDBC database connections. JMS messaging.
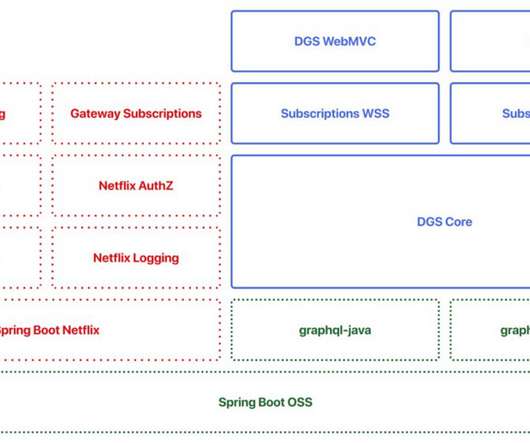
This framework was initially intended to be internal only, focusing on integration with the Netflix ecosystem for tracing, logging, metrics, etc. The Framework in Action The framework’s core revolves around the annotation-based programming model familiar to Spring Boot developers. The framework takes care of all the heavy lifting.
Telemetry data — such as metrics, logs, and traces — gives IT teams crucial context to understand how all entities are connected. Without appropriate context, the so-called pillars of observability — metrics, logs, and traces — are simply sources of data, not insights. These are not only numerous but also dynamic.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content