This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performance tuning needs. Semantic Conventions, or semconv, are the standard that makes it all possible.
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. So, stay tuned for more enhancements and features.
With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time. Follow along to create this host monitoring dashboard We will create a basic Host Monitoring dashboard in just a few minutes. Create a new dashboard.
Dynatrace Synthetic Monitoring allows you to proactively monitor the availability of your public as well as your internal web applications and API endpoints from locations around the globe or important internal locations such as branch offices. Synthetic monitors help you find issues before they affect your customers.
Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Depending on the types of technologies you’re running on individual hosts, the average number of metrics is about 500 per computational node. Running metric queries on a subset of entities for live monitoring and system overviews.
Welcome back to the blog series where we provide you with deep dives into the latest observability awesomeness from Dynatrace , demonstrating how we bring scale, zero configuration, automatic AI driven alerting, and root cause analysis to all your custom metrics, including open source observability frameworks like StatsD, Telegraf, and Prometheus.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
A metric crossed a threshold. You’re half awake and wondering, “Is there really a problem or is this just an alert that needs tuning? Over the years we’ve learned from on-call engineers about the pain points of application monitoring: too many alerts, too many dashboards to scroll through, and too much configuration and maintenance.
We address this requirement in Dynatrace by proudly announcing key user actions for mobile app monitoring—a great new feature for you to monitor your most important mobile app KPIs, providing you with a good foundation to drive lasting customer loyalty and grow your business.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. Enterprise-grade observability for custom OpenTelemetry metrics from AWS. Dynatrace news.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? Option 1: Log Processing Log processing offers a straightforward solution for monitoring and analyzing title launches.
This challenge has given rise to the discipline of observability engineering, which concentrates on the details of telemetry data to fine-tune observability use cases. To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus.
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. What is digital experience monitoring? Primary digital experience monitoring tools.
Every software development team grappling with Generative AI (GenAI) and LLM-based applications knows the challenge: how to observe, monitor, and secure production-level workloads at scale. Production performance monitoring: Service uptime, service health, CPU, GPU, memory, token usage, and real-time cost and performance metrics.
Highlighting NewReleases For new content, impression history helps us monitor initial user interactions and adjust our merchandising efforts accordingly. We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression.
Monitoring Kubernetes is an important aspect of Day 2 o perations and is often perceived as a significant challenge. That’s another example where monitoring is of tremendous help as it provides the current resource consumption picture and help to continuously fine tune those settings. . Node and w orkload health .
Dynatrace has recently enhanced its Metrics APIs, allowing everyone to send any type of metric with any set of data dimension to Davis, Dynatrace’s AI engine. In our conversation, I mentioned the new Dynatrace Metrics ingestion and off we went. ?? There are many use cases for using this API.
This has led to the recent release of our new Lambda monitoring extension supporting Node.js, Java, and Python. This extension was built from scratch to take into account all we’ve learned and the special requirements for monitoring ephemeral, auto-scaling, micro VMs like AWS Lambda. A look under the hood of AWS Lambda.
With Dynatrace Infrastructure Monitoring you get a complete solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Monitor any infrastructure component and backing service that’s written in Java. Monitor additional metrics. How to get access.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded.
We’re proud to introduce a significant improvement to Dynatrace Log Monitoring that will empower all your teams. With Dynatrace Log monitoring, you’re only one click away from investigating the log events that were captured during the problem time frame and beginning any required remediation efforts. Dynatrace news.
Now that you’ve deployed your code, it’s time to monitor it, collect data, and analyze your metrics. Without application performance monitoring in place, you can’t accurately determine how well things are going. The first step to gather this type of data is application monitoring. Your job is done, right? If so, where?
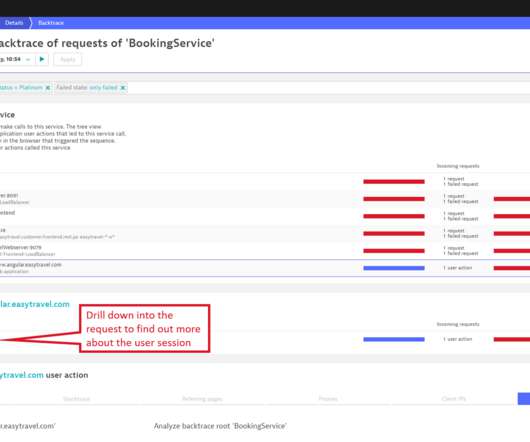
Select a Metric and Aggregation to get started. You can choose any standard Dynatrace metric and any request attribute. Simply switch the metric to Failure rate to find out if there was an error that might have impacted your platinum customers. You might guess that the relatively long booking time is caused by a failure.
RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. Optimizing RabbitMQ requires clustering, queue management, and resource tuning to maintain stability and efficiency. These tools help ensure proactive monitoring and quick issue resolution.
At Dynatrace, we’re constantly improving our AWS monitoring capabilities. Monitor and understand additional AWS services. Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Get up to 300 new AWS metrics out of the box. Updated AWS monitoring policy.
Dynatrace Digital Experience Monitoring , as part of the Dynatrace Software Intelligence Platform, connects front-end monitoring and the outside-in user perspective with application performance to understand the impact of performance issues across your full stack on user experience and business outcomes. Virginia (Azure), N.
As Dynatrace is a leader in Cloud monitoring, we have architected our Software Intelligence Platform specifically to complement Kubernetes by providing extensive functionality to tame the complexities and prevent performance issues that can occur across the development and deployment cycles. Don’t underestimate complexity.
Synthetic monitors provide a perfect means of continually monitoring the performance baselines of your web applications. However, understanding the performance of different application types requires an emphasis on different performance metrics, that is, key performance metrics. Pick the best metrics for your application.
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. So stay tuned! Optimize timing hotspots.
You will need to know which monitoringmetrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
To provide “quality signals that are essential to delivering a great user experience on the web,” Google introduced their Core Web Vitals initiative last year, advocating the Largest contentful paint , Cumulative layout shift , and First input delay metrics. with: Aggregated field metrics?rather?than?valuable?details
We’ve worked closely with our partner AWS to deliver a complete, end-to-end picture of your cloud environment that includes monitoring support for all AWS services. Dynatrace can monitor AWS Lambda functions automatically, just like any other service. Dynatrace news. and Python via traces.
The main purpose of this article and use case is to scrape AWS CloudWatch metrics into the Prometheus time series and to visualize the metrics data in Grafana. These tools give greater visibility other than collecting the metrics also, where we can set up critical alerts, live views, and custom dashboards.
At Dynatrace, we’re constantly improving our AWS monitoring capabilities. Monitor and understand additional AWS services. Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Get up to 300 new AWS metrics out of the box. Updated AWS monitoring policy.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. Monitoring such an application is easy.
Open-source metric sources automatically map to our Smartscape model for AI analytics. We’ve just enhanced Dynatrace OneAgent with an open metric API. Here’s a quick overview of what you can achieve now that the Dynatrace Software Intelligence Platform has been extended to ingest third-party metrics. Dynatrace news.
Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads. Monitoring the cluster nodes preemptively addresses potential issues, ensuring the system operates smoothly.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Synthetic HTTP monitors are executed in the hardening stage.
Dynatrace also named a Gartner Customers’ Choice Customers also named Dynatrace a Customers’ Choice in the latest Gartner® Peer Insights™ Voice of the Customer: Application Performance Monitoring report, from November 2022. In these two reports, Dynatrace is the only provider to be recognized as a Leader and as a Customers’ Choice.
Despite its benefits, serverless computing introduces additional monitoring challenges for developers and IT Operations, particularly in understanding dependencies and identifying issues in the end-to-end traces that flow through a complex mix of dynamic and hybrid on-premise/cloud environments. So stay tuned! Optimize timing hotspots.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. Many technologies expose their metrics in the Prometheus data format. Easily gain actionable insights with the Dynatrace Extension for Prometheus metrics. Prometheus in Kubernetes ?and
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. The batch job creates a high-level summary that captures some key comparison metrics.
Dynatrace Visually complete is a point-in-time web performance metric that measures when the visual area of a page has finished loading. Dynatrace is the only solution that provides these user experience metrics consistently for real user monitoring as well as for synthetic monitors. More precisely, you can now: .
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content