This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. It facilitates the distribution of these learnings to other models, either through shared model weights for fine tuning or directly through embeddings.
This decoupling simplifies system architecture and supports scalability in distributed environments. Kafka stores and distributes data through a partitioned log system, which spans multiple brokers to provide fault tolerance and scalability. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? The complexity of these operational demands underscored the urgent need for a scalable solution.
Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively.
Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. Keeping queues short maintains a responsive and efficient RabbitMQ setup.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. Logging is selective to cases where the old and new responses do not match.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The third generation, called Reloaded , has been online for about seven years and has proven to be stable and massively scalable.
The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. Figure 1 shows how we use Bulldozer to move data at Netflix. Moving data with Bulldozer at Netflix.
Allegro experimented with different performance optimization options to improve Apache Kafka producer tail latency and eventually switched all its clusters to the XFS filesystem. The company used Kafka protocol sniffing, JVM profiling, and eBPF, which proved instrumental in identifying and eliminating performance bottlenecks.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
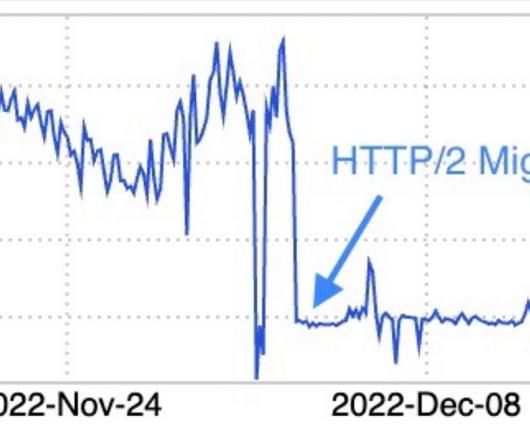
LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. By Rafal Gancarz
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. This separation allows us to tune system configuration and scaling policies independently for different event priorities and traffic patterns.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Our engineering teams tuned their services for performance after factoring in increased resource utilization due to tracing.
At ScaleGrid, we’re always pushing the boundaries to offer more flexibility and scalability to our customers. Additionally, we’ve added the Philadelphia AWS Local Zone , helping to reduce latency for customers operating in the eastern U.S. Stay tuned for more exciting updates in the months to come! <p>The </p>
Whether tracking internal, workload-centric indicators such as errors, duration, or saturation or focusing on the golden signals and other user-centric views such as availability, latency, traffic, or engagement, SLOs-as-code enables coherent and consistent monitoring throughout the environment at scale.
Stay tuned for more details on this, as well as more details on the internals of the new SKU Platform in one of our upcoming blog posts. Lower latency as a result of fewer service calls, which means fewer errors for our visitors. The next step is to invest further into self-service and support rule changes via a SKU UI.
You can use these services in combinations that are tailored to help your business move faster, lower IT costs, and support scalability. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Stay tuned for updates in Q1 2020. You can also create custom charts. Requirements.
Additionally, instead of implementing business logic by composing multiple individual Processors together, users could express their logic in a single SQL query, avoiding the additional resource and latency overhead that came from multiple Flink jobs and Kafka topics. This makes the query service lightweight, scalable, and execution agnostic.
You can use these services in combinations that are tailored to help your business move faster, lower IT costs, and support scalability. The example below visualizes average latency by API name and stage for a specific AWS API Gateway. Stay tuned for updates in Q1 2020. You can also create custom charts. Requirements.
These principles reduce resource usage by being more efficient and effective while lowering the end-to-end latency in data processing. Orient: Gather tuning parameters for a particular table that changed. AutoAnalyze In short, AutoAnalyze finds the best tuning/configuration parameters for a table. More processing resources.
We are expected to process 1,000 watermarks for a single distribution in a minute, with non-linear latency growth as the number of watermarks increases. We wanted a scalable service that was near real-time, 2. New feature requests were adding to the maintenance burden for the team.
As VMAF evolves and is integrated with more encoding and streaming workflows within Netflix, we need scalable ways of fostering video quality innovations. The Reloaded system is a well-matured and scalable system, but its monolithic architecture can slow down rapid innovation. VQS is called using the measureQuality endpoint.
The challenge, then, is to be able to ingest and process these events in a scalable manner, i.e., scaling with the number of devices, which will be the focus of this blog post. By the following morning, alerts were received regarding high memory consumption and GC latencies, to the point where the service was unresponsive to HTTP requests.
The results will help database administrators and decision-makers choose the right platform for their performance, scalability, and cost-efficiency needs. Introduction Purpose and Scope Cloud-hosted PostgreSQL solutions are increasingly popular among organizations seeking scalable, high-performance databases. </p>
The other sections on that page (such as Disk analysis) provide further information and charts on topics such as available disk space, latency, dropped network packets, refused connections, and more. This allows us to quickly tell whether the network link may be saturated or the processor is running at its limit.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. It enables them to adapt to user feedback swiftly, fine-tune feature releases, and deliver exceptional user experiences, all while maintaining control and minimizing disruption.
MongoDB is a dynamic database system continually evolving to deliver optimized performance, robust security, and limitless scalability. Sharded time-series collections for improved scalability and performance. Ready to supercharge your MongoDB experience? x: Live resharding of databases for uninterrupted sharded key changes.
Nowadays, solid-state drives (SSDs) or non-volatile memory express (NVMe) drives are preferred over traditional hard disk drives (HDDs) for database servers due to their faster read and write speeds, lower latency, and improved reliability. If you see concurrency issues, you can tune this variable. I hope this helps!
The software also extends capabilities allowing fine-tuning consumption parameters through QoS (Quality of Service) prefetch limits catered toward balancing load among numerous consumers, thus preventing overwhelming any single consumer entity. This scalability is essential for applications that experience fluctuating workloads.
The company evolved the guild component, which is responsible for fanning out billions of message notifications, in a series of performance and scalability improvements supported by system observability and performance tuning. By Rafal Gancarz
As our business scales globally, the demand for data is growing and the needs for scalable low latency incremental processing begin to emerge. Maestro is highly scalable and extensible to support existing and new use cases and offers enhanced usability to end users. This has led to a few internal solutions such as Psyberg.
While there is no magic bullet for MySQL performance tuning, there are a few areas that can be focused on upfront that can dramatically improve the performance of your MySQL installation. What are the Benefits of MySQL Performance Tuning? A finely tuned database processes queries more efficiently, leading to swifter results.
We were pushing the limits of what was a leading commercial database at the time and were unable to sustain the availability, scalability and performance needs that our growing Amazon business demanded. We had an advanced team of database administrators and access to top experts within Oracle. million requests per second.
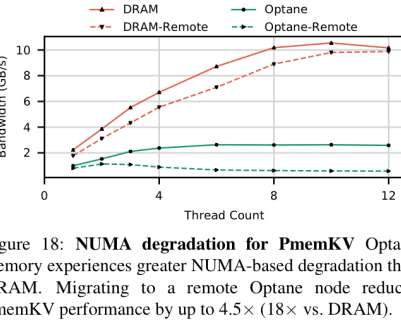
An empirical guide to the behavior and use of scalable persistent memory , Yang et al., higher latency and lower bandwidth)… We have found the actual behavior of Optane DIMMs to be more complicated and nuanced than the "slower, persistent DRAM" label would suggest. The read latency for Optane is 2x-3x higher than DRAM.
We launched DynamoDB last year to address the need for a cloud database that provides seamless scalability, irrespective of whether you are doing ten transactions or ten million transactions, while providing rock solid durability and availability. Going beyond Key-Value.
After this, there is often a long process of training that includes tuning the knobs and levers, called hyperparameters, that control the different aspects of the training algorithm. Finally, figuring out how to move the model into a scalable production environment can often be slow and inefficient for those that do not do it routinely.
The Amazon ML console and API provide data and model visualization tools, as well as wizards to guide you through the process of creating machine learning models, measuring their quality and fine-tuning the predictions to match your application requirements.
Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. Stay Tuned DBLog has additional capabilities which are not covered by this blog post, such as: Ability to capture table schemas without using locks.
Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. Stay Tuned DBLog has additional capabilities which are not covered by this blog post, such as: Ability to capture table schemas without using locks.
They can also bolster uptime and limit latency issues or potential downtimes. This process thoroughly assesses factors like cost-effectiveness, security measures, control levels, scalability options, customization possibilities, performance standards, and availability expectations.
Here are 8 fallacies of data pipeline The pipeline is reliable Topology is stateless Pipeline is infinitely scalable Processing latency is minimum Everything is observable There is no domino effect Pipeline is cost-effective Data is homogeneous The pipeline is reliable The inconvenient truth is that pipeline is not reliable.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content