This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An application software generates user metrics on a daily basis, which can be used for reports or analytics. For a typical web application with a backend, it is a good choice when we want to consider a managed database that can scale both vertically and horizontally.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. If you’ve read about observability, you likely know that collecting the measurements of logs, metrics, and distributed traces are the three key pillars to achieving success.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023. What’s ahead in 2023.
DORA ( DevOps Research and Assessment ) metrics, developed by the DORA team have become a standard for measuring the efficiency and effectiveness of DevOps implementations. What Are DORA Metrics? DORA metrics are a set of four key performance indicators (KPIs) that help organizations evaluate their software delivery performance.
Recently, I encountered a task where a business was using AWS Elastic Beanstalk but was struggling to understand the system state due to the lack of comprehensive metrics in CloudWatch. By default, CloudWatch only provides a few basic metrics such as CPU and Networks.
You can now: Kickstart your creation journey using ready-made dashboards Accelerate your data exploration with seamless integration between apps Start from scratch with the new Explore interface Search for known metrics from anywhere Let’s look at each of these paths through an end-to-end use case focused on Kubernetes monitoring.
Imagine you’re using a lot of OpenTelemetry and Prometheus metrics on a crucial platform. A histogram is a specific type of metric that allows users to understand the distribution of data points over a period of time. You’re gathering a lot of data, but you can’t make sense of it. What are histograms, and why use them?
Prometheus is a powerful monitoring tool that provides extensive metrics and insights into your infrastructure and applications, especially in k8s and OCP (enterprise k8s). In this article, we will explore how to count worker nodes and track changes in resources effectively using PromQL.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you. For our example dashboard, we’ll only focus on some selected key infrastructure metrics. Click on Select metric. Change it now to sum.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Depending on the environment, the different information types provide indicators that reveal potential problems for your customers.
Select any execution you’re interested in to display its details, for example, the content response body, its headers, and related metrics. All metrics and events storing information about execution details are available for further exploratory analytics utilizing Dashboards, Notebooks, or Davis CoPilot.
The five key metrics to improve customer satisfaction To help turn this around, Dynatrace makes available its unified observability platform, which captures all CX interactions and transactions in an automated, intelligent manner – including user session replays. When combined, key metrics will generate an accurate CX index score.
For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards. Within the target pipeline, you can also define processing rules, extract metrics, set the security context, and define retention periods.
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. If you don’t have one, you can use a trial account.
Combined with Microsoft Sentinel, Dynatrace automation and AI capabilities provide SecOps teams with deeper intelligence to detect attacks, vulnerabilities, audit logs, and problem events based on metrics, logs, and traces it collects from monitored environments.
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. Seasonal Baseline: Ideal for metrics with predictable seasonal patterns, this option leverages Davis AI to create a confidence band based on historical data, accounting for expected variations.
Finally, Dynatrace requires metrics data to be sent with delta temporality , not cumulative temporality. This means that youll need to include the cumulativetodelta processor in: Your Collector configuration ( cumulativetodelta ) Your metrics pipeline ( pipelines.metrics ) Never store your Dynatrace token and tenant name in plain text.
The Carbon Impact app directly supports our customers sustainability efforts through granular real-time emissions reporting and analytics, translating host utilization metrics into their CO2 equivalent (CO2e). We implemented a wasted energy metric in the app to enhance practitioner actionability.
This data covers all aspects of CI/CD activity, from workflow executions to runner performance and cost metrics. This customization ensures that only the relevant metrics are extracted, tailored to the users needs. In the final step of the workflow, a JavaScript processes the API responses.
My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. Automate smarter using actual customer experience metrics, not just server-side data. Using causal AI, we identified and resolved performance issues automatically.
Semconv for HTTP Spans quite possibly the most important signal have been declared stable, and HTTP Metrics will hopefully soon follow. Semantic Conventions, or semconv, are the standard that makes it all possible. Other key domains, such as Databases and Messaging, are in very advanced stages and are expected to stabilize soon.
The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics. All other default policies on the service level, for example, “AutomationEngine – User” access, are now marked as Legacy.
While histograms look much like time-series bar charts, they’re different in that each bar represents a count (often termed frequency) of metric values. That way, you can compare multiple charts more easily, regardless of the metric or time span. These bars are called bins or buckets; their width represents a value range.
To calculate the service-level indicator for the Kubernetes namespace memory efficiency SLO, simply query the memory working set and request the memory metrics that are provided out of the box. However, if you require more granular information, you can adjust the levels for resource utilization monitoring accordingly.
Amazon Bedrock , equipped with Dynatrace Davis AI and LLM observability , gives you end-to-end insight into the Generative AI stack, from code-level visibility and performance metrics to GenAI-specific guardrails. Send unified data to Dynatrace for analysis alongside your logs, metrics, and traces.
OpenSearch simplifies this by providing an open-source, scalable solution for logging, metrics, and visualization. Observability has become a key component in software development as it enables the best customer experience by ensuring system health and performance and detecting systemic issues proactively.
Traditional debugging methods, including manual inspection of logs, event streams, configurations, and system metrics, can be painstakingly slow and prone to human error, particularly under pressure.
With Dynatrace, customers can utilize the full set of Azure capabilities, including metrics and data from the Azure platform, and automatically identify workflow optimization opportunities.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. It’s about uncovering insights that move business forward.
Dynatrace currently supports the following: Traces Logs Metrics What information do I need to send OpenTelemetry data to Dynatrace? Does Dynatrace support OpenTelemetry metrics? Yes, but its important to note the following: Dynatrace requires metrics data to be sent with delta temporality and not cumulative temporality.
Explore OpenTelemetry data with Dynatrace Dynatrace makes unified observability possible by storing all data in Grail, a unified and purpose-built data lakehouse optimized for storing and analyzing traces, metrics, logs, and more. With Notebooks , you can Chart, analyze, set up alerts, and forecast any of your metrics. Whats next?
Teams are using concepts from site reliability engineering to create SLO metrics that measure the impact to their customers and leverage error budgets to balance innovation and reliability. Nobl9 integrates with Dynatrace to gather SLI metrics for your infrastructure and applications using real-time monitoring or synthetics.
Imagine a ML practitioner on the Netflix Content ML team, sourcing features from hundreds of columns in our data warehouse, and creating a multitude of models against a growing suite of metrics. Subsequent versions of the model will result from experimenting with hyper parameters, tweaking feature engineering, or conducting feature diets.
So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render. We spent the next few months diving into these high-level metrics and fixing issues such as cache TTLs, flawed client assumptions, etc.
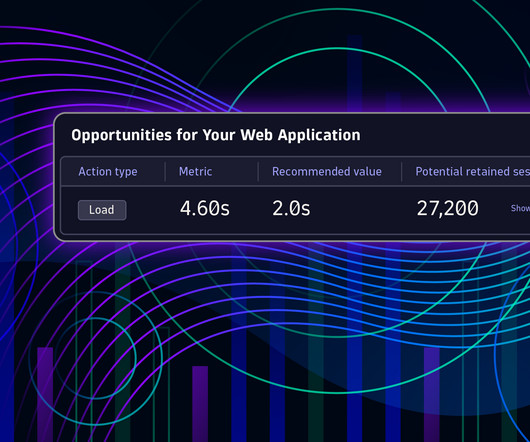
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
It also helps to have access to OpenTelemetry, a collection of tools for examining applications that export metrics, logs, and traces for analysis. Some observability vendors also provide an agent or client to automate the collection and provide contextualization of telemetry and entity data.
Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) A Kubernetes cluster (we recommend using kind) Helm, to install the demo on your Kubernetes cluster Once your Kubernetes cluster is up and running, the next step is to create a secret containing the Dynatrace API token.
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit and Fluentd were created for the same purpose: collecting and processing logs, traces, and metrics. Observability: Elevating Logs, Metrics, and Traces! What is Fluent Bit?
The addition of more and more metrics over time has only made this increasingly complex. Performance metrics to improve can be Visually Complete, Speed Index, or other timing metrics associated with the page load cycle. It predicts user behavior based on performance/error experience.
Metrics and Statistics Monitoring the performance of a RabbitMQ cluster is crucial for maintaining its efficiency and reliability. RabbitMQ provides a wealth of metrics and statistics that offer insights into various aspects of the clusters performance.
Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics. Unstructured overview: Manually scanning logs or waiting for someone to notice an error in staging is time-consuming.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content