This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As an open-source project, OpenTelemetry sets standards for telemetry data sets and works with a wide range of systems and platforms to collect and export telemetry data to backend systems. Semconv for HTTP Spans quite possibly the most important signal have been declared stable, and HTTP Metrics will hopefully soon follow.
These are just a few of the open-source technologies you may encounter as you research observability solutions for managing complex multicloud IT environments and the services that run on them. Of these open-source observability tools, one stands out. Monitoring begins here. Dynatrace news. What is OpenTelemetry?
As a solution, teams often adopt opensource observability tools like OpenTelemetry to gain situational awareness of their cloud-native environments. Opensource observability tools help address cloud complexity. Using open-source tools to tame cloud complexity can lead to data silos.
Andreas Grabner, DevOps Activist at Dynatrace, took to the virtual stage at the recent Dynatrace Perform conference to describe how the opensource Keptn project automates the configuration of observability tools, dashboards, and alerting based on service-level objectives (SLOs). Why is automated orchestration critical?
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. Organizations usually implement observability using a combination of instrumentation methods including open-source instrumentation tools, such as OpenTelemetry.
Kubernetes is a widely used opensource system for container orchestration. Service-level objectives are typically used to monitor business-critical services and applications. This feature is valuable for platform owners who want to monitor and optimize their Kubernetes environment.
Today’s organizations are constantly enhancing their systems and services as new opportunities arise, inspiring new forms of collaboration while relying on open ecosystems and opensource software. Opensource software is an example of the value created in an open ecosystem.
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. Histograms are commonly used to define and monitor service-level objectives (SLOs).
Some time ago Federico Toledo published Performance Testing with OpenSource Tools- Busting The Myths. Otherwise we wouldn’t see so many commercial tools built on the top of opensource including BlazeMeter (it is ironic that the article is posted on the BlazeMeter site), Flood, and OctoPerf.
In the dynamic world of cloud-native technologies, monitoring and observability have become indispensable. However, managing its health and performance efficiently necessitates a robust monitoring solution. Kubernetes, the de-facto orchestration platform, offers scalability and agility.
Welcome back to the blog series where we provide you with deep dives into the latest observability awesomeness from Dynatrace , demonstrating how we bring scale, zero configuration, automatic AI driven alerting, and root cause analysis to all your custom metrics, including opensource observability frameworks like StatsD, Telegraf, and Prometheus.
In Part 1 we explored how you can use the Davis AI to analyze your StatsD metrics. In Part 2 we showed how you can run multidimensional analysis for external metrics that are ingested via the OneAgent Metric API. In Part 3 we discussed how the Davis AI can analyze your metrics from scripting languages like Bash or PowerShell.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
Welcome to the blog series where we give you a deeper dive into the latest awesomeness around Dynatrace : how we bring scale, zero configuration, automatic AI driven alerting, and root cause analysis to all your custom metrics, including opensource observability frameworks like StatsD, Telegraf, and Prometheus.
Over the last year, Dynatrace extended its AI-powered log monitoring capabilities by providing support for all log data sources. We added monitoring and analytics for log streams from Kubernetes and multicloud platforms like AWS, GCP, and Azure, as well as the most widely used open-source log data frameworks.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Dynatrace news.
In Part 1 we explored how you can use the Davis AI to analyze your StatsD metrics. Part 2 showed how to run multidimensional analysis for external metrics that are ingested via the OneAgent Metric API. In Part 3 we discussed how the Davis AI can analyze your metrics from scripting languages like Bash or PowerShell.
To remain flexible in observing all technologies used in their organization, some companies choose open-source solutions, which allow them to stay vendor-neutral. Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Here’s how it works. of Micrometer. of Micrometer.
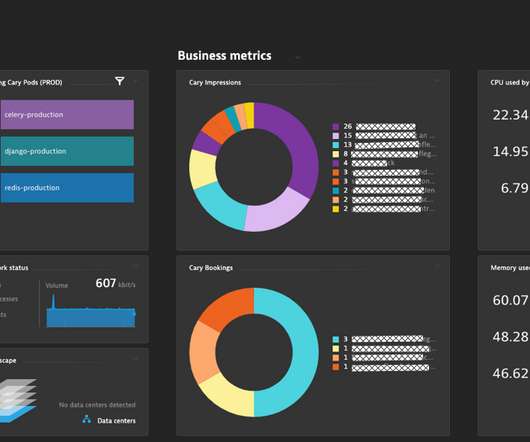
Monitoring and observability are important topics for any developer, architect, or Site Reliability Engineer (SRE), and this holds true independent of the language or runtime of choice. Relevant infrastructure, operations and business metrics on a single Dynatrace dashboard for CARY. Dynatrace news. Guidance for Django.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. Enterprise-grade observability for custom OpenTelemetry metrics from AWS. Dynatrace news.
Prometheus is an open-sourcemonitoring and alerting toolkit for services and applications that run in containers. Prometheus collects metrics from a number endpoints that expose metrics in the OpenMetrics format. The Dynatrace AMP extension enables you to easily ingest Prometheus metrics into Dynatrace.
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. AWS monitoring best practices. Automate monitoring tasks.
Every software development team grappling with Generative AI (GenAI) and LLM-based applications knows the challenge: how to observe, monitor, and secure production-level workloads at scale. Production performance monitoring: Service uptime, service health, CPU, GPU, memory, token usage, and real-time cost and performance metrics.
Observability is the new standard of visibility and monitoring for cloud-native architectures. It’s powered by vast amounts of collected telemetry data such as metrics, logs, events, and distributed traces to measure the health of application performance and behavior. Observability brings multicloud environments to heel.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. OpenTelemetry, the opensource observability tool, has emerged as an industry-standard solution for instrumenting application telemetry data to make it observable. What is OpenTelemetry?
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012. What is Prometheus?
Welcome back to the blog series where we provide you with deeper dives into the latest observability awesomeness from Dynatrace , demonstrating how we bring scale, zero configuration, automatic AI-driven alerting, and root cause analysis to all your custom metrics, including opensource observability frameworks like StatsD, Telegraf, and Prometheus.
Prometheus is one of many open-source projects managed by the Cloud Native Computing Foundation (CNCF). It is monitoring software that integrates with a wide range of systems natively or through the use of plugins. Prometheus can collect metrics about your application and infrastructure.
Dynatrace OneAgent is great for monitoring the full stack. While this will give you a lot of information about the health of these components, sometimes a simple synthetic monitor is sufficient. Third-party synthetic monitors. Visualize your synthetic monitor data. Easy and flexible infrastructure monitoring.
Are you interested in open-source observability but lack the knowledge to just dive right in? This workshop is for you, designed to expand your knowledge and understanding of open-source observability tooling that is available to you today.
As one of the most popular open-source Kubernetes monitoring solutions, Prometheus leverages a multidimensional data model of time-stamped metric data and labels. The platform uses a pull-based architecture to collect metrics from various targets.
A metric crossed a threshold. Over the years we’ve learned from on-call engineers about the pain points of application monitoring: too many alerts, too many dashboards to scroll through, and too much configuration and maintenance. Metrics are a key part of understanding application health. Client metrics and QoE changes.
Fluentd is an open-source data collector that unifies log collection, processing, and consumption. All metrics, traces, and real user data are also surfaced in the context of specific events. With Dynatrace, you can create custom metrics based on user-defined log events. Dynatrace news. What is Fluentd?
Open-sourcemetricsources automatically map to our Smartscape model for AI analytics. We’ve just enhanced Dynatrace OneAgent with an openmetric API. Here’s a quick overview of what you can achieve now that the Dynatrace Software Intelligence Platform has been extended to ingest third-party metrics.
This year I wrote two open-source apps for Dynatrace users. Wouldn’t it be great if I had an industry-leading software intelligence platform to monitor these apps, pinpoint root causes of slow performance or errors, and gain insights about my users’ experience? Agentless RUM, OpenKit, and Metric ingest to the rescue!
Kubernetes (K8s) is the platform of choice for many organizations, providing a portable, extensible, open-source solution designed to streamline containerized workload oversight. According to InfoQ , Kubernetes monitoring offers substantial benefits for container management, but it’s not a complete platform in and of itself.
If we think back to just a few years ago when most application workloads were primarily monolithic and deployed on-premise, it was fairly simple to gain observability by collecting some logs, metrics and traces, since all the infrastructure was self-owned and the scale was manageable. Importance of W3C Trace Context.
Are you interested in open-source observability, but lack the knowledge to just dive right in? This workshop is for you, designed to expand your knowledge and understanding of open-source observability tooling that is available to you today.
The main purpose of this article and use case is to scrape AWS CloudWatch metrics into the Prometheus time series and to visualize the metrics data in Grafana. These tools give greater visibility other than collecting the metrics also, where we can set up critical alerts, live views, and custom dashboards.
In order to accomplish this, one of the key strategies many organizations utilize is an opensource Kubernetes environment, which helps build, deliver, and scale containerized Cloud Native applications. Today, most thought-leaders break down Observability into three pillars; metrics, distributed traces and logs.
Docker Engine is built on top containerd , the leading open-source container runtime, a project of the Cloud Native Computing Foundation (DNCF). Kubernetes is an open-source container orchestration platform for managing, automating, and scaling containerized applications. Built-in monitoring. What is Kubernetes?
Are you interested in open-source observability, but lack the knowledge to just dive right in? This workshop is for you, designed to expand your knowledge and understanding of open-source observability tooling that is available to you today.
TiDB is an open-source, distributed SQL database that supports Hybrid Transactional/Analytical Processing (HTAP) workloads. It's challenging to troubleshoot issues in a distributed database because the information about the system is scattered in different machines. Before version 4.0,
Data quality and drift: Monitoring the quality and characteristics of training and runtime data to detect significant changes that might impact model accuracy. OpenTelemetry has become a standard for collecting traces, metrics, and logs. This includes the monitoring of AI-related costs to ensure they remain within acceptable margins.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content