This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Available directly from the AWS Marketplace , Dynatrace provides full-stack observability and AI to help IT teams optimize the resiliency of their cloud applications from the user experience down to the underlying operatingsystem, infrastructure, and services. Auto-detection starts monitoring new virtual machines as they are deployed.
As Kubernetes adoption increases and it continues to advance technologically, Kubernetes has emerged as the “operatingsystem” of the cloud. Kubernetes is emerging as the “operatingsystem” of the cloud. Accordingly, the remaining 27% of clusters are self-managed by the customer on cloud virtual machines.
Symptoms : No data is provided for affected metrics on dashboards, alerts, and custom device pages populated by the affected extension metrics. Sometimes the Python virtual machine crashes. Operatingsystems. Future Dynatrace OneAgent operatingsystems support changes. Extension logs display errors.
When operating an application, it’s helpful to have deeper insights that show you what’s really going on. To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. OneAgent and its Operator .
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operatingsystem, CPU cycles, and memory. VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines.
Dynatrace is proud to provide deep monitoring support for Azure Linux as a container host operatingsystem (OS) platform for Azure Kubernetes Services (AKS) to enable customers to operate efficiently and innovate faster. Instantly visualize the Kubernetes environment with all the detailed metrics and events teams care about.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. If you don’t have insight into the software and services that operate your business, you can’t efficiently run your business. Dynatrace news. What is infrastructure monitoring? .
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. metrics, traces, and logs) to gain a better understanding of the behavior of their code during runtime.
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operatingsystems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. PC, smartphone, server) or virtual (virtual machines, cloud gateways). What is digital experience monitoring? Endpoints can be physical (i.e.,
Dynatrace offers Custom Service Entry Points , which virtually breaks the monolith and provides valuable information about whether organizations should break out certain pieces of the monolith. For example, a virtual machine (VM) can replace containers to design and architect microservices. How do you monitor microservices?
When operating an application, it ’ s helpful to have deeper insights that show you what’s really going on. Metrics to find out how the behavior of a system has changed over time . Traces help find the flow of a request through a distributed system . Dynatrace VMware and virtualization documentation .
In fact, once containerized, many of these services and the source code itself is virtually invisible in a standalone Kubernetes environment. Today, most thought-leaders break down Observability into three pillars; metrics, distributed traces and logs. Stand-alone observability won’t cut it.
Unfortunately, container security is much more difficult to achieve than security for more traditional compute platforms, such as virtual machines or bare metal hosts. These products see systems from the “outside” perspective—which is to say, the attacker’s perspective. Harden the host operatingsystem.
Kubernetes has taken over the container management world and beyond , to become what some say the operatingsystem or the new Linux of the cloud. For that, on top of the resource usage metrics, you need to monitor cluster events and object state metrics. . Dynatrace news.
Upcoming Operatingsystems support changes. The following operatingsystems will no longer be supported starting 01 February 2021. The following operatingsystems will no longer be supported starting 01 May 2021. The following operatingsystems will no longer be supported starting 01 June 2021.
Kubernetes (aka K8s) is an open-source platform used to run and manage containerized applications and services on clusters of physical or virtual machines across on-premises, public, private, and hybrid clouds. This virtualization makes it possible to efficiently deploy and securely run a container independently of the hosting infrastructure.
Application performance monitoring (APM) is the practice of tracking key software application performance metrics using monitoring software and telemetry data. Practitioners use APM to ensure system availability, optimize service performance and response times, and improve user experiences. Dynatrace news. Performance monitoring.
However, due to its reliance on the virtual memory subsystem, it is not suitable for larger datasets. Compaction operation defragments data files & indexes. However, keep in ming that it does not release space to the operatingsystem. An additional disk space up to 2GB is required during the compaction operation.
In fact, once containerized, many of these services and the source code itself is virtually invisible in a standalone Kubernetes environment. Today, most thought-leaders break down Observability into three pillars; metrics, distributed traces and logs. Stand-alone observability won’t cut it.
But do you know how Lighthouse calculates performance metrics like First Contentful Paint (FCP), Total Blocking Time (TBT), and Cumulative Layout Shift (CLS)? Still, there’s nothing in there to tell us about the data Lighthouse is using to evaluate metrics. But it comes with caveats. So why use lab data at all?
HammerDB has graphical and command line interfaces for the Windows and Linux operatingsystems. An important concept was to simulate database users called Virtual Users in parallel (rather than concurrently) to accurately simulate a real database workload with multiple users running from separate systems. The NOPM Metric.
A wide range of users with different operatingsystems, browsers, hardware configurations and other variables provides a wide sample size that helps developers discover as many issues as possible. RUM gathers metrics from passive users while real user testing monitors testers who are actively looking for problems and vulnerabilities.
Regardless of whether the computing platform to be evaluated is on-prem, containerized, virtualized, or in the cloud, it is crucial to consider several essential factors. OperatingSystem: Ubuntu 22.04 Storage: The system has a SATA drive for the operatingsystem and one NVMe (Intel SSD D7-P5510 (3.84
This complexity is “hidden” to the end user, like how an API (Application Programming Interface) operates, whether that is an actual user or another computer. These systems can include physical servers, containers, virtual machines, or even a device, or node, that connects and communicates with the network. Heterogeneity.
Let alone browsers, the website may get into trouble for different resolutions, different operatingsystems and different browser versions too!! Cross-browser testing deals with all those things by running the websites on different browsers, their versions, operatingsystems and on different resolutions.
The main improvement MSLs give is that a program data race will not corrupt the language’s own virtual machine (whereas in C++ a data race is currently all-bets-are-off undefined behavior). Saying the quiet part out loud: CVEs are known to be an imprecise metric. 2) The problem “isn’t” that C++ code is not formally provably safe.
This proposal seeks to define a standard for real-time carbon and energy data as time-series data that would be accessed alongside and synchronized with the existing throughput, utilization and latency metrics that are provided for the components and applications in computing environments.
It is of note that we have not discussed the operatingsystem yet, that is because the source code and the code included with the pre-packaged versions is identical whether it is running on Linux or Windows on x86-64 architecture (or any other platform). BLT graphical package extension for metrics for both Linux and Windows.
As we are dealing with Docker images, I assume you have downloaded and installed Docker for your operatingsystem. You will require VirtualBox (or a similar VM driver such as xhyve driver or VMware Fusion depending on your operatingsystem) which enables Minikube to run a single-node Kubernetes cluster inside a VM.
Additionally, end users can access your site or applications from anywhere in the world using different browsers, operatingsystems, and mobile devices, all with varying connection speeds. Use baseline metrics to identify performance degradation by reviewing elements provided by waterfall charts.
Depending on the browser and operatingsystem, you may also experience browser scrollbar widths upsetting the 100vw calculation as well. URL bar and virtual keyboard), and will not change its value even as the browser chrome changes. Currently, the fix is to update to 100% if you can. Cumulative Layout Shift.
Support a wide variety of devices and application types –The platform should be optimized to support multiple devices, implementations, and OperatingSystems. including iPhones/ mobile devices, set-top boxes, game stations, and IoT devices.
To keep up with the testing demand there are a number of feature requirements needed in order to be called a modern performance testing platform: Mega-scale load testing — load testing should scale up to millions of users within seconds to emulate the speed and scale of virtually any high-profile event worldwide.
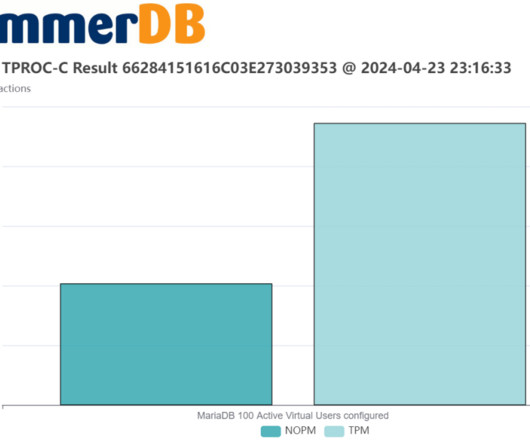
“ Scalability” is a product of both the benchmarking application itself (See the post on HammerDB Architecture to see how it scales implementing multiple virtual users as threads) as well as the benchmarking workload (The TPC benchmarks that HammerDB uses have been designed specifically for this purpose and proven over decades to scale).
You can also simulate thousands of virtual users to determine the performance of your application and how it will behave under load. Cloud-based tools also provide detailed metrics with graphs to understand and analyze the performance. With the cloud, you can configure your resources to high numbers in seconds.
SQL Server always checks I/O completion status for any operatingsystem error conditions and proper data transfer size and then handles errors appropriately. Torn pages generally arise after system outages where the subsystem does not complete the entire 8-KB I/O request. This utility is located on the Microsoft Web site.
Load averages are an industry-critical metric – my company spends millions auto-scaling cloud instances based on them and other metrics – but on Linux there's some mystery around them. But to understand them in more detail is difficult without the aid of other metrics. I've never seen an explanation.
In this post, we revisit how to interpret transactional database performance metrics and give guidance on what levels of performance should be expected on up-to-date hardware and software in 2024. tpmC tpmC is the transactions per minute metric that is the measurement of the official TPC-C benchmark from the TPC-Council.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content