This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. What is the difference between monitoring and observability? Is observability really monitoring by another name? What is observability? In short, no.
Monitoring and observability are two key concepts that facilitate this process, offering valuable visibility into the health and performance of systems. In this article, we will explore the differences between monitoring and observability, provide examples to illustrate their applications and highlight their respective benefits.
In the dynamic world of cloud-native technologies, monitoring and observability have become indispensable. However, managing its health and performance efficiently necessitates a robust monitoring solution. Kubernetes, the de-facto orchestration platform, offers scalability and agility.
Current synthetic capabilities Dynatrace Synthetic Monitoring is a powerful tool that provides insight into the health of your applications around the clock and as they’re perceived by your end users worldwide. Compared to other solutions I have tested, Dynatrace NAM monitors are the most configurable which is to my liking.
For more: Read the Report Agile development practices must be supported by an agile monitoring framework. This is particularly true when performance metrics and reliability shape customer satisfaction and loyalty, directly influencing the bottom line.
Effortlessly analyze IBM i Performance with the new Dynatrace extension Dynatrace has created a new version of its popular extension that is faster, offers better interactive pages, and includes more metrics, metadata, and analytics without having to install anything on your mainframe infrastructure. It’s all monitored remotely !
Digital experience monitoring (DEM) is crucial for organizations to meet this demand and succeed in today’s competitive digital economy. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels.
Also, APISIX integrates with Prometheus through its plugin that exposes upstream nodes (multiple instances of a backend API service that APISIX manages) health check metrics on the Prometheus metrics endpoint typically, on URL path /apisix/prometheus/metrics.
AWS provides local metrics and monitoring via AWS CloudWatch. But things will get complicated when we need to monitor multiple applications from all these accounts to extrapolate and make decisions based on the metrics. One AWS account, one AWS region, etc.
Cloud-native technologies are driving the need for organizations to adopt a more sophisticated IT monitoring approach to satisfy the competitive demands of modern business. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends.
One of the primary responsibilities of Site reliability engineers (SREs) in large organizations is to monitor the golden metrics of their applications, such as CPU utilization, memory utilization, latency, and throughput.
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
However, the extended infrastructure of CDNs requires diligent monitoring to ensure optimal performance and identify potential issues. It involves monitoring and analyzing various metrics and data points to ensure the CDN functions as expected. CDNs play a crucial role in enhancing website performance and user experience.
But are observability platforms—born from the collision between the demands of cloud computing and the limitations of APM and infrastructure monitoring—the best solution for managing business analytics? Observability fault lines The monitoring of complex and dynamic IT systems includes real-time analysis of baselines, trends, and anomalies.
In fact, according to a Dynatrace global survey of 1,300 CIOs , 99% of enterprises utilize a multicloud environment and seven cloud monitoring solutions on average. What is cloud monitoring? Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
Most business processes are not monitored. Business processes can be quite complex, often including conditional branches and loops; many business process monitoring initiatives are abandoned or simplified after attempting to map the process flow. Some use cases might benefit from isolated step metrics, but these are rare.
It is important to highlight that most older monitoring systems were considered inefficient due to their operational overhead. Pixie offers monitoring, telemetry, metrics, and more with less than 5% CPU overhead and latency degradation during data collection.
Automated AI-powered analytics are necessary to match the scale of monitoring these enterprises require. Our journey began in 2019 with the introduction of the Dynatrace Citrix monitoring extension. Listen, learn, improve, and repeat The latest update to the Citrix monitoring extension is now available.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Monitoring application and website performance has become critical to delivering a smooth digital experience to users. This directly impacts key business metrics like customer conversions, engagement, and revenue. To proactively identify and fix performance problems, modern DevOps teams rely heavily on monitoring solutions.
Traditional insight into HTTP monitor execution details For nearly two thousand Dynatrace customers, Dynatrace Synthetic HTTP monitors provide insights into the health of monitored endpoints worldwide and around the clock. It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors.
An hourly rate for Infrastructure Monitoring The Dynatrace Platform Subscription (DPS) offers a flat rate for Infrastructure Monitoring , providing observability for cloud platforms, containers, networks, and data center technologies with no limits on host memory and with AIOps included.
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. By treating processes as assets with measurable key performance indicators (KPIs), business process monitoring helps IT and business teams align toward shared business goals.
The five key metrics to improve customer satisfaction To help turn this around, Dynatrace makes available its unified observability platform, which captures all CX interactions and transactions in an automated, intelligent manner – including user session replays. When combined, key metrics will generate an accurate CX index score.
Prometheus is an open-source systems monitoring and alerting tool kit that enables you to hit the ground running with discovering, collecting, and querying your observability today. Dive right into a free, online, self-paced, hands-on workshop introducing you to Prometheus.
Let’s explore some of the advantages of monitoring GitHub runners using Dynatrace. By integrating Dynatrace with GitHub Actions, you can proactively monitor for potential issues or slowdowns in the deployment processes. This customization ensures that only the relevant metrics are extracted, tailored to the users needs.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications. The post Container monitoring for VA Platform One helps VA achieve workload performance appeared first on Dynatrace news.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
Dynatrace is proud to provide deep monitoring support for Azure Linux as a container host operating system (OS) platform for Azure Kubernetes Services (AKS) to enable customers to operate efficiently and innovate faster. Why monitor Azure Linux container host for AKS? How Can Dynatrace Monitor Azure Linux container host for AKS?
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. Monitoring such an application is easy.
As one of the most popular open-source Kubernetes monitoring solutions, Prometheus leverages a multidimensional data model of time-stamped metric data and labels. The platform uses a pull-based architecture to collect metrics from various targets.
Teams are using concepts from site reliability engineering to create SLO metrics that measure the impact to their customers and leverage error budgets to balance innovation and reliability. Nobl9 integrates with Dynatrace to gather SLI metrics for your infrastructure and applications using real-time monitoring or synthetics.
Monitoring and maintaining these applications daily is very challenging and we need proper metrics in place to measure and take action. This is where the importance of implementing SLAs, SLOs, and SLIs comes into the picture and it helps in effective monitoring and maintaining the system performance.
Prometheus is a powerful monitoring tool that provides extensive metrics and insights into your infrastructure and applications, especially in k8s and OCP (enterprise k8s). In this article, we will explore how to count worker nodes and track changes in resources effectively using PromQL.
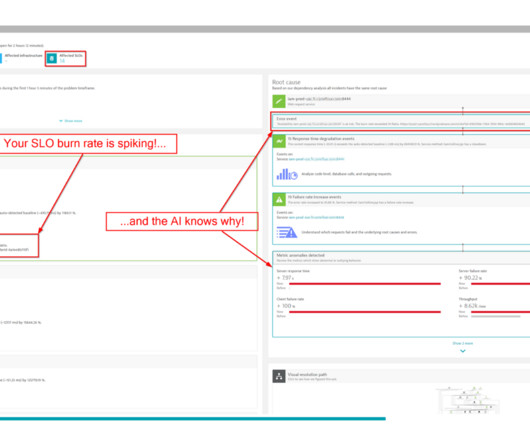
SLO monitoring and alerting on SLOs using error-budget burn rates are critical capabilities that can help organizations achieve that goal. SLOs are specifically processed metrics that help businesses balance breakthroughs with reliability. What is SLO monitoring? And what is an error budget burn rate?
You need to find the right tools to monitor, track and trace these systems by analyzing outputs through metrics, logs, and traces. One of the most common examples is the adoption of microservices. However, this also creates new challenges when it comes to observability.
A few years ago, we were paged by our SRE team due to our Metrics Alerting System falling behind — critical application health alerts reached engineers 45 minutes late! Hence, we started down the path of alert evaluation via real-time streaming metrics. This has proven to be valuable towards reducing Mean Time to Recover (MTTR).
Dynatrace with Red Hat OpenShift monitoring stands out for the following reasons: With infrastructure health monitoring and optimization, you can assess the status of your infrastructure at a glance to understand resource consumption and thus optimize resource allocation for cost efficiency.
In this blog post, we'll reveal how we leveraged eBPF to achieve continuous, low-overhead instrumentation of the Linux scheduler, enabling effective self-serve monitoring of noisy neighbor issues. Learn how Linux kernel instrumentation can improve your infrastructure observability with deeper insights and enhanced monitoring.
Dynatrace captures all your data, including host and application metrics, basic-network metrics, real-user metrics, mobile metrics, cloud-infrastructure metrics, log metrics, and much more. Security: Data is stored securely in the Dynatrace cloud (powered by Azure).
Once the one-time configuration is done, metric data will be available in the monitoring account automatically. Once the metric data from all the AWS accounts are available in the monitoring account, you can create CW alarms or dashboards for your AWS Organization and monitor all your resources from a single account.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
We’ve worked closely with our partner AWS to deliver a complete, end-to-end picture of your cloud environment that includes monitoring support for all AWS services. Dynatrace can monitor AWS Lambda functions automatically, just like any other service. Dynatrace news. and Python via traces.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content