This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This nuanced integration of data and technology empowers us to offer bespoke content recommendations. This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability.
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency. Apache Kafka, designed for distributed event streaming, maintains low latency at scale.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. Logging is selective to cases where the old and new responses do not match.
To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render. In Summary Technology is constantly changing, and we, as engineers, spend a large part of our careers performing migrations. We then collect and analyze the performance of the two clusters.
Storage mount points in a system might be larger or smaller, local or remote, with high or low latency, and various speeds. For example: All subfolders of the /opt directory are mounted as local, low latency, high-throughput drives, with relatively low storage capacity. Stay tuned for upcoming news about these changes.
Traces are used for performance analysis, latency optimization, and root cause analysis. It evolves continuously through contributions from a vibrant community and support from major tech companies, which ensures that it stays aligned with the latest industry standards, technological advancements, and best practices.
As organizations continue to modernize their technology stacks, many turn to Kubernetes , an open source container orchestration system for automating software deployment, scaling, and management. You can ask for the best configuration to reduce latency or improve the user experience.” It’s not just a cost-reduction tool.
The phrase “serverless computing” appears contradictory at first, but for years now, successful companies have understood the benefit of using serverless technologies to streamline operations and reduce costs. When an application is triggered, it can cause latency as the application starts. Dynatrace news.
As companies accelerate digital transformation, they implement modern cloud technologies like serverless functions. According to Flexera , serverless functions are the number one technology evaluated by enterprises and one of the top five cloud technologies in use at enterprises. And serverless support is a core capability.
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The data warehouse is not designed to serve point requests from microservices with low latency.
By Xiaomei Liu , Rosanna Lee , Cyril Concolato Introduction Behind the scenes of the beloved Netflix streaming service and content, there are many technology innovations in media processing. Our previous tech blog Packaging award-winning shows with award-winning technology detailed our packaging technology deployed on the streaming side.
For example, improving latency by as little as 0.1 latency is the number one reason consumers abandon mobile sites. Fine-tuning the service-level indicators that make up quality gates will improve with the help of upcoming features. For global technology platform provider Intuit, any failure impacts customers in a profound way.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The subsystems all communicate with each other asynchronously via Timestone, a high-scale, low-latency priority queuing system. Warm capacity.
Digital experience monitoring is the practice of using tools and technologies to gather and evaluate metrics as a customer navigates an application to determine the quality of a user’s interaction with its digital touchpoints. What is digital experience monitoring? How digital experience monitoring changes the game.
However, modern web applications are rarely monolithic, and often use multiple languages and technologies. While there is plenty of well-documented benefits to using a connection pooler, there are some arguments to be made against using one: Introducing a middleware in the communication inevitably introduces some latency.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
In this blog post, we describe how we improved the methodology, which technologies we leveraged, and how this has improved service deployment and consistency. The canary stage will determine a score based on metrics such as CPU, threads, latency, and GC pauses.
Efficient environment configuration at scale One of software engineers’ most significant challenges is managing the numerous tools and technologies required for the software product lifecycle. Stay tuned for more examples and easy-to-adopt automations provided in our public Github project.
In addition, compute and storage are increasingly being separated causing larger latencies for queries. But to get the best performance, like any technology stack, you need to follow the best practices. Alluxio is leveraged as compute-side virtual storage to improve performance.
This separation allows us to tune system configuration and scaling policies independently for different event priorities and traffic patterns. The core to bringing these engineering solutions to life is our direct collaboration with our colleagues and using the most impactful tools and technologies available.
For that, we focused on OpenTelemetry as the underlying technology and showed how you can use the available SDKs and libraries to instrument applications across different languages and platforms. Apache and MySQL are among the technologies supported by OneAgent. Yet, we have two entries for these two services in our list.
Operational Reporting is a reporting paradigm specialized in covering high-resolution, low-latency data sets, serving detailed day-to-day activities¹ and processes of a business domain. Most of the business views created on top of the Iceberg tables can tolerate a few minutes of latency. Please stay tuned! tactical) in nature.
These two technologies, alongside a host of other resiliency and chaos tools, made a massive difference: our reliability improved measurably as a result. There is a downside to fetching this data on-demand: this adds latency to the first request to a cluster. It’s been a great experience working with you all on this.
Such coupling problems abound with our Reloaded architecture, and hence the Media Cloud Engineering and Encoding Technologies teams have been working together to develop a solution that addresses many of the concerns with our previous architecture. This enables us to use our scale to increase throughput and reduce latencies.
With Tel Aviv being the technology capital of Israel, it's the ideal edge server location. The image below shows a significant drop in latency once we've launched the new point of presence in Israel. In fact, latency has been reduced by almost 50%! Performance report Brisbane - Australia Brisbane is our 4th POP in Australia.
In addition to availability, our respondents focus most heavily on supporting the following data attributes: “accessibility, accuracy, authoritativeness, freshness, latency, structuredness, ontological typing, connectedness, and semantic joinability.” To address this, rigorous rollout processes are required.
Though the AWS Cloud gives you access to the storage and processing power required for ML, the process for building, training, and deploying ML models has unique challenges that often block successful use of this powerful new technology. The challenges begin with collecting, cleaning, and formatting training data.
The Dynamo paper was well-received and served as a catalyst to create the category of distributed database technologies commonly known today as "NoSQL." " Of course, no technology change happens in isolation, and at the same time NoSQL was evolving, so was cloud computing.
At Amazon we have hundreds of teams using machine learning and by making use of the Machine Learning Service we can significantly speed up the time they use to bring their technologies into production. One of the most exciting technologies we have built lately at AWS is Amazon Lambda. Amazon Lambda.
For streaming technology, Netflix utilizes a variety of options such as Kafka, SQS, Kinesis, and even Netflix specific streaming solutions such as Keystone. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low.
For streaming technology, Netflix utilizes a variety of options such as Kafka, SQS, Kinesis, and even Netflix specific streaming solutions such as Keystone. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low.
Screenshot: tracing read latency for PID 181: # bpftrace -e 'kprobe:vfs_read /pid == 30153/ { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns = hist(nsecs - @start[tid]); delete(@start[tid]); }'. Back then I could already tell if disks were seeking by interpreting iostat(1) output: seeing high disk latency but small I/O.
This boils down to a single digit µs latency toleration in the tail for far memory, and in addition to security and privacy concerns, rules out remote memory solutions. Thus we’re fundamentally trading (de)-compression latency at access time for the ability to pack more data in memory. ML-based auto-tuning. Evaluation.
Stay tuned for more details on this, as well as more details on the internals of the new SKU Platform in one of our upcoming blog posts. Lower latency as a result of fewer service calls, which means fewer errors for our visitors. The next step is to invest further into self-service and support rule changes via a SKU UI.
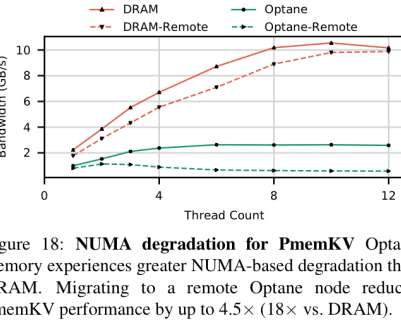
higher latency and lower bandwidth)… We have found the actual behavior of Optane DIMMs to be more complicated and nuanced than the "slower, persistent DRAM" label would suggest. The read latency for Optane is 2x-3x higher than DRAM. Optane DIMMs are here! Optane memory is also more pattern-dependent than DRAM.
photo by Adrian I gave a talk at Monitorama in Portland Oregon in June, which set out the idea that carbon is just another metric to monitor, and that in a few years most of the monitoring and performance tuning tools are going to be reporting and optimizing for carbon alongside latency, throughput, availability and cost.
To remain competitive in a market that demands real-time responses to these digital pulses, organizations are adopting fast data applications as key assets in their technology portfolio. The data shape will dictate capacity planning, tuning of the backbone, and scalability analysis for individual components. At least once?
During this time we did do plenty of hard work, rolling out new technologies and major microservice versions, and fixed many problems big and small. The proactive projects usually take weeks or months, and are where I'm developing a new technology or helping other teams with performance analysis or evaluations.
Here are 8 fallacies of data pipeline The pipeline is reliable Topology is stateless Pipeline is infinitely scalable Processing latency is minimum Everything is observable There is no domino effect Pipeline is cost-effective Data is homogeneous The pipeline is reliable The inconvenient truth is that pipeline is not reliable.
There is a lot of awesome technology involved with Hyperscale in how it is architected to use SSD-based caches and page servers. This works well for many SQL Server workloads, however, there have been use cases for a lower CPU latency and higher clock speed for CPU-heavy workloads and a need for higher memory per vCore.
And yet, more often than not, OEMs don’t consider their underlying tech stack technologies until they are way too deep into said crisis. This, in turn, sometimes led to local DBAs making problems worse, or sometimes conjuring problems out of thin air by (ab)using their mandate to ‘tune’ the system. Another issue is geo-distribution.
Here's some output from my zfsdist tool, in bcc/BPF, which measures ZFS latency as a histogram on Linux: # zfsdist. Tracing ZFS operation latency. Both Xen and KVM have had many performance and security improvements, and workloads can now be tuned to run at almost bare metal speeds (say, a 3% loss or less). Hit Ctrl-C to end. ^C
Now, if a user wants to book a ride, the Load Balancer routes that specific request to the “ordering†microservice.This modular approach offers advantages like scalability, resilience, faster deployments, flexibility in and technology choices.â€At The Load Balancer all wonderfully plays it out!
Whether you’re running an e-commerce site or a streaming platform, your end goal is to provide an experience so smooth that your users forget they’re interacting with technology. Latency is a concept that increases with distance, so a signal that has to travel 1,000 KM will be much faster compared to a signal sprinting for that 100,000 KM.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content