This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
Dynatrace is naturally suited to address these requirements with its automatic and AI-powered full-stack software intelligence platform. Dynatrace software intelligence helps you manage Citrix environments and real user experience more effectively. Tie latency issues to host and virtualization infrastructure network quality.
Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking. What is Microsoft Hyper-V? What’s next?
In today’s fast-paced digital landscape, ensuring high-quality software is crucial for organizations to thrive. Service level objectives (SLOs) provide a powerful framework for measuring and maintaining software performance, reliability, and user satisfaction. Note : you might hear the term latency used instead of response time.
In response to this trend, open source communities birthed new companies like WSO2 (of course, industry giants like Google, IBM, Software AG, and Tibco are also competing for a piece of the API management cake). High latency or lack of responses. This increase is clearly correlated with the increased response latencies.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.”
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. In this blog post, we delve into these challenges and explore how Dynatrace can address them to enhance the reliability of released software.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.”
Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes. Customers can use response streaming to achieve the following: Improve Time to First Byte (TTFB) performance for latency-sensitive applications. Return larger payload sizes.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
Dynatrace is naturally suited to address these requirements with its automatic and AI-powered full-stack software intelligence platform. Dynatrace software intelligence helps you manage Citrix environments and real user experience more effectively. Tie latency issues to host and virtualization infrastructure network quality.
In today’s fast-paced digital landscape, ensuring high-quality software is crucial for organizations to thrive. Service level objectives (SLOs) provide a powerful framework for measuring and maintaining software performance, reliability, and user satisfaction. Note : you might hear the term latency used instead of response time.
STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables). PC, smartphone, server) or virtual (virtual machines, cloud gateways). Real-user monitoring (RUM).
Amazon DynamoDB offers low, predictable latencies at any scale. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer. s read latency, particularly as dataset sizes grow.
The abstractions that Eureka provides for this are Virtual IPs (VIPs) for insecure communication, and Secure VIPs (SVIPs) for secure. Second, we’ve moved from a Java-only environment to a Polyglot one: we now also support node.js , Python , and a variety of OSS and off the shelf software.
Almost from day one, we knew that the software we were building would not be the software that would be running a year later. We needed to build such an architecture that we could introduce new software components without taking the service down. Build evolvable systems. Automation is key. No gatekeepers.
With Dynatrace, we follow a combination of agent and agent-less approach where the “secret sauce” lies in our Dynatrace OneAgent (watch my Performance Clinic YouTube tutorial with our Chief Software Architect Helmut Spiegl ). While this is a good start it only provides actionable data for the very classical lift & shift migration.
The Amazon Virtual Private Cloud extends on-premises compute with all the power of AWS, making it elastic, scalable and highly reliable. The AWS Storage Gateway is a service connecting an on-premises software appliance with cloud-based storage. s storage infrastructure. Once the AWS Storage Gatewayâ??s
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. CLI tools The Cassandra systems were EC2 virtual machine (Xen) instances. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Powering the virtual instances and other resources that make up the AWS Cloud are real physical data centers with AWS servers in them. Zones impact how we build, deploy, and operate software, as well as how we enforce security controls between our largest systems. One is that the latency within a zone is incredibly fast.
On April 24, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations. Were experiencing high latency in responses.
Various forms can take shape when discussing workloads within the realm of cloud computing environments – examples include order management databases, collaboration tools, videoconferencing systems, virtual desktops, and disaster recovery mechanisms. This applies to both virtual machines and container-based deployments.
This meeting was hosted by the University of Applied Sciences of Upper Austria , RISC Software GmbH , Softwarepark Hagenberg Upper Austria , Dynatrace , and Count It Group. Note: For definitions of language safety and software security and similar terms, see my 2024 essay C++ safety, in context.
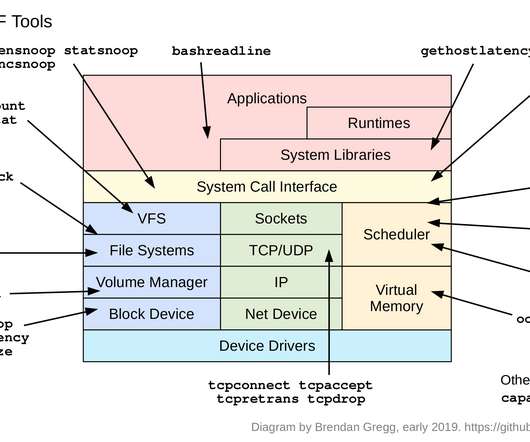
more capable, and built from the ground up for the modern era of the eBPF virtual machine. eBPF was created by Alexei Starovoitov while at PLUMgrid (he's now at Facebook) as a generic in-kernel virtual machine, with software defined networks as the primary use case. It's shaping up to be a DTrace version 2.0: eBPF does more.
I generated this using my offcputime tool from [bcc] (this tool needs eBPF features from Linux 4.8+), and my [flame graph] software: #./bcc/tools/offcputime.py rc5-virtual (bgregg-xenial-bpf-i-0b7296777a2585be1) 08/01/2017 _x86_64_ (8 CPU) 10:15:51 PM UID PID %usr %system %guest %CPU CPU Command 10:16:51 PM 0 18468 2.85 termc$ uptime.
VPC Endpoints give you the ability to control whether network traffic between your application and DynamoDB traverses the public Internet or stays within your virtual private cloud. Performant – DynamoDB consistently delivers single-digit millisecond latencies even as your traffic volume increases.
cpupower frequency-info analyzing CPU 0: driver: intel_pstate CPUs which run at the same hardware frequency: 0 CPUs which need to have their frequency coordinated by software: 0 maximum transition latency: Cannot determine or is not supported. hardware limits: 1000 MHz - 4.00 bin/pgbench -c 1 -S -T 60 pgbench starting vacuum.end.
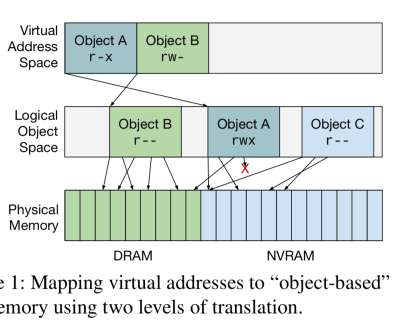
This is a companion paper to the " persistent problem " piece that we looked at earlier this week, going a little deeper into the object pointer representation choices and the mapping of a virtual object space into physical address spaces. " Epheremal virtual addresses don’t cut it as the basis for persistent pointers.
Hosted on a cluster of physical or virtual servers, it maintains memory-based state information about the history and dynamically evolving state of every data source. The post The Need for Real-Time Device Tracking appeared first on ScaleOut Software.
bpftrace is a new open source tracer for Linux for analyzing production performance problems and troubleshooting software. For example, iostat(1), or a monitoring agent, may tell you your average disk latency, but not the distribution of this latency. software Kernel software-based events.
It was – like the hypothetical movie I describe above – more than a little bit odd, as you could leave a session discussing ever more abstract layers of virtualization and walk into one where they emphasized the critical importance of pinning a network interface to a specific VM for optimal performance.
In both cases, when using virtually-synchronous replication, the process will require certification from each node and local (by node) write; as such, the number of writes is NOT distributed across multiple nodes but duplicated. Because the solutions still rely on writing in one single node that works as Primary. Why ProxySQL?
These systems can include physical servers, containers, virtual machines, or even a device, or node, that connects and communicates with the network. A three-tier system is a software application architecture that consists of a presentation layer, application layer, and data, or core, layer. Blockchain is a good example of this.
Speedier access to stored information within distributed storage is achieved by leveraging software-defined storage solutions and strategies like sharding or distributing sections of large databases and improving scalability by dividing tasks among many servers.
Continuous Testing is the process of testing at all stages of software development – one after the another- without any human intervention. Continuous Testing makes it possible to eliminate testing as a bottleneck for faster software development and delivery. Continuous Testing is key to faster delivery of Agile products to the market.
Data Pipeline A data pipeline is a software that ingests data from multiple sources, transforms it and finally makes it available to internal or external products. A data pipeline is a software which runs on hardware. The software is error-prone and hardware failures are inevitable.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
To move as fast as they can at scale while protecting mission-critical data, more and more organizations are investing in private 5G networks, also known as private cellular networks or just “private 5G” (not to be confused with virtual private networks, which are something totally different). billion in 2022. billion, growing 48.2%
using Compute Express Link or CXL), organizing memory components for optimal performance, adapting system software traditionally designed for homogeneous memory systems, and developing memory abstractions and programming constructs for HCM management. Figure 2: Latency characteristics of memory technologies (source: Maruf et al.,
You cannot virtualize everything…yet. Software services still require physical devices and hardware for them to function. Knowing when and where an error, downtime, or application latency occurs is a critical factor in limiting the impact to users and customers. Asset Management.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content