This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
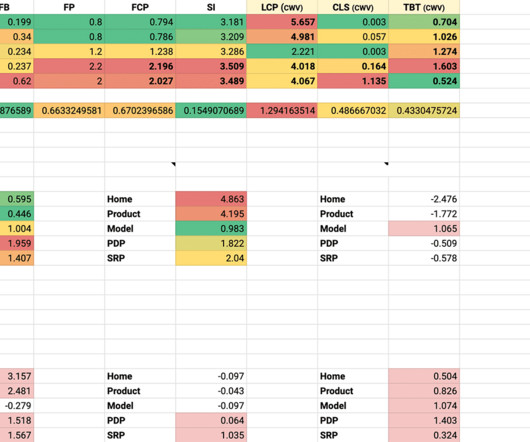
When first working on a new site-speed engagement, you need to work out quickly where the slowdowns, blindspots, and inefficiencies lie. Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics. Higher variance means a less stable metric across pages. Visualising the Data.
In an attempt to hold their place within the market, developers are having to speed their process up whilst delivering products of ever-increasing quality. Often speed and quality seem at odds with one another, but in reality, this isn’t the case. In 2019, according to Evans Data Corporation, there were 23.9
While increasing both the precision and the recall of our secrets detection engine, we felt the need to keep a close eye on speed. In a gearbox, if you want to increase torque, you need to decrease speed. So it wasn’t a surprise to find that our engine had the same problem: more power, less speed.
Automating quality gates is ideal, as it minimizes manually checking and validating key metrics throughout the SDLC. By actively monitoring metrics such as error rate, success rate, and CPU load, quality gates instill confidence in teams during software releases. Several tools can be used to collect metrics in load/performance testing.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
Speed, UX, availability, and frequency of updates are increasingly important with mobile apps. But this process usually takes a couple of weeks. Consumers and enterprises alike expect more from software. During that time, users can get frustrated with performance issues making them more likely to leave a bad review in the app store.
We often dwell on the technical aspects of database selection, focusing on performance metrics , storage capacity, and querying capabilities. The New Decision Matrix: Beyond Performance Metrics Performance metrics are pivotal, no doubt. Factors like read and write speed, latency, and data distribution methods are essential.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
This is an update to my 2020 article Site-Speed Topography. Around two and a half years ago, I debuted my Site-Speed Topography technique for getting broad view of an entire site’s performance from just a handful of key URLs and some readily available metrics. What Is Site-Speed Topography? Are any metrics over budget?
VMAF is a video quality metric that Netflix jointly developed with a number of university collaborators and open-sourced on Github. One aspect that differentiates VMAF from other traditional metrics such as PSNR or SSIM, is that VMAF is able to predict more consistently across spatial resolutions, across shots, and across genres (for example.
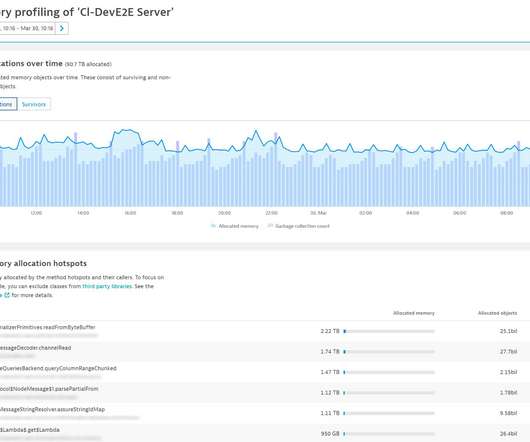
Garbage collection is slow if most objects survive the collection process. Any significant reduction in allocations will inevitably speed up your code. You can easily see this in Dynatrace: From any Host page, select a Process page. To see why, navigate to the Suspension chart on the JVM metrics tab. .
We’re able to help drive speed, take multiple data sources, bring them into a common model and drive those answers at scale.”. With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes.
These technologies are poorly suited to address the needs of modern enterprises—getting real value from data beyond isolated metrics. Further, it builds a rich analytics layer powered by Dynatrace causational artificial intelligence, Davis® AI, and creates a query engine that offers insights at unmatched speed. Thus, Grail was born.
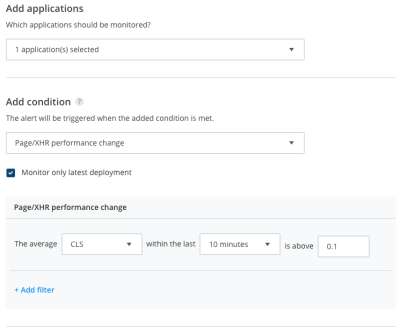
Metrics that offer measurable, repeatable insight into the user experience from the moment they arrive on a website from a mobile or desktop device. Great user experiences start with Core Web Vitals (CWVs) — a set of metrics defined by Google to help measure user experience at scale. When do these metrics matter?
The scale and speed of the program triggered challenges for these banks that they had never before imagined. Speed up loan processing to deliver critically needed relief to small businesses? Full speed ahead. How can we… Scale to previously unheard-of loan volumes? Adapting to change.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
As businesses increasingly embrace these technologies, integrating IoT metrics with advanced observability solutions like Dynatrace becomes essential to gaining additional business value through end-to-end observability. Both methods allow you to ingest and process raw data and metrics.
IT pros need a data and analytics platform that doesn’t require sacrifices among speed, scale, and cost. Therefore, many organizations turn to a data lakehouse, which combines the flexibility and cost-efficiency of a data lake with the contextual and high-speed querying capabilities of a data warehouse. What is a data lakehouse?
Serverless functions extend applications to accelerate speed of innovation. Full integration with existing Dynatrace capabilities for AWS Lambda (for example, metric ingestion via AWS Cloud Watch). Fully integrated with existing Dynatrace capabilities for AWS Lambda, including metric ingestion via AWS Cloud Watch.
As a result, site reliability has emerged as a critical success metric for many organizations. Microservices-based architectures and software containers enable organizations to deploy and modify applications with unprecedented speed. The following three metrics are commonly used to measure success: Service-level agreements (SLAs).
This traditional approach presents key performance metrics in an isolated and static way, providing little or no insight into the business impact or progress toward the goals systems support. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends.
The second major concern I want to discuss is around the data processing chain. metrics) but it’s just adding another dataset and not solving the problem of cause-and-effect certainty. The four stages of data processing. Four stages of data processing with a costly tool switch.
Achieving the ideal state with aggregated, centralized log data, metrics, traces , and other metadata is challenging—particularly for multicloud environments. Each process could generate multiple log entries, adding up to terabytes of data every day. Metrics are often tracked and measured relative to a baseline or threshold.
By providing customers the most comprehensive, intelligent, and easy-to-deploy observability solution in the market, Dynatrace and Microsoft have laid the groundwork for organizations to successfully migrate to cloud environments and continuously modernize with speed and scalability. This monitoring is ongoing.
Table name Default bucket logs default_logs events default_events metrics default_metrics bizevents default_bizevents dt.system.events dt_system_events entities spans (in the future) The default buckets let you ingest data immediately, but you can also create additional custom buckets to make the most of Grail.
1: Observability is more of an attribute than a process . Observability requires complete access to metrics, traces, and logs. OpenTelemetry is an open source standard for gathering observability signals, including metrics, traces, and logs. We have helped position them for success in 2022 and beyond. .
In this post, I’m going to break these processes down into each of: ? Connection One thing we haven’t looked at is the impact of network speeds on these outcomes. Larger files compress much more effectively and thus download faster at all connection speeds. The former makes for a simpler build step, but is it faster?
Provide self-service platform services with dedicated UI for development teams to improve developer experience and increase speed of delivery. Open source logs and metrics take precedence in the monitoring process. Automation, automation, automation. Adoption of GitOps practices enables platform provisioning at scale.
The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. The goal is to turn more data into insights so the whole organization can make data-driven decisions and automate processes. Grail can store and process 1,000 petabytes per day,” Greifeneder explains.
Start by asking yourself what’s there, whether it’s logs, metrics, or traces. Once you double down on the type, you want to figure out, or browse, which metric is relevant. Then when you have the metric, you want to explore it—what splits are available, how can I break it down, how can I aggregate it, and so on.”
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. Speed index. How quickly visible parts of the page are rendered.
How To Benchmark And Improve Web Vitals With Real User Metrics. How To Benchmark And Improve Web Vitals With Real User Metrics. Different products will have different benchmarks and two apps may perform differently against the same metrics, but still rank quite similarly to our subjective “good” and “bad” verdicts.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Carefully planning and integrating new processes and tools is critical to ensuring compliance without disrupting daily operations.
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality.
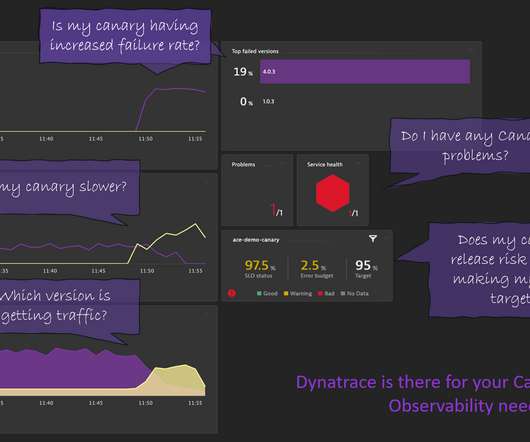
Progressive Delivery enables speeding up while managing the risk of software deployments and configuration changes. To make it easier let me walk you through the things I have learned in this video so you can bring Dynatrace Cloud Automation to your progressive delivery process. Having metrics with version information, e.g,
Most network devices have temperature and fan speed sensors, and some even function as standalone devices, such as contact switches. The SNMP Traps Device instances overview page shows all the critical data you need to uncover metric abnormalities associated with a recorded trap event, allowing IT Ops to swiftly identify the root cause.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
Modern infrastructure needs to be elastic and GitOps approaches are used to automate the provisioning of infrastructure and applications using Git, an open-source control system that provides the change processes including reviews and approvals. Key components of GitOps are declarative infrastructure as code, orchestration, and observability.
The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs. Furthermore, OneAgent observes and gathers all remaining workload logs, metrics, traces, and events. This process is vital to an IDP’s effectiveness.
Streamline development and delivery processes Nowadays, digital transformation strategies are executed by almost every organization across all industries. Thus, Site Reliability Guardian supports DevOps and SREs in speeding up release delivery and improving release quality.
Staying ahead of customer needs requires speed and agility from all phases of the software development life cycle (SDLC). DevOps automation tools speed up delivery cycles by reducing human error and bottlenecks, resulting in fewer and shorter feedback loops. It helps to assess the long- and short-term efficiency and speed of DevOps.
The only way to address these challenges is through observability data — logs, metrics, and traces. IT pros want a data and analytics solution that doesn’t require tradeoffs between speed, scale, and cost. Your key business objectives will drive your strategy and metrics. But it doesn’t stop there.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
At the same time, they open a door to lots of concepts that might be overwhelming: PRPL, RAIL, Paint Timing API, TTI, HTTP/2, Speed Index, Priority Hints and more … Why Performance doesn’t get Prioritized Web performance at organizations is a real challenge. One could argue this is a metric-driven decision. Well, not so fast.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content