This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
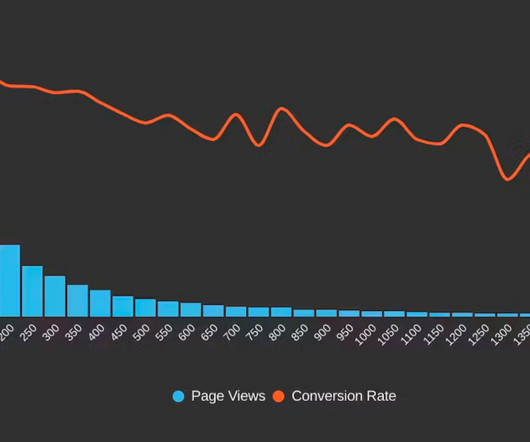
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. The market is saturated with tools for building eye-catching dashboards, but ultimately, it comes down to interpreting the presented information. For instance, in a web shop, sales might vary by day of the week.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? They allow us to verify whether titles are presented as intended and investigate any discrepancies.
It filters out any invalid entries and enriches the valid ones with additional metadata, such as show or movie title details, and the specific page and row location where each impression was presented to users. We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression.
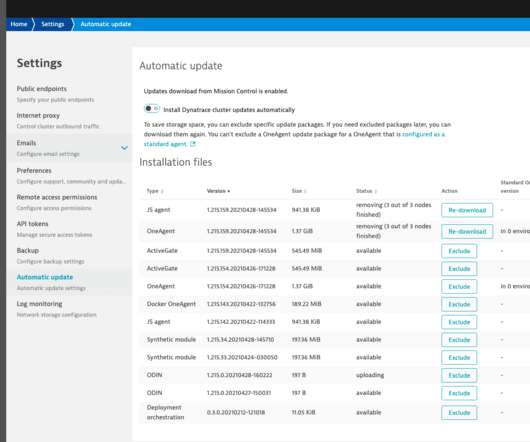
Each SNMP-enabled device provides access to its state and performance metrics in a simple and robust way that allows Dynatrace to fetch the metrics and run them through Davis®, our AI causation engine. Based on monitored traffic, Dynatrace OneAgent is capable of automatic recognition of topological relations. Events and alerts.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
When the SLO status converges to an optimal value of 100%, and there’s substantial traffic (calls/min), BurnRate becomes more relevant for anomaly detection. SLOs must be evaluated at 100%, even when there is currently no traffic. Data Explorer “test your Metric Expression” for info result coming from the above metric.
VPC Flow Logs is a feature that gives you the capability to capture more robust IP traffic data that traverses your VPCs. A full list of metrics can be found here and include dimensions such as the following: Packets. A feature that enables you to present log data in a filterable table that is easy to work with. Log Metrics.
based sample service in a staging and production namespace, a Jenkins instance and execute some moderate load to “simulate constant production traffic”. Automated Metric Anomaly Detection. From here we also get access to all other pod & process relevant metrics, e.g. memory, threads, … or accessing the container logs.
These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Identify key performance metrics specific to an organization.
Rexed, Singh, and Stull outline the importance of metrics, traces, logs, events, and the role they play in achieving full–context Kubernetes observability and driving automated responses in hybrid and multi-cloud environments. To ensure everything runs smoothly, they employ the Dynatrace automated monitoring and observability solution.
Each of these factors can present unique challenges individually or in combination. But gaining observability of distributed environments, such as Kubernetes, microservices, and containerized application deployments, presents formidable challenges.
framework , the SNMP extensions are a bundle of everything that’s needed (DataSource configuration, a dashboard template, a unified analysis page template, topology definition, entity extraction rules, relevant metric definitions and more) to get going with monitoring. Simplified data analysis presented in topological context.
For example, to handle traffic spikes and pay only for what they use. Scale automatically based on the demand and traffic patterns. Observability is typically achieved by collecting three types of data from a system, metrics, logs and traces. The elasticity of serverless services helps organizations scale as needed.
264/AVC Main profile family still represents a substantial portion of the members viewing hours and an even larger portion of the traffic. These are summarized below: Instead of relying on other objective metrics, such as PSNR†, VMAF is employed to guide optimization decisions. Yet, given its wide support, our H.264/AVC
Edgar helps Netflix teams troubleshoot distributed systems efficiently with the help of a summarized presentation of request tracing, logs, analysis, and metadata. Edgar captures 100% of interesting traces , as opposed to sampling a small fixed percentage of traffic. by Elizabeth Carretto Everyone loves Unsolved Mysteries.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
Dynatrace Synthetic Monitoring helps you quickly verify if your application is delivering the expected end user experience by offering an outside-in view of all your applications and services, independent of real traffic. With just one click, you can drill down to the service, which is filtered for requests coming from the HTTP monitor.
Exploratory data analytics is an analysis method that uses visualizations, including graphs and charts, to help IT teams investigate emerging data trends and circumvent issues, such as unexpected traffic spikes or performance degradations. Start by asking yourself what’s there, whether it’s logs, metrics, or traces.
However, performance can decline under high traffic conditions. It also provides an HTTP API for retrieving performance metrics and a command-line tool for advanced management tasks. While Kafka does not include a built-in web interface like RabbitMQ, it provides metrics that integrate with third-party monitoring tools.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
Dynatrace offers various out-of-the-box features and applications to provide a high-density overview of system health for all hosts and related metrics in a single view. Problems application The Problems application automatically identifies issues, collects the context behind them, and presents their root cause and impacts in a single view.
To improve management of node capabilities , we added Enable/disable Web UI traffic operation for cluster node in Cluster Mission Control UI. To better present default values, we changed the position of session replay permissions in group details page. . APM-298915). APM-295508). APM-296578). APM-294399). APM-289135). APM-297575).
Organizations that have transitioned to agile software development strategies (including the adoption of a DevOps culture and continuous delivery automation) enforce automated solutions for such decision making—or at the very least, use automation in the gathering of a release-quality metrics.
Details pertaining to HDR-VMAF exceed the scope of this article and will be covered in a future blog post; for now, suffice it to say that the first version of HDR-VMAF landed internally in 2021 and we have been improving the metric ever since. 1) depicts the migration of traffic from fixed bitrates to DO encodes. We present two sets.
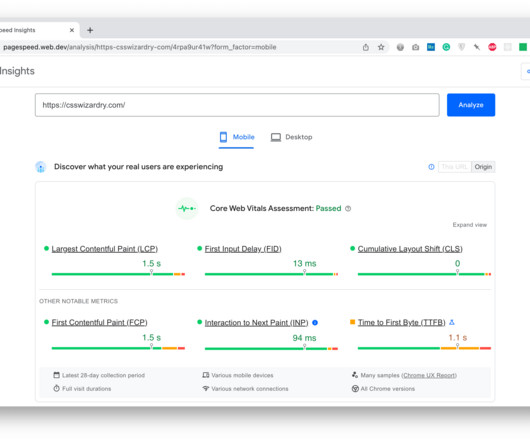
All Core Web Vitals data used to rank you is taken from actual Chrome-based traffic to your site. The Core Web Vitals Metrics Generally, I approve of the Core Web Vitals metrics themselves ( Largest Contentful Paint , First Input Delay , Cumulative Layout Shift , and the nascent Interaction to Next Paint ).
It is also a key metric for organizations looking to improve their DevOps performance. This metric represents the proportion of system incidents resolved by escalating to a higher level of support. Improved change failure and escalation rates. The same concept holds true for incident escalation rate.
Unified observability is the ability to know how systems and infrastructure are performing based on the data they generate, such as logs, metrics, and traces. Observability also presents the information in highly consumable ways that enable teams to detect and resolve issues before they impact end users or customers.
Zittrain points out that they “traffic in byzantine patterns with predictive utility, not neat articulations of relationships between cause and effect.” They’re like the lone IT hero who glances at a bunch of metric charts and conjures up an answer based on “gut feel” gained through experience over time.
Canary Test Workloads In addition to serving the regular message traffic between users and DUTs, the control plane itself is stress-tested at roughly 3-hour intervals, where nearly 3000 ephemeral MQTT clients are created to connect to and generate flash traffic on the MQTT brokers.
presented in Google IO 2018 ( source ) These tools make it easier to determine where we need to put emphasis to improve our sites. One could argue this is a metric-driven decision. There is a lot research on how performance optimization improves key metrics and sites like WPO Stats are a good source of case studies.
At Neotys PAC 2019 in Chamonix, France, I presented approaches on how to solve this problem by looking at examples from companies such as Intuit, Dynatrace, Google, Netflix, T-Systems and others. The outcome of the presentation and the follow up discussions at Neotys PAC lead to Pitometer! Pitometer is a Node.js
Updated sliding time-frame window for custom metrics. Until now we had a sliding window of 28 days for custom metrics, which meant that you could consume unique metrics up to your licensed quota within a time frame of 28 days. This also meant that you had to wait 28 days until you could start collecting new metrics.
On the other hand, when one is interested only in simple additive metrics like total page views or average price of conversion, it is obvious that raw data can be efficiently summarized, for example, on a daily basis or using simple in-stream counters. A group of several such sketches can be used to process range query. Case Study.
Historically we have been responsible for connecting, routing, and steering internet traffic from Netflix subscribers to services in the cloud. Every leader’s security risk dashboard now includes a Wall-E adoption metric, and roughly ? Our gateways are powered by our flagship open-source technology Zuul.
Earlier this year, Google announced that Interaction to Next Paint (INP) is no longer an experimental metric. Now that INP has arrived to dethrone FID as the responsiveness metric in Core Web Vitals, we've turned our eye to scrutinizing its effectiveness. When it comes to new performance metrics, it's easy to jump on bandwagons.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this session, we present our human-centric design principles that enable the autonomy our engineers enjoy. Wednesday?—?December
If you’re reading this before March 2024 and fire up your favorite performance monitoring tool, you’re going to to get a Core Web Vitals report like this one pulled from PageSpeed Insights: ( Large preview ) You’re likely used to seeing most of these metrics. INP will officially replace FID when it becomes an official Core Web Vital metric.
We do not use it for metrics, histograms, timers, or any such near-real time analytics use case. However, storing and querying such data presents a unique set of challenges: High Throughput : Managing up to 10 million writes per second while maintaining high availability. Let’s dive into the various aspects of this abstraction.
A well-established metric we provide is APDEX , which tell us how users are perceiving page load times (time to the first byte, page speed, speed index), errors (JavaScript errors, crashes,) and also factors in the overall user journey (each user interaction) including their environment (browser, geolocation, bandwidth).
Let’s take a look at how to get the benefits you need while spending less, based on the recommendations presented by Dani Guzmán Burgos, our Percona Monitoring and Management (PMM) Tech Lead, on this webinar (now available on demand) hosted in November last year. Configuration of the CPU metrics can be changed in the dashboard.
RTT data should be seen as an insight and not a metric. Note some of the counties in these URLs: this client has a truly international audience, and latency metrics are of great interest to me. Interestingly, latency only accounts for a small proportion of my overall TTFB metric. An inefficiency present in HTTP/1.0
In this blog, we would like to present the latest updates to Conductor, address some of the frequently asked questions and thank the community for their contributions. Below is a snapshot of our Kibana dashboard which shows the workflow execution metrics over a typical 7-day period.
In particular, the collected measurements include the three Core Web Vitals metrics measured for each session. In recent years, these metrics have become the cornerstone of modern Web performance analysis: Largest Contentful Paint (LCP) , First Input Delay (FID) , Cumulative Layout Shift (CLS). Large preview ). Large preview ).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content