This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. It facilitates the distribution of these learnings to other models, either through shared model weights for fine tuning or directly through embeddings.
CPU isolation and efficient system management are critical for any application which requires low-latency and high-performance computing. To achieve this level of performance, such systems require dedicated CPU cores that are free from interruptions by other processes, together with wider system tuning.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. million impression events globally every second, with each event approximately 1.2KB in size.
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency. Apache Kafka, designed for distributed event streaming, maintains low latency at scale.
Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively. This significantly increases event latency. Spark Structured Streaming can also provide consistent fault recovery for applications where latency is not a critical requirement.
You may also like: How to Properly Plan JVM Performance Tuning. While Performance Tuning an application both Code and Hardware running the code should be accounted for. For low latency, applications use Concurrent Mark and Sweep Algorithm — CMS or G1 GC. Learn how to make your Java applications performance perfectly.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. Logging is selective to cases where the old and new responses do not match.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? Stay tuned for a closer look at the innovation behind thescenes!
Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL. PostgreSQL DigitalOcean Latency Averages (ms).
Tuning thousands of parameters has become an impossible task to achieve via a manual and time-consuming approach. The optimization goal was to improve the application efficiency, that is to improve the ratio between service throughput and cloud costs while not increasing the application latency (e.g. The Akamas approach.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
95th Percentile Latency. The 95th percentile latency of queries was also 1.8 Stay tuned for my follow-on blog post with more details! Workload Throughput (Queries Per Second). Index Creation on Master. Rolling Index Creation. times higher when the index creation happened on the master server.
Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. Now that we’ve compared throughput performance, let’s take a look at ScaleGrid vs. DigitalOcean latency for MySQL. Read-Intensive Latency Benchmark. Balanced Workload Latency Benchmark.
Reduced tail latencies In both our GRPC and DGS Framework services, GC pauses are a significant source of tail latencies. For a given CPU utilization target, ZGC improves both average and P99 latencies with equal or better CPU utilization when compared to G1. No explicit tuning has been required to achieve these results.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render. The control group’s traffic utilized the legacy Falcor stack, while the experiment population leveraged the new GraphQL client and was directed to the GraphQL Shim. We then collect and analyze the performance of the two clusters.
Allegro experimented with different performance optimization options to improve Apache Kafka producer tail latency and eventually switched all its clusters to the XFS filesystem. The company used Kafka protocol sniffing, JVM profiling, and eBPF, which proved instrumental in identifying and eliminating performance bottlenecks.
Dynomite is a Netflix open source wrapper around Redis that provides a few additional features like auto-sharding and cross-region replication, and it provided Pushy with low latency and easy record expiry, both of which are critical for Pushy’s workload. As Pushy’s portfolio grew, we experienced some pain points with Dynomite.
While clustering across wide-area networks (WANs) is discouraged due to latency issues, leased links can mitigate some connectivity challenges. With 24/7 expert support, ScaleGrid assists with troubleshooting, performance tuning, and migration processes. Keeping queues short maintains a responsive and efficient RabbitMQ setup.
Traces are used for performance analysis, latency optimization, and root cause analysis. OpenTelemetry provides [extensive documentation]([link] and examples to help you fine-tune your configuration for maximum effectiveness. Capture critical performance indicators such as request latency, error rates, and resource usage.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. ScaleGrid also maintains 53% lower latency on average throughout the entire MySQL AWS performance tests.
The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. How Bulldozer leverages Spark, Protobuf and KV DAL for moving the data.
In this case, the four golden signals (latency, traffic, errors, and saturation) are derived from span attributes and DQL metric queries via Dynatrace Grail™. Based on those insights, they implemented automated validation tasks, and shifted left in their software delivery pipeline.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The subsystems all communicate with each other asynchronously via Timestone, a high-scale, low-latency priority queuing system. Warm capacity.
Storage mount points in a system might be larger or smaller, local or remote, with high or low latency, and various speeds. For example: All subfolders of the /opt directory are mounted as local, low latency, high-throughput drives, with relatively low storage capacity. Stay tuned for upcoming news about these changes.
You’re half awake and wondering, “Is there really a problem or is this just an alert that needs tuning? Telltale learns what constitutes typical health for an application, no alert tuning required. For example, a latency increase is less critical than error rate increase and some error codes are less critical than others.
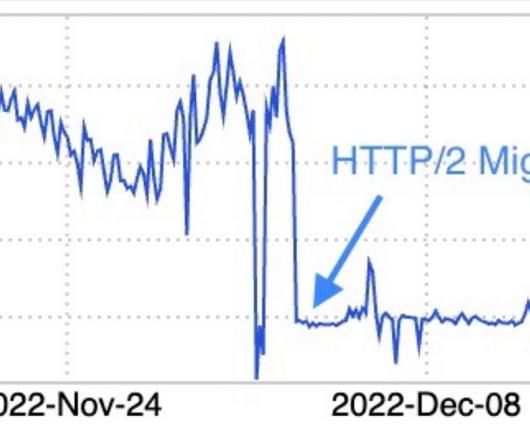
to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 To achieve these gains, the team had to optimize the Netty’s default HTTP2 stack to make it fit their needs.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
When an application is triggered, it can cause latency as the application starts. This creates latency when they need to restart. The platform builds the trigger to initiate the app. Every time the trigger executes, the function runs on an available resource. How does serverless computing tackle inefficiencies?
For example, improving latency by as little as 0.1 latency is the number one reason consumers abandon mobile sites. Fine-tuning the service-level indicators that make up quality gates will improve with the help of upcoming features. Organizations can feel the impact of even a minor roadblock in the user experience.
You can ask for the best configuration to reduce latency or improve the user experience.” And with automatic application tuning, teams spend less time on manually testing and reviewing configurations, resulting in up to five times the productivity of performance engineers, DevOps, and SREs when it comes to application optimization.
Uploading and downloading data always come with a penalty, namely latency. Figure 3: Video Processing with Index and Virtual Assembly Using virtual assembly greatly improves the latency performance of the ProRes 422 HQ proxy generation by removing one round trip of cloud downloading and cloud uploading by the physical assembler.
While there is plenty of well-documented benefits to using a connection pooler, there are some arguments to be made against using one: Introducing a middleware in the communication inevitably introduces some latency. A middleware becomes a single point of failure. Should You Use a PostgreSQL Connection Pooler?
The canary stage will determine a score based on metrics such as CPU, threads, latency, and GC pauses. Running a canary for each change and testing the AMI in production allows us to capture insights around impact on Windows updates, script changes, tuning web server configuration, among others.
Additionally, we’ve added the Philadelphia AWS Local Zone , helping to reduce latency for customers operating in the eastern U.S. This enables ScaleGrid users in Australia and nearby regions to access lower-latency services and improved performance. Stay tuned for more exciting updates in the months to come! <p>The
Higher latency and cold start issues due to the initialization time of the functions. Understanding cold-start behavior is essential to tune your cloud applications cost or performance to meet your operational needs. Enable faster development and deployment cycles by abstracting away the infrastructure complexity.
Whether tracking internal, workload-centric indicators such as errors, duration, or saturation or focusing on the golden signals and other user-centric views such as availability, latency, traffic, or engagement, SLOs-as-code enables coherent and consistent monitoring throughout the environment at scale.
In addition, compute and storage are increasingly being separated causing larger latencies for queries. This article provides the top 10 tips for performance tuning for real-world workloads when running Spark on Alluxio with data locality, giving the most bang for the buck.
This article will cover many areas that database administrators need to be aware of in order to properly license, recover, and tune a Reporting Services installation. Tuning Options. Tuning SSRS is much like any other application. Disk latency for ReportServer and ReportServerTempDB are very important. General Tuning.
These principles reduce resource usage by being more efficient and effective while lowering the end-to-end latency in data processing. Orient: Gather tuning parameters for a particular table that changed. AutoAnalyze In short, AutoAnalyze finds the best tuning/configuration parameters for a table. More processing resources.
The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Stay tuned for updates in Q1 2020. You can observe the metrics across service instances split by region (in this example, API Gateways in us-east-1 and us-east-2 ). You can also create custom charts. Requirements. AWS supporting services.
This separation allows us to tune system configuration and scaling policies independently for different event priorities and traffic patterns. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. We have also noted a great potential for further improvement by model tuning (see the section of Rollout in Production).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content