This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. With Dynatrace, teams can seamlessly monitor the entire system, including network switches, database storage, and third-party dependencies.
Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. It enables multiple operating systems to run simultaneously on the same physical hardware and integrates closely with Windows-hosted services. This leads to a more efficient and streamlined experience for users.
Therefore, it requires multidimensional and multidisciplinary monitoring: Infrastructure health —automatically monitor the compute, storage, and network resources available to the Citrix system to ensure a stable platform. Citrix platform performance—optimize your Citrix landscape with insights into user load and screen latency per server.
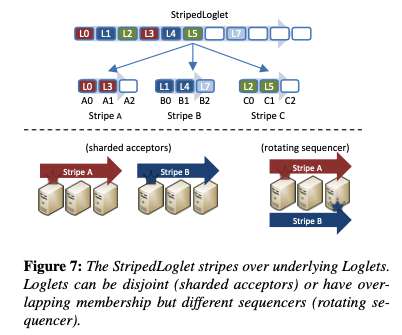
Virtual consensus in Delos , Balakrishnan et al. While ultimately this new system should be able to take advantage of the latest advances in consensus for improved performance, that’s not realistic given a 6-9 month in-production target. We propose the novel abstraction of a virtual shared log (or VirtualLog).
Lastly, the packager kicks in, adding a system layer to the asset, making it ready to be consumed by the clients. Uploading and downloading data always come with a penalty, namely latency. Virtual Assembly Figure 3 describes how a virtual assembly of the encoded chunks replaces the physical assembly used in our previous architecture.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines.
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. It aims to provide a reliable platform for users to participate in live or pre-recorded workout sessions, virtual training, or fitness tutorials without interruptions. Latency primarily focuses on the time spent in transit.
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for monitoring cloud platforms and virtual infrastructure, along with log monitoring and AIOps. High latency or lack of responses. This increase is clearly correlated with the increased response latencies.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
Performance monitoring Dynatrace can collect performance metrics from Nutanix clusters, including latency, IOPS (Input/Output Operations Per Second), and network throughput. Virtual machine metrics Gain insights into the performance of your virtual machines, ensuring that your applications run smoothly.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
The first was voice control, where you can play a title or search using your virtual assistant with a voice command like “Show me Stranger Things on Netflix.” (See Sample system diagram for an Alexa voice command. The other main use case was RENO, the Rapid Event Notification System mentioned above.
A vast majority of the features are the same, outside of these advanced features available through the BYOC model: Virtual Private Clouds / Virtual Networks. Amazon Virtual Private Clouds (VPC) and Azure Virtual Networks (VNET) are private, isolated sections of the cloud infrastructure where you can launch resources.
Therefore, it requires multidimensional and multidisciplinary monitoring: Infrastructure health —automatically monitor the compute, storage, and network resources available to the Citrix system to ensure a stable platform. Citrix platform performance—optimize your Citrix landscape with insights into user load and screen latency per server.
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. It aims to provide a reliable platform for users to participate in live or pre-recorded workout sessions, virtual training, or fitness tutorials without interruptions. Latency primarily focuses on the time spent in transit.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
On modern Linux systems, the difference in overhead between forking a process and creating a thread is much lesser than it used to be. These sit between the database and the clients, sometimes on a seperate server (physical or virtual) and sometimes on the same box, and create a pool that clients can connect to.
Virtually any application with a user interface can benefit from regular real user monitoring. Analyzing a clinician’s clickstream when using an electronic medical record system to better improve the efficiency of data entry. Providing insight into the service latency to help developers identify poorly performing code.
What Dynatrace deployment is the best fit for your technology stack, and is the OneAgent compatible with your system? Virtualization can be a key player in your process’ performance, and Dynatrace has built-in integrations to bring metrics about the Cloud Infrastructure into your Dynatrace environment. OneAgent & cloud metrics.
Amazon Elastic File System (EFS). The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Follow these steps to configure monitoring for supporting AWS services: From the navigation menu, select Settings > Cloud and virtualization > AWS. Amazon Aurora. Amazon API Gateway.
STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables). PC, smartphone, server) or virtual (virtual machines, cloud gateways). Endpoints can be physical (i.e.,
It keeps application processing closer to the data to maintain higher bandwidth and lower latencies, adheres to compliance regulations that don’t yet approve cloud managed services, and allows data center capital investments to be fully amortized before moving to the cloud. AWS System Manager. Getting started.
Amazon Elastic File System (EFS). The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Follow these steps to configure monitoring for supporting AWS services: From the navigation menu, select Settings > Cloud and virtualization > AWS. Amazon Aurora. Amazon API Gateway.
Werner Vogels weblog on building scalable and robust distributed systems. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system. Amazon DynamoDB offers low, predictable latencies at any scale. All Things Distributed.
To improve availability, we designed systems where components could fail separately and avoid single points of failure. The abstractions that Eureka provides for this are Virtual IPs (VIPs) for insecure communication, and Secure VIPs (SVIPs) for secure. Afterward, Envoy behaves as if the cluster was defined in the config.
Web developers or administrators did not have to worry or even consider the complexity of distributed systems of today. Great, your system was ready to be deployed. Once the system was deployed, to ensure everything was running smoothly, it only took a couple of simple checks to verify. What is a Distributed System?
Balancing Low Latency, High Availability and Cloud Choice Cloud hosting is no longer just an option — it’s now, in many cases, the default choice. Low usage or over-engineered legacy systems Until the arrival of cloud hosting, nobody knew how to size anything properly, or they did know but never got a chance to. Why are they refusing?
Build evolvable systems. But we couldn’t adopt the old style approach of upgrading systems through a maintenance outage, as many businesses around the world are relying on our platform for 24/7 availability. We needed to build systems that embrace failure as a natural occurrence even if we did not know what the failure might be.
I also wrote about these topics in detail for my recent [Systems Performance 2nd Edition] book. TCP Extensions for Multipath Operation with Multiple Addresses,” [link] Mar 2020 - [Gregg 20] Brendan Gregg, “Systems Performance: Enterprise and the Cloud, Second Edition,” Addison-Wesley, 2020 - [Hruska 20] Joel Hruska, “Intel Demos PCIe 5.0
Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. Remember: This is a critical aspect as you do not want to migrate a service and suddenly introduce high latency or costs to a system that you forgot about having a dependency with!
Netflix Drive relies on a data store that will be the persistent storage layer for assets, and a metadata store which will provide a relevant mapping from the file system hierarchy to the data store entities. 2 , are the file system interface, the API interface, and the metadata and data stores. The major pieces, as shown in Fig.
Relationships are a fundamental aspect of both the physical and virtual worlds. Modern applications need to quickly navigate connections in the physical world of people, cities, and public transit stations as well as the virtual world of search terms, social posts, and genetic code, for example. The importance of relationships.
This talk originated from my updates to [Systems Performance 2nd Edition], and this was the first time I've given this talk in person! CXL in a way allows a custom memory controller to be added to a system, to increase memory capacity, bandwidth, and overall performance. Ford, et al., “TCP
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. CLI tools The Cassandra systems were EC2 virtual machine (Xen) instances. Note that Ubuntu also has a frame to show entry into vDSO (virtual dynamic shared object). Microbenchmark os::javaTimeMillis() on both systems.
In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. However, due to its reliance on the virtual memory subsystem, it is not suitable for larger datasets. However, keep in ming that it does not release space to the operating system.
Simply put, it’s the set of computational tasks that cloud systems perform, such as hosting databases, enabling collaboration tools, or running compute-intensive algorithms. Such demanding use cases place a great value on systems capable of fast and reliable execution, a need that spans across various industry segments.
In what seems almost a previous life by now Thorsten was one of the top young professors in Distributed Systems and I had the great pleasure of working with him at Cornell in the early 90''s. What set Thorsten aside from so many other system research academics was his desire to build practical, working systems, a path that I followed as well.
Werner Vogels weblog on building scalable and robust distributed systems. The Amazon Virtual Private Cloud extends on-premises compute with all the power of AWS, making it elastic, scalable and highly reliable. All Things Distributed. Expanding the Cloud - The AWS Storage Gateway. By Werner Vogels on 23 January 2012 12:01 AM.
On April 24, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations. Were experiencing high latency in responses.
Understanding Hybrid Cloud Strategy A hybrid cloud merges the capabilities of public and private clouds into a singular, coherent system. On-Premises Data Center A hybrid cloud architecture necessitates that an organization retains full authority over its physical or virtual infrastructure within the private cloud segment.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. The key specifications for the Lsv2 series virtual machines are shown in Table 1. They feature low latency, local NVMe storage that can directly leverage the 128 PCIe 3.0
Artificial intelligence can automate tasks ranging from: data analysis resource provisioning system maintenance decision-making natural language processing This not only improves accuracy and reliability but also frees up valuable time for IT teams to focus on strategic tasks, such as resource management on platforms like Google Cloud.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content