This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
These events are promptly relayed from the client side to our servers, entering a centralized event processing queue. Automating Performance Tuning with Autoscalers Tuning the performance of our Apache Flink jobs is currently a manual process. This queue ensures we are consistently capturing raw events from our global userbase.
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Kafka clusters can be deployed in Kubernetes using Helm charts to simplify scaling and management across multiple servers.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. We will examine these alternatives in the upcoming sections.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
Before GraphQL: Monolithic Falcor API implemented and maintained by the API Team Before moving to GraphQL, our API layer consisted of a monolithic server built with Falcor. A single API team maintained both the Java implementation of the Falcor framework and the API Server. To launch Phase 1 safely, we used AB Testing.
95th Percentile Latency. The 95th percentile latency of queries was also 1.8 times higher when the index creation happened on the master server. The 95th percentile latency of queries was also 1.8 times higher when the index creation happened on the master server. Workload Throughput (Queries Per Second).
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Reduced tail latencies In both our GRPC and DGS Framework services, GC pauses are a significant source of tail latencies. That’s particularly true of our GRPC clients and servers, where request cancellations due to timeouts interact with reliability features such as retries, hedging and fallbacks.
By Karthik Yagna , Baskar Odayarkoil , and Alex Ellis Pushy is Netflix’s WebSocket server that maintains persistent WebSocket connections with devices running the Netflix application. In our case, we value low latency — the faster we can read from KeyValue, the faster these messages can get delivered.
In this case, the four golden signals (latency, traffic, errors, and saturation) are derived from span attributes and DQL metric queries via Dynatrace Grail™. Based on those insights, they implemented automated validation tasks, and shifted left in their software delivery pipeline.
Using a connection pool in each module is hardly efficient: Even with a relatively small number of modules, and a small pool size in each, you end up with a lot of server processes. You either need an extra server (or 3), or your database server(s) must have enough resources to support a connection pooler, in addition to PostgreSQL.
Many database administrators find themselves having to support instances of SQL Server Reporting Services (SSRS), or at least the backend databases that are required for SSRS. This article will cover many areas that database administrators need to be aware of in order to properly license, recover, and tune a Reporting Services installation.
However, serverless applications have unique characteristics that make observability more difficult than in traditional server-based applications. Serverless applications have several benefits over server-based applications: Eliminate the need to provision, manage and maintain servers or containers.
Within this paradigm, it is possible to run entire architectures without touching a traditional virtual server, either locally or in the cloud. When an application is triggered, it can cause latency as the application starts. Unlike on-premises machines, shared servers, or rented virtual machines, there is no cost for downtime.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The subsystems all communicate with each other asynchronously via Timestone, a high-scale, low-latency priority queuing system. Warm capacity.
The canary stage will determine a score based on metrics such as CPU, threads, latency, and GC pauses. Running a canary for each change and testing the AMI in production allows us to capture insights around impact on Windows updates, script changes, tuning web server configuration, among others.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. This separation allows us to tune system configuration and scaling policies independently for different event priorities and traffic patterns.
If we were to select the most important MySQL setting, if we were given a freshly installed MySQL or Percona Server for MySQL and could only tune a single MySQL variable, which one would it be? Sysbench ran on a third server, which I’ll refer to as the application server (APP).
Think about items such as general system metrics (for example, CPU utilization, free memory, number of services), the connectivity status, details of our web server, or even more granular in-application tasks like database queries. Let’s click “Apache Web Server apache” now.
STM generates traffic that replicates the typical path or behavior of a user on a network to measure performance for example, response times, availability, packet loss, latency, jitter, and other variables). PC, smartphone, server) or virtual (virtual machines, cloud gateways). Endpoints can be physical (i.e.,
Discord optimized its platform to serve over one million online users in a single server while maintaining a responsive user experience. By Rafal Gancarz
It enables them to adapt to user feedback swiftly, fine-tune feature releases, and deliver exceptional user experiences, all while maintaining control and minimizing disruption. Using advanced causal AI and context-aware decision-making, it identifies the root cause behind server failures.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Understanding Redis Performance Indicators Redis is designed to handle high traffic and low latency with its in-memory data store and efficient data structures.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. They enable us to further fine-tune and configure the system, ensuring the new changes are integrated smoothly and seamlessly.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Some servers may need a few GBs of RAM, while others may need hundreds of GBs or even terabytes of RAM. If you see concurrency issues, you can tune this variable.
In PostgreSQL, replication lag can occur due to various reasons such as network latency, slow disk I/O, long-running transactions, etc. Replication lag can occur due to various reasons, such as: Network latency: Network latency is the delay caused by the time it takes for data to travel between the primary and standby databases.
IPC clients are instantiated targeting that VIP or SVIP, and the Eureka client code handles the translation of that VIP to a set of IP and port pairs by fetching them from the Eureka server. There is a downside to fetching this data on-demand: this adds latency to the first request to a cluster.
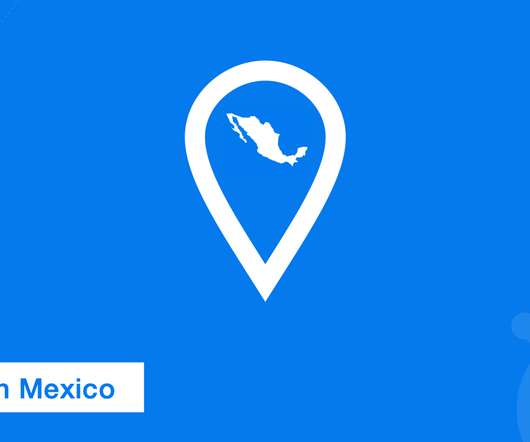
The POP is strategially located within the country and lowers latency overall. KeyCDN is always on the lookout for ways to minimize latency and accelerate asset delivery worldwide. For more POPs planned, check our current network for a list of both active and planned edge server locations. Hola Mexico!
With Tel Aviv being the technology capital of Israel, it's the ideal edge server location. The image below shows a significant drop in latency once we've launched the new point of presence in Israel. In fact, latency has been reduced by almost 50%! Performance report Brisbane - Australia Brisbane is our 4th POP in Australia.
As developers, we rightfully obsess about the customer experience, relentlessly working to squeeze every millisecond out of the critical rendering path, optimize input latency, and eliminate jank. Hydrogen fuels dynamic commerce by uniting React Server Components, streaming server-side rendering, and smart caching controls.
I’ll show you some MySQL settings to tune to get better performance, and cost savings, with AWS RDS. After some time of receiving these messages, eventually, they hit performance issues to the point that the server becomes unresponsive for a few minutes. This was exactly what was happening on this server.
PostgreSQL Cluster One coordinator node citus-coord-01 Three worker nodes citus1 citus2 citus3 Hardware AWS Instance Ubuntu Server 20.04, SSD volume type 64-bit (x86) c5.xlarge Steps Provisioning The first step is to provision the four nodes with both PostgreSQL and Citus. psql pgbench <<_eof1_ qecho adding node citus3.
The software also extends capabilities allowing fine-tuning consumption parameters through QoS (Quality of Service) prefetch limits catered toward balancing load among numerous consumers, thus preventing overwhelming any single consumer entity. RabbitMQ ensures that this data exchange is smooth and uninterrupted across different platforms.
While there is no magic bullet for MySQL performance tuning, there are a few areas that can be focused on upfront that can dramatically improve the performance of your MySQL installation. What are the Benefits of MySQL Performance Tuning? A finely tuned database processes queries more efficiently, leading to swifter results.
device characteristics come from our on-field knowledge and runtime memory data comes from real-time user data pushed to our servers. Stay tuned for further posts on memory management and the use of ML modeling to deal with systemic and low latency data collected at the device level.
percent availability in the event of a server, a rack of servers, or an Availability Zone failure. DynamoDB automatically re-distributes your data to healthy servers to ensure there are always multiple replicas of your data without you needing to intervene.
Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. Stay Tuned DBLog has additional capabilities which are not covered by this blog post, such as: Ability to capture table schemas without using locks.
Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. Stay Tuned DBLog has additional capabilities which are not covered by this blog post, such as: Ability to capture table schemas without using locks.
The action corresponds to the button on the page and the withFields specify which fields the server expects to have sent back when the button is clicked. Stay tuned for more details on this, as well as more details on the internals of the new SKU Platform in one of our upcoming blog posts. Step 3 & 4?—?Determine
With a dedicated POP, latency for visitors is reduced even further, resulting in better loading times. This makes Dublin the ideal location for an edge server. How to check a POP location Each edge server adds the HTTP response header X-Edge-Location delivered by KeyCDN. Lima - Peru Lima is our 6th POP in Latin America.
You’ve probably heard things like: “HTTP/3 is much faster than HTTP/2 when there is packet loss”, or “HTTP/3 connections have less latency and take less time to set up”, and probably “HTTP/3 can send data more quickly and can send more resources in parallel”. Websites would magically become 50% faster with the flip of a switch!
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. This server is spending about a third of its CPU cycles just checking the time! I've shared many posts about superpower observability tools, but often humble hacking is just as effective. 30.14% in the middle of the flame graph.
Next, we’ll look at how to set up servers and clients (that’s the hard part unless you’re using a content delivery network (CDN)). This difference by itself doesn’t do all that much (it mainly reduces the overhead on the server-side), but it leads to most of the following points. Server Sharding and Connection Coalescing.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content