This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The improved UI of the new Synthetic app makes managing your synthetic tests and analyzing their results easier and more effective. Exploratory analytics now cover more bespoke scenarios, allowing you to access any element of test results stored in the Dynatrace Grail data lakehouse.
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performance tuning needs. In 2025, we expect to see the first releases, so youll be able to test out this innovative technology.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. What is the difference between monitoring and observability? Is observability really monitoring by another name? What is observability? In short, no.
My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. Recently, we’ve expanded our digital experience monitoring to cover the entire customer journey, from conversion to fulfillment.
Digital experience monitoring (DEM) is crucial for organizations to meet this demand and succeed in today’s competitive digital economy. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
Current synthetic capabilities Dynatrace Synthetic Monitoring is a powerful tool that provides insight into the health of your applications around the clock and as they’re perceived by your end users worldwide. into NAM test definitions. But is this all you need? Our script, available on GitHub , provides details.
As businesses compete for customer loyalty, it’s critical to understand the difference between real-user monitoring and synthetic user monitoring. These development and testing practices ensure the performance of critical applications and resources to deliver loyalty-building user experiences. What is real user monitoring?
The OpenTelemetry community created its demo application, Astronomy Shop, to help developers test the value of OpenTelemetry and the backends they send their data to. The post Demo: Monitoring the OpenTelemetry demo app Astronomy Shop with Dynatrace Dashboards appeared first on Dynatrace news.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
Take your monitoring, data exploration, and storytelling to the next level with outstanding data visualization All your applications and underlying infrastructure produce vast volumes of data that you need to monitor or analyze for insights. Based on the color, you immediately see if any SLOs are off track.
As a result, API monitoring has become a must for DevOps teams. So what is API monitoring? What is API Monitoring? API monitoring is the process of collecting and analyzing data about the performance of an API in order to identify problems that impact users. The need for API monitoring. Ways to monitor APIs.
Real user monitoring can help you catch these issues before they impact the bottom line. What is real user monitoring? Real user monitoring (RUM) is a performance monitoring process that collects detailed data about a user’s interaction with an application. Real user monitoring collects data on a variety of metrics.
Cloud-native technologies are driving the need for organizations to adopt a more sophisticated IT monitoring approach to satisfy the competitive demands of modern business. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends. Agility and innovation.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. The ability to scale testing as part of the software development lifecycle (SDLC) has proven difficult.
Real-time monitoring : The periodic reports from cloud service providers lack real-time monitoring and actionable insights, limiting IT teams’ ability to make immediate adjustments to reduce carbon footprints. We implemented a wasted energy metric in the app to enhance practitioner actionability.
Automated AI-powered analytics are necessary to match the scale of monitoring these enterprises require. Our journey began in 2019 with the introduction of the Dynatrace Citrix monitoring extension. Listen, learn, improve, and repeat The latest update to the Citrix monitoring extension is now available.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. It has undergone security analysis and testing in accordance with AWS requirements.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. What is digital experience monitoring? Primary digital experience monitoring tools.
Synthetic testing simulates real-user behaviors within an application or service to pinpoint potential problems. Here’s a look at why this testing matters, how it works, and what companies need to get the most from this approach. What is synthetic testing? RUM, meanwhile, requires actual users.
So, whenever your end users’ digital experience is bogged down by a problem, whether it’s the result of a synthetic test (browser and synthetic), mobile app monitoring, or web monitoring, your teams need to see the most pertinent information about the impact and the root cause at a glance.
In this blog post, we’ll examine one such case where we use the Sentry JavaScript SDK to instrument Jest (which runs our frontend test suite) and how we addressed the issues that we found. We have high-level metrics for how well (or not) our CI is performing.
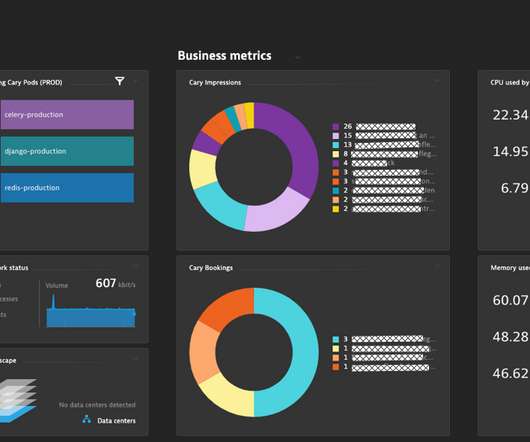
Monitoring and observability are important topics for any developer, architect, or Site Reliability Engineer (SRE), and this holds true independent of the language or runtime of choice. Relevant infrastructure, operations and business metrics on a single Dynatrace dashboard for CARY. Dynatrace news. Guidance for Django.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications. With VA’s heavy focus on security, the platform enables developers to incorporate security testing for applications during development. “In
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded.
Now that you’ve deployed your code, it’s time to monitor it, collect data, and analyze your metrics. Without application performance monitoring in place, you can’t accurately determine how well things are going. The first step to gather this type of data is application monitoring. Your job is done, right? If so, where?
As organizations develop more applications and microservices, they are discovering they also need to run more performance tests in the same amount of time or less to meet service-level objectives (SLOs) that fulfill service-level agreements (SLAs). How can organizations address this process bottleneck and run more tests in less time?
To explore this issue, we asked participants the following question: Which of your teams have access to production monitoring data? Three quick conclusions: 1) More than 80% of the respondents claim that their Development teams have access to production monitoring data. Production monitoring data: The lifeblood of cross-talented teams.
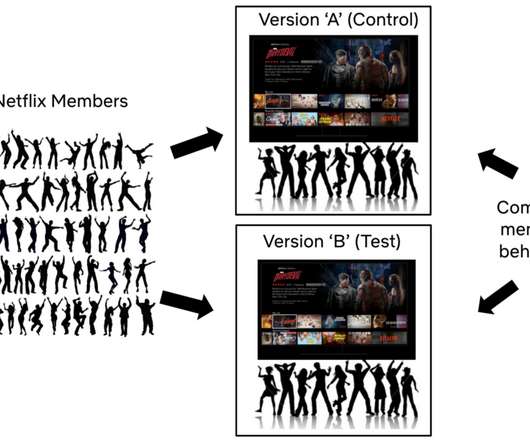
Martin Tingley with Wenjing Zheng , Simon Ejdemyr , Stephanie Lane , and Colin McFarland This is the second post in a multi-part series on how Netflix uses A/B tests to inform decisions and continuously innovate on our products. An A/B test is a simple controlled experiment. Some metrics will be specific to the given hypothesis.
The responsibility of developers keeps growing, and as mobile apps get more complex, new tools for mobile performance monitoring and testing are being born. Speed, UX, availability, and frequency of updates are increasingly important with mobile apps. But this process usually takes a couple of weeks.
Monitoring application and website performance has become critical to delivering a smooth digital experience to users. This directly impacts key business metrics like customer conversions, engagement, and revenue. To proactively identify and fix performance problems, modern DevOps teams rely heavily on monitoring solutions.
As we look forward to 2021, Synthetic Monitoring continues to be as important as ever in understanding the performance of your app or website. But your synthetic monitoring is only as good as the tool you're using and there are a lot of product choices. Since selecting the best one for you is critical, the choice can be overwhelming.
A website needs to be constantly tested and optimized to be in line with Google's web and SEO guidelines. Core Web Vitals is a key performance metric that analyzes the website's performance by investigating the data and provides a strategic platform to scale up the website's user experience. What Is Web Performance Testing?
You will need to know which monitoringmetrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
The three strategies we will discuss today are AB Testing , Replay Testing, and Sticky Canaries. To launch Phase 1 safely, we used AB Testing. To launch Phase 2 safely, we used Replay Testing and Sticky Canaries. We knew we could test the same query with the same inputs and consistently expect the same results.
Credits on content go to him and the work he has been doing around performance & resiliency testing automation. Our Application Performance Management (APM) and load test team at T-Systems MMS helps our customers reduce the risk of failed releases. Automation : Single load test executions can be repeated and tracked.
To tackle this problem Christian experimented with automatically creating Dynatrace Synthetic Tests as part of his GitLab Pipelines. Create Synthetic Test : Query the readiness endpoint and ingress of the deployed service, then create a Dynatrace Synthetic Test through the Dynatrace Synthetic API.
In today’s complex IT environments, the sheer volume of data created makes it impossible for humans to monitor, comprehend, or troubleshoot problems before they impact the experience of your end users. Recently, we simplified StatsD, Telegraf, and Prometheus observability by allowing you to capture and analyze all your custom metrics.
After a new build gets deployed and automated tests executed, SLIs are evaluated against their SLOs and, depending on that result, a build is considered good (promoted) or bad (rolled back). “ The app description and supporting files such as load testing scripts are on the Keptn Example GitHub. This is what this blog is all about.
A lot of companies—even if they are aware that performance is key to their business—are often unsure of how, when, or where performance testing sits within their development lifecycle. To make things worse, they’re also usually unsure whose responsibility performance measuring and monitoring is.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. This blog post explores the Reliability metric , which measures modern operational practices. Why reliability? While it is powerful, it presents several challenges that affect its adoption.
Our previous blog post presented replay traffic testing — a crucial instrument in our toolkit that allows us to implement these transformations with precision and reliability. By tracking metrics only at the level of service being updated, we might miss capturing deviations in broader end-to-end system functionality.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content