This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. The Business Flow app Business Flow, built with AppEngine, simplifies the configuration, monitoring, and analysis of business processes.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. What is the difference between monitoring and observability? Is observability really monitoring by another name? What is observability? In short, no.
This trend is prompting advances in both observability and monitoring. But exactly what are the differences between observability vs. monitoring? Monitoring and observability provide a two-pronged approach. To get a better understanding of observability vs monitoring, we’ll explore the differences between the two.
Digital experience monitoring (DEM) is crucial for organizations to meet this demand and succeed in today’s competitive digital economy. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels.
Monitoring and observability are two key concepts that facilitate this process, offering valuable visibility into the health and performance of systems. In this article, we will explore the differences between monitoring and observability, provide examples to illustrate their applications and highlight their respective benefits.
In fact, according to a Dynatrace global survey of 1,300 CIOs , 99% of enterprises utilize a multicloud environment and seven cloud monitoring solutions on average. What is cloud monitoring? Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
As businesses compete for customer loyalty, it’s critical to understand the difference between real-user monitoring and synthetic user monitoring. However, not all user monitoring systems are created equal. What is real user monitoring? RUM gathers information on a variety of performance metrics.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business processmonitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented.
Let’s explore some of the advantages of monitoring GitHub runners using Dynatrace. By integrating Dynatrace with GitHub Actions, you can proactively monitor for potential issues or slowdowns in the deployment processes. In the final step of the workflow, a JavaScript processes the API responses.
Current synthetic capabilities Dynatrace Synthetic Monitoring is a powerful tool that provides insight into the health of your applications around the clock and as they’re perceived by your end users worldwide. Combined with Dynatrace OneAgent ® , you gain a precise view of the status of your systems at a glance.
Cloud-native technologies are driving the need for organizations to adopt a more sophisticated IT monitoring approach to satisfy the competitive demands of modern business. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends. Agility and innovation.
For example, Dynatrace recently introduced the extraction of log-based metrics for JSON logs. Advanced processing on your observability platform unlocks the full value of log data. Dynatrace now includes powerful log-processing capabilities for all types of log data. and product.quantity extracted automatically.
Davis is the causational AI from Dynatrace that processes billions of events and dependencies and constantly analyzes your IT infrastructure. Customize monitoring for a specific area of your IT infrastructure. Dynatrace metric events offer the flexibility needed to customize your anomaly detection configuration.
But are observability platforms—born from the collision between the demands of cloud computing and the limitations of APM and infrastructure monitoring—the best solution for managing business analytics? Observability fault lines The monitoring of complex and dynamic IT systems includes real-time analysis of baselines, trends, and anomalies.
Many of our customers—the world’s largest enterprises—have embraced the Dynatrace SaaS approach to monitoring, which provides critical business insights powered by AI and automation for globally-distributed, heterogeneous IT landscapes. New self-monitoring environment provides out-of-the-box insights and custom alerting.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. Logs can include data about user inputs, system processes, and hardware states. What is log monitoring? Dynatrace news. billion in 2020 to $4.1
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
Automated AI-powered analytics are necessary to match the scale of monitoring these enterprises require. Our journey began in 2019 with the introduction of the Dynatrace Citrix monitoring extension. Listen, learn, improve, and repeat The latest update to the Citrix monitoring extension is now available.
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. What is digital experience monitoring? Primary digital experience monitoring tools.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
Fluentd is an open-source data collector that unifies log collection, processing, and consumption. It collects, processes, and outputs log files to and from a wide variety of technologies. Processing plugins parse (normalize), filter, enrich (tagging), format, and buffer log streams.
The five key metrics to improve customer satisfaction To help turn this around, Dynatrace makes available its unified observability platform, which captures all CX interactions and transactions in an automated, intelligent manner – including user session replays. When combined, key metrics will generate an accurate CX index score.
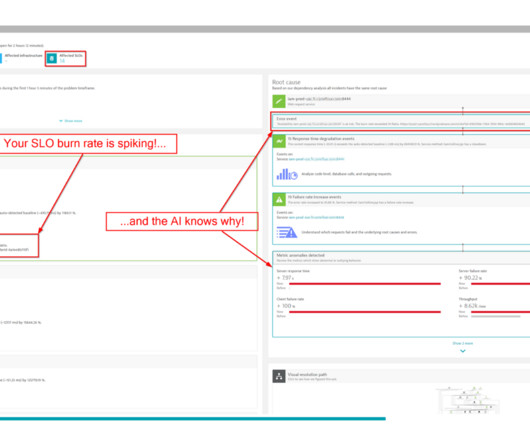
SLO monitoring and alerting on SLOs using error-budget burn rates are critical capabilities that can help organizations achieve that goal. SLOs are specifically processedmetrics that help businesses balance breakthroughs with reliability. What is SLO monitoring? And what is an error budget burn rate?
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough. What is OpenTelemetry?
Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications. This is a continuous process,” Fuqua said. It’s an enterprise product that we use to help modernize the VA,” Fuqua said.
Business processes support virtually all aspects of an organizations operations. Theyre often categorized by their function; core processes directly create customer value, support processes increase departmental efficiency, and management processes drive strategic goals and compliance.
Advanced AI applications using OpenAI services don’t just forward user input to OpenAI models; they also require client-side pre- and post-processing. It shows critical SLOs for latency and availability, as well as the most important OpenAI generative AI service metrics, such as response time, error count, and the overall number of requests.
To provide “quality signals that are essential to delivering a great user experience on the web,” Google introduced their Core Web Vitals initiative last year, advocating the Largest contentful paint , Cumulative layout shift , and First input delay metrics. with: Aggregated field metrics?rather?than?valuable?details
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
In today’s complex IT environments, the sheer volume of data created makes it impossible for humans to monitor, comprehend, or troubleshoot problems before they impact the experience of your end users. Recently, we simplified StatsD, Telegraf, and Prometheus observability by allowing you to capture and analyze all your custom metrics.
Using OpenTelemetry, developers can collect and process telemetry data from applications, services, and systems. Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics.
One issue that often complicates this process is the "noisy neighbor" problem. In this blog post, we'll reveal how we leveraged eBPF to achieve continuous, low-overhead instrumentation of the Linux scheduler, enabling effective self-serve monitoring of noisy neighbor issues.
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performance tuning needs. Semantic Conventions, or semconv, are the standard that makes it all possible.
Agricultural businesses use IoT sensors to automate irrigation systems, while mining and water supply organizations traditionally rely on SCADA to optimize and monitor water distribution, quality, and consumption. Both methods allow you to ingest and process raw data and metrics.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. Monitoring such an application is easy.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. This is significant when coupled with the OpenShift platform.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. When organizations implement SLOs, they can improve software development processes and application performance. The performance SLO needs a custom SLI metric, which you can configure as follows.
Dynatrace OpenPipeline is a new stream processing technology that ingests and contextualizes data from any source. For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards. Business processmonitoring and optimization.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. For instance, in a web shop, sales might vary by day of the week.
Observability and monitoring as a source of truth. To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. To provide actionable answers monitoring systems store, baseline, and analyze telemetry data.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content