This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performancetuning needs. Semantic Conventions, or semconv, are the standard that makes it all possible.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time.
Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Depending on the types of technologies you’re running on individual hosts, the average number of metrics is about 500 per computational node. Running metric queries on a subset of entities for live monitoring and system overviews.
Synthetic monitors are also the perfect tool to monitor performance baselines. This clean-room, lab-like environment allows you to react to slight changes in performance. It also gives you the first indication of whether a new deployment of your application or API leads to a performance improvement or, perhaps, a regression.
Welcome back to the blog series where we provide you with deep dives into the latest observability awesomeness from Dynatrace , demonstrating how we bring scale, zero configuration, automatic AI driven alerting, and root cause analysis to all your custom metrics, including open source observability frameworks like StatsD, Telegraf, and Prometheus.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
Now that you’ve deployed your code, it’s time to monitor it, collect data, and analyze your metrics. Without application performance monitoring in place, you can’t accurately determine how well things are going. Is the app performant? Are people using your app? Do the pages load quickly? Are your users experiencing any errors?
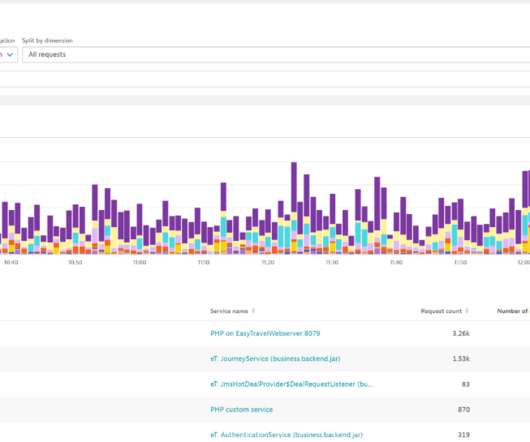
In an existing application landscape, however, it can be difficult to get to those metrics. A larger financial institution is using the analysis to report business metrics on dashboards and make them accessible via the Dynatrace API. Optimize your application and business performance by analyzing request- and service-based metrics.
We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression. These metrics include everything from validating identifiers to checking that essential columns are properly filled.
This challenge has given rise to the discipline of observability engineering, which concentrates on the details of telemetry data to fine-tune observability use cases. To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus.
Traditional debugging approaches, logs, and occasional remote breakpoint instrumentation cant easily keep pace with cloud-native AI deployments, where performance, compliance, and costs are all on the line. How can you gain insights that drive innovation and reliability in AI initiatives without breaking the bank?
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. BlackDuck performs a security and vulnerability check, returning a scan result.
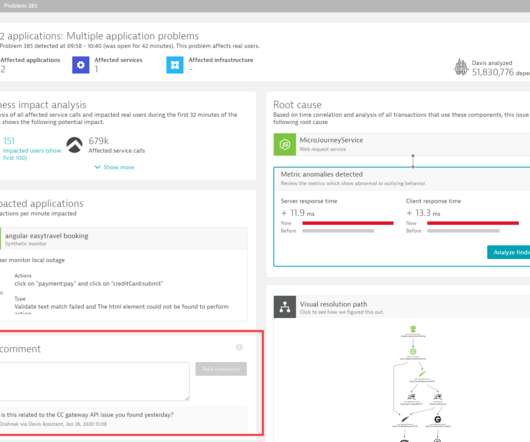
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. Enterprise-grade observability for custom OpenTelemetry metrics from AWS. Dynatrace news.
As the application owner of an e-commerce application, for example, you can enrich the source code of your application with domain-specific knowledge by adding actionable semantics to collected performance or business metrics. New OpenTelemetry metrics exporters provide the broadest language support on the market.
The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
In my recent Performance Clinic with Stefano Doni , CTO & Co-Founder of Akamas , I made the statement, “Application development and release cycles today are measured in days, instead of months. Increase in environment complexity and increased frequency in delivery requires a novel approach to performance optimization.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? By logging all titles as they are displayed, we can process these logs to identify anomalies and gain insights into system performance.
Welcome back to the second part of our blog series on how easy it is to get enterprise-grade observability at scale in Dynatrace for your OpenTelemetry custom metrics. In Part 1 , we announced our new OpenTelemetry custom-metric exporters that provide the broadest language coverage on the market, including Go , .NET record(value); }.
Dynatrace Visually complete is a point-in-time web performancemetric that measures when the visual area of a page has finished loading. Dynatrace is the only solution that provides these user experience metrics consistently for real user monitoring as well as for synthetic monitors. More precisely, you can now: .
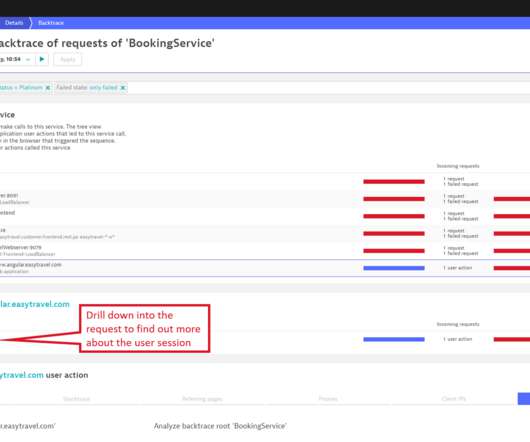
Select a Metric and Aggregation to get started. You can choose any standard Dynatrace metric and any request attribute. Simply switch the metric to Failure rate to find out if there was an error that might have impacted your platinum customers. You might guess that the relatively long booking time is caused by a failure.
Issues that manifest themselves as performance degradation on a user’s device can often be traced back to underlying infrastructure issues. Monitor additional metrics. Additionally, we’re further extending our infrastructure mode with runtime metrics for: Java.NET. All of these metrics are now part of infrastructure mode.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
In my last post , I started to outline the process I go through when tuning queries – specifically when I discover that I need to add a new index, or modify an existing one. This is where index tuning becomes an art. If performance improves, you're good to go! Step 6: Testing. It's rarely that simple.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. Architecture Comparison RabbitMQ and Kafka have distinct architectural designs that influence their performance and suitability for different use cases.
Synthetic monitors provide a perfect means of continually monitoring the performance baselines of your web applications. However, understanding the performance of different application types requires an emphasis on different performancemetrics, that is, key performancemetrics.
The main purpose of this article and use case is to scrape AWS CloudWatch metrics into the Prometheus time series and to visualize the metrics data in Grafana. These tools give greater visibility other than collecting the metrics also, where we can set up critical alerts, live views, and custom dashboards.
Performance is usually a primary concern when using stream processing frameworks. See more about the performance of stream processing frameworks in our published paper. ShuffleBench i s a benchmarking tool for evaluating the performance of modern stream processing frameworks.
This blog post will share broadly-applicable techniques (beyond GraphQL) we used to perform this migration. So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render.
VMAF is a video quality metric that Netflix jointly developed with a number of university collaborators and open-sourced on Github. VMAF has become a de facto standard for evaluating the performance of encoding systems and driving encoding optimizations. This tech blog highlights our recent progress toward this goal.
Defining a comprehensive user-experience metric gives rise to questions such as: How do we compare the user experience of one session to another? Which metric can be used for the purpose of reporting user experience and tracking it over a period of time? A single metric for user experience segmentation. Error metrics.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
Particularly during the COVID-19 pandemic, we’ve seen how poor application performance can impact business bottom lines and lead to lost revenue for many organizations, as laid out in our recent blog post about digital experience. with: Aggregated field metrics?rather?than?valuable?details Metrics and recommendations?rather
Open-source metric sources automatically map to our Smartscape model for AI analytics. We’ve just enhanced Dynatrace OneAgent with an open metric API. Here’s a quick overview of what you can achieve now that the Dynatrace Software Intelligence Platform has been extended to ingest third-party metrics. Dynatrace news.
At much less than 1% of CPU and memory on the instance, this highly performant sidecar provides flow data at scale for network insight. The sidecar has been implemented by leveraging the highly performant eBPF along with carefully chosen transport protocols to consume less than 1% of CPU and memory on any instance in our fleet.
While receiving no feedback on the quality or security of new features leaves developers uncertain about feature performance, delayed feedback also increases a developer’s cognitive load. For example, the team must establish specific thresholds for desired service performance behavior.
From that point on, Dynatrace starts writing timeseries metrics that can be used for custom charting. Different user actions also have different performance requirements. Fine-tune problem detection by setting individual anomaly detection rules for your key user actions.
These environments are marked by continuous delivery of microservice updates into production, the abstractions inherent in Kubernetes environments, and challenges associated with applications distributed across multicloud environments—often with performance and security risks. Dynatrace was recognized as Compuware from 2010-2014.
Synthetic Minority Over-sampling Technique Evaluation Metrics For evaluating the performance of the anomaly detection models we consider a set of evaluation metrics and report their values. For the one-class as well as binary anomaly detection task, such metrics are accuracy, precision, recall, f0.5,
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. Telemetry Telemetry involves collecting and analyzing data from distributed sources to provide insights into how a system is performing. There are three main types of telemetry data: Metrics.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. Many technologies expose their metrics in the Prometheus data format. Easily gain actionable insights with the Dynatrace Extension for Prometheus metrics. Prometheus in Kubernetes ?and
With Davis Assistant and Microsoft Teams, you can: Receive proactive and actionable IT health and performance alerts in dynamically updated smart cards displayed in a Teams channel. View Dynatrace performance charts directly in Teams for quick impact assessment. What our customers are saying about Davis Assistant.
This post was co-authored by Jean-Louis Lormeau, Digital Performance Architect at Dynatrace. . You’ll learn how to create production SLOs, to continuously improve the performance of services, and I’ll guide you on how to become a champion of your sport by: Creating calculated metrics with the help of multidimensional analysis.
A couple of years ago, my first few days on a new web performance project were always slow going. Unless a client hires you to specifically improve the performance of one page, you’ll need a broad view of the whole site or application. Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content