This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Microsoft Azure SQL is a robust, fully managed database platform designed for high-performance querying, relational data storage, and analytics. An application software generates user metrics on a daily basis, which can be used for reports or analytics.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. In a monitoring scenario, you typically preconfigure dashboards that are meant to alert you to performance issues you expect to see later. What is observability?
Mobile applications (apps) are an increasingly important channel for reaching customers, but the distributed nature of mobile app platforms and delivery networks can cause performance problems that leave users frustrated, or worse, turning to competitors. What is mobile app performance? Some of the most important KPIs are listed below.
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. In practical applications, percentiles are particularly useful for web performance analysis.
DORA ( DevOps Research and Assessment ) metrics, developed by the DORA team have become a standard for measuring the efficiency and effectiveness of DevOps implementations. As organizations start to adopt DevOps practices to accelerate software delivery, tracking performance and reliability becomes critical. What Are DORA Metrics?
Recently, I encountered a task where a business was using AWS Elastic Beanstalk but was struggling to understand the system state due to the lack of comprehensive metrics in CloudWatch. By default, CloudWatch only provides a few basic metrics such as CPU and Networks.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
Provide an at-a-glance view of your system’s health and performance Dynatrace guides you in quickly getting the most valuable SLOs set up in just a few clicks. Heterogeneous services require heterogeneous indicators Metrics, logs, and traces are the core ingredients for making your environment observable.
You can now: Kickstart your creation journey using ready-made dashboards Accelerate your data exploration with seamless integration between apps Start from scratch with the new Explore interface Search for known metrics from anywhere Let’s look at each of these paths through an end-to-end use case focused on Kubernetes monitoring.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. For instance, in a web shop, sales might vary by day of the week.
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performance tuning needs. Semantic Conventions, or semconv, are the standard that makes it all possible.
When I founded Dynatrace, I aimed to bridge the gap between IT performance and user experience. My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. Using causal AI, we identified and resolved performance issues automatically.
But as with many other automation tools, it can be difficult to maintain the performance and visibility of these workflows. Everyone involved in the software delivery lifecycle can work together more effectively with a single source of truth and a shared understanding of pipeline performance and health.
This allows you to build customized visualizations with Dashboards or perform in-depth analysis with Notebooks. Select any execution you’re interested in to display its details, for example, the content response body, its headers, and related metrics. Details of requests sent during each monitor execution are also available.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
Service-level objectives (SLOs) can play a vital role in ensuring that all stakeholders have visibility into the resources being used and the performance of their applications. If your team is responsible for setting up Kubernetes clusters, you might want to monitor and optimize the workload performance when setting up SLOs.
For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards. Within the target pipeline, you can also define processing rules, extract metrics, set the security context, and define retention periods.
With this Google Cloud Ready integration, Dynatrace ensures that AlloyDB for PostgreSQL users can now ingest metrics along with existing Google Cloud data. The post Dynatrace announces support of Google Cloud’s AlloyDB for PostgreSQL metrics ingest appeared first on Dynatrace news.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough. What is OpenTelemetry?
Traditional debugging approaches, logs, and occasional remote breakpoint instrumentation cant easily keep pace with cloud-native AI deployments, where performance, compliance, and costs are all on the line. Send unified data to Dynatrace for analysis alongside your logs, metrics, and traces.
This is an article from DZone's 2023 Observability and Application Performance Trend Report. Overlooking the nuances of the system state — spanning infrastructure, application performance, and user interaction — is a risk businesses can't afford.
Find and prevent application performance risks A major challenge for DevOps and security teams is responding to outages or poor application performance fast enough to maintain normal service. It should also be possible to analyze data in context to proactively address events, optimize performance, and remediate issues in real time.
The five key metrics to improve customer satisfaction To help turn this around, Dynatrace makes available its unified observability platform, which captures all CX interactions and transactions in an automated, intelligent manner – including user session replays. When combined, key metrics will generate an accurate CX index score.
In both bands, performance characteristics remain consistent for the entire uptime of the JVM on the node, i.e. nodes never jumped the bands. Luckily, the m5.12xl instance type exposes a set of core PMCs (Performance Monitoring Counters, a.k.a. This was our starting point for troubleshooting.
This article takes a plunge into the comparative analysis of these two cult technologies, highlights the critical performancemetrics concerning scalability considerations, and, through real-world use cases, gives you the clarity to confidently make an informed decision. However, the question arises of choosing the best one.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. BlackDuck performs a security and vulnerability check, returning a scan result.
This article explores SLOs for service performance. According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. While this connection might sound simple, finding the right metrics to measure the needed SLIs takes time and effort.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. What’s behind it all?
The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
Service Level Objectives (SLO) tracking: Honeycomb charts can visualize SLOs, helping you monitor whether your services meet performance and reliability targets. While histograms look much like time-series bar charts, they’re different in that each bar represents a count (often termed frequency) of metric values.
These are just some of the topics being showcased at Perform 2023 in Las Vegas. Perform 2023 news At Perform 2023 in Las Vegas, the headliner theme is IT automation. What’s more, organizations are no longer concerned only about application performance and sales numbers. We’ll post news here as it happens!
Managing cloud performance is increasingly challenging for organizations that spread workloads across a greater variety of platforms. Moreover, organizations have to balance maintaining security, retaining cloud management expertise, and managing infrastructure performance. Rural lifestyle retail giant Tractor Supply Co.
Observability has become a key component in software development as it enables the best customer experience by ensuring system health and performance and detecting systemic issues proactively. OpenSearch simplifies this by providing an open-source, scalable solution for logging, metrics, and visualization.
With Dynatrace, customers can utilize the full set of Azure capabilities, including metrics and data from the Azure platform, and automatically identify workflow optimization opportunities. By prioritizing observability, organizations can ensure the availability, performance, and security of business-critical applications.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression. These metrics include everything from validating identifiers to checking that essential columns are properly filled.
Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications. The post Container monitoring for VA Platform One helps VA achieve workload performance appeared first on Dynatrace news.
With our annual user conference, Dynatrace Perform 2024 rapidly approaching on January 29 through February 1, 2024, our teams, partners, and customers are buzzing with excitement and anticipation. Read on to learn what you can look forward to hearing about from each of our cloud partners at Perform. What can we move?
Performance and error optimization is complicated, and the approach to driving improvement has long relied on static recommendations disconnected from a site’s end users and their experiences. Sometimes, these recommendations are so far from current performance or cost so much to implement that they seem irrelevant or unattainable.
This blog post will share broadly-applicable techniques (beyond GraphQL) we used to perform this migration. So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? By logging all titles as they are displayed, we can process these logs to identify anomalies and gain insights into system performance.
Whenever we need to do performance testing, mostly it is the APIs that come to mind. Testing the performance of an application by putting load on APIs or on servers and checking out various metrics or parameters falls under server-side performance testing.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































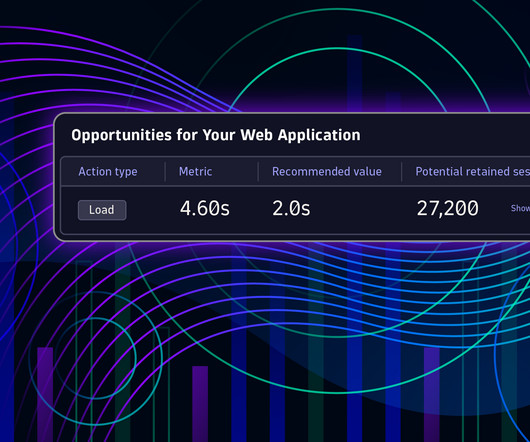










Let's personalize your content