This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
Big data is generated and transported using various mediums in single requests. With the increase in the size of data, we have activities like serializing, deserializing, and transportation costs added to it. Though we are not worried about computing resources, the latency becomes an overhead.
Traces are used for performance analysis, latency optimization, and root cause analysis. The OpenTelemetry Protocol (OTLP) plays a critical role in this framework by standardizing how systems format and transport telemetry data, ensuring that data is interoperable and transmitted efficiently. Contextualize data.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Our trace data collection agent transports traces to Mantis job cluster via the Mantis Publish library.
Dynomite is a Netflix open source wrapper around Redis that provides a few additional features like auto-sharding and cross-region replication, and it provided Pushy with low latency and easy record expiry, both of which are critical for Pushy’s workload. As Pushy’s portfolio grew, we experienced some pain points with Dynomite.
For example, if there is a latency on a particular service, Dynatrace will flag this and trace its source – even if the source is a third party. We can see latency trends so we can say, ‘hey, you guys at nine o’clock at night keep having horrible latency spikes, and you’re causing a problem for our customers.’”
MQTT is an OASIS standard messaging protocol for the Internet of Things (IoT) and was designed as a highly lightweight yet reliable publish/subscribe messaging transport that is ideal for connecting remote devices with a small code footprint and minimal network bandwidth. million elements. this is configurable through enable.auto.commit.
Volt’s architecture supports energy management applications with its low-latency, high-availability data processing, making it ideal for tracking and optimizing real-time energy usage across industrial sites. Impact: AI-driven energy management leads to significant cost savings and contributes to sustainability goals.
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. HTTP/2 versus HTTP/3 protocol stack comparison ( Large preview ). What Is QUIC?
I’m jumping ahead a bit here, but the component of Snap which provides the transport and communications stack is called Pony Express. Here are the bombshell paragraphs: Our datacenter applications seek ever more CPU-efficient and lower-latency communication, which Pony Express delivers. Enter Google! Emphasis mine). Emphasis mine).
Operational Reporting is a reporting paradigm specialized in covering high-resolution, low-latency data sets, serving detailed day-to-day activities¹ and processes of a business domain. Most of the business views created on top of the Iceberg tables can tolerate a few minutes of latency.
The AWS GovCloud (US-East) Region is located in the eastern part of the United States, providing customers with a second isolated Region in which to run mission-critical workloads with lower latency and high availability.
This enables customers to serve content to their end users with low latency, giving them the best application experience. In 2011, AWS opened a Point of Presence (PoP) in Stockholm to enable customers to serve content to their end users with low latency. As well as AWS Regions, we also have 24 AWS Edge Network Locations in Europe.
The database is sending them to a transport that DBLog can consume. We use the term ‘ change log’ for that transport. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low.
The database is sending them to a transport that DBLog can consume. We use the term ‘ change log’ for that transport. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low.
The transfer mechanism for transport of bytes is a function of the data store. To serve such applications, Netflix Drive can persist the ephemeral data in storage tiers which are closer to the application that allow lower read latencies and better economies for read request, since cloud storage reads incur an egress cost.
Last week we learned about the [increased tail-latency sensitivity of microservices based applications with high RPC fan-outs. Seer uses estimates of queue depths to mitigate latency spikes on the order of 10-100ms, in conjunction with a cluster manager. So what we have here is a glimpse of the limits for low-latency RPCs under load.
The availability of large scale voice training data, the advances made in software with processing engines such as Caffe, MXNet and Tensorflow, and the rise of massively parallel compute engines with low-latency memory access, such as the Amazon EC2 P3 instances have made voice processing at scale a reality.
They can also bolster uptime and limit latency issues or potential downtimes. Adopting open-source standards and tools like Kubernetes lays the groundwork for creating adaptable and transportable solutions that promote application deployment and management in various cloud environments.
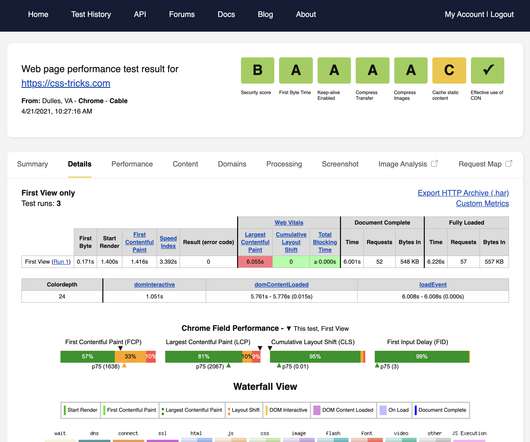
As an online booking platform, we connect travelers with transport providers worldwide, offering bus, ferry, train, and car transfers in over 30 countries. We aim to eliminate the complexity and hassle associated with travel planning by providing a one-stop solution for all transportation needs. Time to First Byte over time.
This will typically include environment variables that can influence the behavior of the MPI runtime, and might include environment variables that can influence the behavior of the lower-level shared-memory transport and/or network hardware interfaces. The processor hardware available to support shared-memory transport.
This will typically include environment variables that can influence the behavior of the MPI runtime, and might include environment variables that can influence the behavior of the lower-level shared-memory transport and/or network hardware interfaces. The processor hardware available to support shared-memory transport.
One of the slides I omitted to shorten this version of the talk highlighted that there are actually two issues when you go from “Disjoint (tightly coupled)” to “Disjoint (loosely coupled)”: reliability and latency , and both are important. (I I also mentioned this in the original WttJ article this is based on; just search for “reliability.”).
Contended, over-subscribed cells can make “fast” networks brutally slow, transport variance can make TCP much less efficient , and the bursty nature of web traffic works against us. It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss).
Finally, not inlining resources has an added latency cost because the file needs to be requested. First, in part 1 , we discussed that HTTP/3 was needed mainly because of the new underlying QUIC transport protocol. In our own early tests , I found seriously diminishing returns at about 40 files.
This difference has substantial technological implications, from the classification of what’s interesting to transport to cost-effective storage (keep an eye out for later Netflix Tech Blog posts addressing these topics). Distributed tracing is the process of generating, transporting, storing, and retrieving traces in a distributed system.
Because we are dealing with network protocols here, we will mainly look at network aspects, of which two are most important: latency and bandwidth. Latency can be roughly defined as the time it takes to send a packet from point A (say, the client) to point B (the server). Two-way latency is often called round-trip time (RTT).
Since it is potentially unbounded, we can’t wait—buffer elements—until we have received all data before we act upon it, but need to do so in an incremental fashion—ideally without overwhelming ourselves, or overwhelming those who consume the data we produce or incur a too-high processing latency. enum Transport {. Bootstrap the system.
More than 20% of the goods will be made, packaged, transported, delivered without any external touch or effect. By 2024, Based on hyperautomation technology and modern operating procedures, companies can lower operating costs by 30 per cent. By 2025, the person who orders the product will first be the person who touches it.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Thus, it "hides" latency (both in the network and on the server) from clients. Result: zero RTT for repeat views. Testing And Monitoring. Have you optimized your auditing workflow?
Also hear from AWS customer Cargill, who shares their data journey and how they built Jarvis, which helps optimization of carbon emissions associated with ocean transportation and uses gen AI to enable faster decision-making.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content