This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performance tuning needs. Semantic Conventions, or semconv, are the standard that makes it all possible.
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. So, stay tuned for more enhancements and features.
With the most important components becoming release candidates , Dynatrace now supports the full OpenTelemetry specification on all runtimes and automatically adds intelligence to metrics at enterprise scale. So these metrics are immensely valuable to SRE and DevOps teams. Automation and intelligence for metrics at enterprise scale.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Your next challenge is ensuring your DevOps processes, pipelines, and tooling meet the intended goal. Lead time for changes helps teams understand how effective their processes are.
This challenge has given rise to the discipline of observability engineering, which concentrates on the details of telemetry data to fine-tune observability use cases. To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. Enterprise-grade observability for custom OpenTelemetry metrics from AWS. Dynatrace news.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? Option 1: Log Processing Log processing offers a straightforward solution for monitoring and analyzing title launches.
As the application owner of an e-commerce application, for example, you can enrich the source code of your application with domain-specific knowledge by adding actionable semantics to collected performance or business metrics. New OpenTelemetry metrics exporters provide the broadest language support on the market.
The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
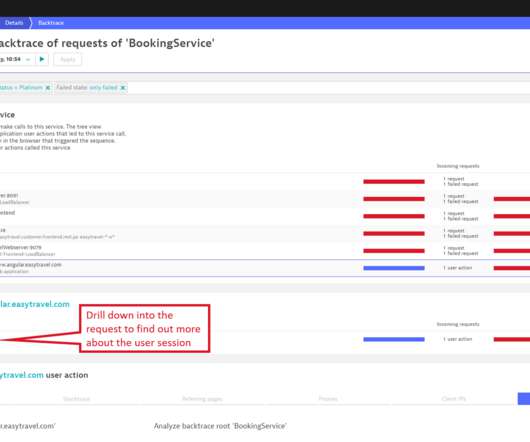
Select a Metric and Aggregation to get started. You can choose any standard Dynatrace metric and any request attribute. Simply switch the metric to Failure rate to find out if there was an error that might have impacted your platinum customers. You might guess that the relatively long booking time is caused by a failure.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
To provide you with more value when monitoring hosts in infrastructure mode, we’re extending our infrastructure mode with a range of metrics that have until now only been available in full-stack mode. Monitor additional metrics. All of these metrics are now part of infrastructure mode. How to get access. initiative.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
In my last post , I started to outline the process I go through when tuning queries – specifically when I discover that I need to add a new index, or modify an existing one. Once we have that data, we can move on to the next steps in the process. Once we have that data, we can move on to the next steps in the process.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This technique facilitates validation on multiple fronts.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
Proper setup involves creating a configuration process that accounts for hostname changes, which could prevent nodes from rejoining the cluster. Message load balancing guarantees that messages are processed evenly across different queues and nodes within the RabbitMQ system. Erlang is the backbone of RabbitMQ clustering.
Open-source metric sources automatically map to our Smartscape model for AI analytics. We’ve just enhanced Dynatrace OneAgent with an open metric API. Here’s a quick overview of what you can achieve now that the Dynatrace Software Intelligence Platform has been extended to ingest third-party metrics. Dynatrace news.
VMAF is a video quality metric that Netflix jointly developed with a number of university collaborators and open-sourced on Github. One aspect that differentiates VMAF from other traditional metrics such as PSNR or SSIM, is that VMAF is able to predict more consistently across spatial resolutions, across shots, and across genres (for example.
Defining a comprehensive user-experience metric gives rise to questions such as: How do we compare the user experience of one session to another? Which metric can be used for the purpose of reporting user experience and tracking it over a period of time? A single metric for user experience segmentation. Error metrics.
This process, known as auto-adaptive thresholding, eliminates the need to define a static threshold upfront. The training times and other quality metrics, such as the RMSE (Root Mean Squared Error), SMAPE (Scaled Mean Absolute Percentage Error), and coverage probability, are monitored using Dynatrace.
Berkeley Packet Filter (BPF) is an in-kernel execution engine that processes a virtual instruction set, and has been extended as eBPF for providing a safe way to extend kernel functionality. The Flow Exporter also publishes various operational metrics to Atlas. What is BPF? So how do we ingest and enrich these flows at scale ?
Using OpenTelemetry, developers can collect and process telemetry data from applications, services, and systems. Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. Many technologies expose their metrics in the Prometheus data format. Easily gain actionable insights with the Dynatrace Extension for Prometheus metrics. Prometheus in Kubernetes ?and
Event Prioritization Considering the use cases were wide ranging both in terms of their sources and their importance, we built segmentation into the event processing. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
Are you applying AI to the unique metrics and KPIs that matter most to the success of your digital business? Do you provide dashboards and analytics that combine technical and business metrics that are specific to your business? Dynatrace out-of-the-box metrics generally focus on availability, failure rate, and performance.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
Replay traffic testing gives us the initial foundation of validation, but as our migration process unfolds, we are met with the need for a carefully controlled migration process. A process that doesn’t just minimize risk, but also facilitates a continuous evaluation of the rollout’s impact.
To stay tuned, keep an eye on our release notes. Remediation tracking now enables you to view the risk assessment for the process groups affected by a vulnerability. Reintroduced a limit of 100,000 process group instances (last 72h) running on hosts presented on the “Deployment status” page for OneAgents. (APM-370529).
The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. The goal is to turn more data into insights so the whole organization can make data-driven decisions and automate processes. Grail can store and process 1,000 petabytes per day,” Greifeneder explains.
Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics. Higher variance means a less stable metric across pages. I can see from the screenshot above that TTFB is my most stable metrics—no one page appears to have particularly expensive database queries or API calls on the back-end.
To provide “quality signals that are essential to delivering a great user experience on the web,” Google introduced their Core Web Vitals initiative last year, advocating the Largest contentful paint , Cumulative layout shift , and First input delay metrics. with: Aggregated field metrics?rather?than?valuable?details
Synthetic Minority Over-sampling Technique Evaluation Metrics For evaluating the performance of the anomaly detection models we consider a set of evaluation metrics and report their values. For the one-class as well as binary anomaly detection task, such metrics are accuracy, precision, recall, f0.5,
UK Home Office: Metrics meets service The UK Home Office is the lead government department for many essential, large-scale programs. In this episode, Dimitris discusses the many different tools and processes they use. Make sure to stay connected with our social media pages. Tag us with #TechTransforms to be featured on our pages!
A metric crossed a threshold. You’re half awake and wondering, “Is there really a problem or is this just an alert that needs tuning? Telltale learns what constitutes typical health for an application, no alert tuning required. Metrics are a key part of understanding application health. Client metrics and QoE changes.
What about correlated trace data, host metrics, real-time vulnerability scanning results, or log messages captured just before an incident occurs? Stay tuned for even wider support of log data embedded seamlessly into the context of Dynatrace Apps, and better ways to get answers from logs without writing queries.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
Host performance is tracked via high-level health metrics on the home dashboard to details for each of the hosts. For details on available metrics, see our help page on host performance monitoring. Network measurements with per-interface and per-process resolution. Network metrics are also collected for detected processes.
Modern infrastructure needs to be elastic and GitOps approaches are used to automate the provisioning of infrastructure and applications using Git, an open-source control system that provides the change processes including reviews and approvals. Key components of GitOps are declarative infrastructure as code, orchestration, and observability.
Tracking changes to automated processes, including auditing impacts to the system, and reverting to the previous environment states seamlessly. The ultimate goal of each of these reviews is to identify gaps, quantify risk, and develop recommendations for improving the team, processes, and architecture with each of the five pillars.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content