This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can now: Kickstart your creation journey using ready-made dashboards Accelerate your data exploration with seamless integration between apps Start from scratch with the new Explore interface Search for known metrics from anywhere Let’s look at each of these paths through an end-to-end use case focused on Kubernetes monitoring.
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. Without having network visibility, it’s difficult to improve our reliability, security and capacity posture.
Recently, I encountered a task where a business was using AWS Elastic Beanstalk but was struggling to understand the system state due to the lack of comprehensive metrics in CloudWatch. By default, CloudWatch only provides a few basic metrics such as CPU and Networks.
Quick and easy network infrastructure monitoring. Begin network monitoring by simply deploying an extension with just a few clicks. The topology model for network devices covers simple to complex use cases from visualizing the interfaces of a router to mapping an F5 Big-IP LTM load balancer. Start monitoring in minutes.
To extend Dynatrace diagnostic visibility into network traffic, we’ve added out-of-the-box DNS request tracking to our infrastructure monitoring capabilities. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Slower response times can be a sign of a stressed DNS server or network communication issues.
Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you. For our example dashboard, we’ll only focus on some selected key infrastructure metrics. Click on Select metric. Change it now to sum.
Why browser and HTTP monitors might not be sufficient In modern IT environments, which are complex and dynamically changing, you often need deeper insights into the Transport or Network layers. Is it a bug in the codebase, a malfunctioning backend service, an overloaded hosting infrastructure, or perhaps a misconfigured network?
The Carbon Impact app directly supports our customers sustainability efforts through granular real-time emissions reporting and analytics, translating host utilization metrics into their CO2 equivalent (CO2e). We implemented a wasted energy metric in the app to enhance practitioner actionability. Public network traffic uses 1.0
Monitoring modern IT infrastructure is difficult, sometimes impossible, without advanced network monitoring tools. While the market is saturated with many Network Administrator support solutions, Dynatrace can help you analyze the impact on your organization in an automated manner. Device-centric SNMP Trap overview.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
Mobile applications (apps) are an increasingly important channel for reaching customers, but the distributed nature of mobile app platforms and delivery networks can cause performance problems that leave users frustrated, or worse, turning to competitors. Some of the most important KPIs are listed below. Performance optimization.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors. Select any execution you’re interested in to display its details, for example, the content response body, its headers, and related metrics. The new Dynatrace Synthetic app allows you to analyze these results.
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
By minimizing bandwidth and preventing unrelated traffic between data centers, you can maintain healthy network infrastructure and save on costs. Dynatrace network zones provide an easy means of routing OneAgent traffic between data centers using a unique approach that separates Dynatrace from its competitors.
DataJunction: Unifying Experimentation and Analytics Yian Shang , AnhLe At Netflix, like in many organizations, creating and using metrics is often more complex than it should be. DJ acts as a central store where metric definitions can live and evolve. As an example, imagine an analyst wanting to create a Total Streaming Hours metric.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
Any service provider tries to reach several metrics in their activity. One group of these metrics is service quality. Quality metrics contain: The ratio of successfully processed requests. But what is the metric that shows service hardware monopolization by a group of users? Number of requests dependent curves.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
Break data silos and add context for faster, more strategic decisions : Unifying metrics, logs, traces, and user behavior within a single platform enables real-time decisions rooted in full context, not guesswork. Traditional network-based security approaches are evolving.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough. What is OpenTelemetry?
This is the ability to see into and measure the current state of a system based on the data it generates, which typically includes logs, metrics, traces, end-user experiences, and context across cloud, multi-cloud, and hybrid environments. This blog originally appeared in Federal News Network. First, let’s discuss observability.
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). In our Dynatrace Dashboard tutorial, we want to add a chart that shows the bytes in and out per host over time to enhance visibility into network traffic.
It also helps to have access to OpenTelemetry, a collection of tools for examining applications that export metrics, logs, and traces for analysis. Get to the root cause of issues Most AI today uses machine learning models like neural networks that find correlations and make predictions based on them.
Infrastructure monitoring includes automatic visibility, problem detection, and smart alerting across virtual networks, virtual infrastructure, and container orchestration. Monitor additional metrics. Additionally, we’re further extending our infrastructure mode with runtime metrics for: Java.NET. How to get access.
For example, you might be using: any of the 60+ StatsD compliant client libraries to send metrics from various programming languages directly to Dynatrace; any of the 200+ Telegraf plugins to gather metrics from different areas of your environment; Prometheus, as the dominant metric provider and sink in your Kubernetes space.
Additional benefits of Dynatrace SaaS on Azure include: No infrastructure investment : Dynatrace manages the infrastructure for you, including automatic visibility, problem detection, and smart alerting across virtual networks, virtual infrastructure, and container orchestration.
As a Network Engineer, you need to ensure the operational functionality, availability, efficiency, backup/recovery, and security of your company’s network. As you might know, we recently simplified observability for all custom metrics by making it possible to ingest hundreds of custom data sources into Dynatrace.
Imagine a bustling city with a network of well-coordinated traffic signals; RabbitMQ ensures that messages (traffic) flow smoothly from producers to consumers, navigating through various routes without congestion. Quorum queues can still function during a network partition as long as most nodes communicate.
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
Continuous cloud monitoring with automation provides clear visibility into the performance and availability of websites, files, applications, servers, and network resources. These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. So, what is MTTR?
This new service enhances the user visibility of network details with direct delivery of Flow Logs for Transit Gateway to your desired endpoint via Amazon Simple Storage Service (S3) bucket or Amazon CloudWatch Logs. AWS Transit Gateway is a service offering from Amazon Web Services that connects network resources via a centralized hub.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. This blog post explores the Reliability metric , which measures modern operational practices. Why reliability?
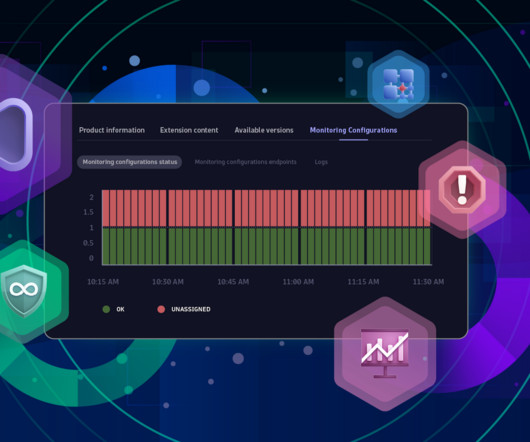
The IP address of network devices has changed? Extensions bring you a load of metrics. Knowing what each metric means is crucial to selecting the most suitable ones. Monitoring configuration outages leading to metric gaps might let crucial errors slip away. No problem, heres that specific instance.
To provide “quality signals that are essential to delivering a great user experience on the web,” Google introduced their Core Web Vitals initiative last year, advocating the Largest contentful paint , Cumulative layout shift , and First input delay metrics. with: Aggregated field metrics?rather?than?valuable?details
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
But there’s more than just a need for minimizing resource (CPU, memory, storage) and network (bandwidth) consumption for observability at the edge. Moreover, edge environments can be highly dynamic, with devices frequently joining and leaving the network.
I can reload the exact same page under the exact same network conditions over and over, and I can guarantee I will not get the exact same, say, DOMContentLoaded each time. As noted above, it’s not actually possible to improve certain metrics in their own right. There are myriad reasons for this that I won’t cover here. duration ).
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. A local endpoint in a protected network or DMZ is required to capture these messages. The key to success is making data in this complex ecosystem actionable, as many types of syslog producers exist.
Therefore, it requires multidimensional and multidisciplinary monitoring: Infrastructure health —automatically monitor the compute, storage, and network resources available to the Citrix system to ensure a stable platform. These metrics help you understand whether your Citrix landscape is sized correctly for its load.
Intro to Istio Observability Using Prometheus Istio service mesh abstracts the network from the application layers using sidecar proxies. You can implement security and advance networking policies to all the communication across your infrastructure using Istio. But another important feature of Istio is observability.
Get ready for Nutanix insights: Here’s how Dynatrace helps The extension comes with a comprehensive set of essential metrics that can quickly identify the root causes of performance issues, saving time and minimizing disruptions. With Dynatrace, Nutanix metrics can be leveraged for various use cases.
Dynatrace’s ability to ingest metrics from all 95 AWS services will be available within the next 60 days. The latest batch of services cover databases, networks, machine learning and computing. AWS SDK Metrics for Enterprise Support. Achieve full observability of all AWS services. Amazon Managed Streaming for Apache Kafka.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content