This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
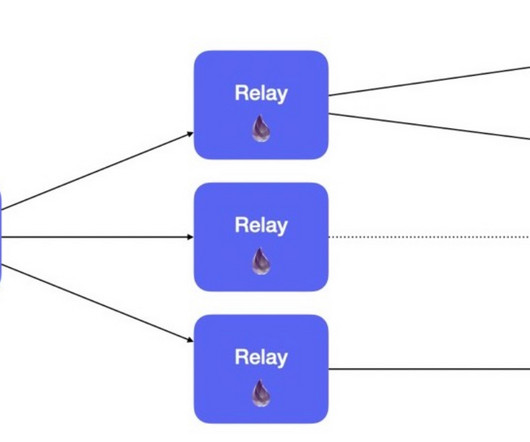
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This decoupling simplifies system architecture and supports scalability in distributed environments. Kafka stores and distributes data through a partitioned log system, which spans multiple brokers to provide fault tolerance and scalability. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency.
Benefits of Caching Improved performance: Caching eliminates the need to retrieve data from the original source every time, resulting in faster response times and reduced latency. Reduced server load: By serving cached content, the load on the server is reduced, allowing it to handle more requests and improving overall scalability.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.
Redis Server: 5.07, x86/64. MongoDB server: 4.4.2, BangDB server: 2.0.0, We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. Again Yugabyte latency is quite high. The latency table for test D is as below.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. It provides a good read on the availability and latency ranges under different production conditions. We will examine these alternatives in the upcoming sections.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Dynatrace Extension: database performance as experienced by the SAP ABAP server. SAP server. It delivers vital enterprise applications to thousands of users.
Too many concurrent server requests can lead to website crashes if youre not equipped to deal with them. For example, you can switch to a scalable cloud-based web host, or compress/optimize images to save bandwidth. For example, you can switch to a scalable cloud-based web host, or compress/optimize images to save bandwidth.
Many organizations today rely on cloud-native applications for their scalability and agility, among other benefits. Despite the name, serverless computing still uses servers. Serverless benefits include the following: Dynamic scalability. Reduced latency. However, not all cloud strategies are the same. Cost-effectiveness.
When the server receives a request for an action (post, like etc.) When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. This will not only reduce the overall latency in displaying the user-feeds to users but will also prevent re-computation of user-feeds.
Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes. Streaming raises the default 6 MB hard limit to a 20 MB soft limit, adding greater scalability and flexibility to their applications. What is a Lambda serverless function?
72 : signals sensed from a distant galaxy using AI; 12M : reddit posts per month; 10 trillion : per day Google generated test inputs with 100s of servers for several months using OSS-Fuzz; 200% : growth in Cloud Native technologies used in production; $13 trillion : potential economic impact of AI by 2030; 1.8 They'll love you even more.
Critical assets are far too valuable to leave on someone else’s servers. Every new origin we need to visit needs a connection opening, and that can be very costly: DNS resolution, TCP handshakes, and TLS negotiation all add up, and the story gets worse the higher the latency of the connection is. Risk: Service Shutdowns. to just 3.6s.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
It's HighScalability time: Have a very scalable Xmas everyone! Tim Bray : How to talk about [Serverless Latency] · To start with, don’t just say “I need 120ms.” ” And in most mainstream applications, you should be able to get there with serverless. If you plan for it.
In that scenario, the system would need to deal with the data propagation latency directly, for example, by use of timeouts or client-originated update tracking mechanisms. We started seeing increased response latencies and leader servers running at dangerously high utilization.
Meeting the requirements of a tier-0 application demands the highest level of reliability and scalability, which Dynatrace enables through extensive self-monitoring and self-healing across the entire application stack down to the infrastructure level. It is more critical to our business than any other revenue-driving application.”
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The third generation, called Reloaded , has been online for about seven years and has proven to be stable and massively scalable.
The 2014 launch of AWS Lambda marked a milestone in how organizations use cloud services to deliver their applications more efficiently, by running functions at the edge of the cloud without the cost and operational overhead of on-premises servers. AWS continues to improve how it handles latency issues. What is AWS Lambda?
It also works well to justify an acquisition of more servers to investors. During our testing using the storage optimized EC2 instances (I3.2xlarge) we noticed that we were able to perform over 200K IOPS of 1K byte items thus meeting our throughput goals with latency rarely exceeding 1 millisecond. They never question this belief.
Determining the root cause of these issues can be difficult when the underlying “hardware” is a virtualization software stack rather than a bare-metal server. This presents a challenge for IT operations teams, specifically in identifying and addressing performance issues or planning how to prevent future issues.
Edge computing involves processing data locally, near the source of data generation, rather than relying on centralized cloud servers. This proximity reduces latency and enables real-time decision-making. Assess factors like network latency, cloud dependency, and data sensitivity.
Cloud-based AI enables organizations to run AI in the cloud without the hassle of managing, provisioning, or housing servers. Containerization enables organizations to package AI applications and dependencies into a single unit, which can be easily deployed on any server with the necessary dependencies. Use containerization.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. This is not an easy task, considering the wide variety of supported devices and the sheer volume of actions our members perform.
For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Monitoring and observability represent a continuum from basic telemetry of single servers to deep insights about complete applications and dependencies.
Scalability is one of the main drivers of the NoSQL movement. Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write scalability. Data Placement.
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Dynatrace Extension: database performance as experienced by the SAP ABAP server. SAP server. Dynatrace news. Dynatrace Extension: NetScaler performance.
Achieving 100 Gbps intrusion prevention on a single server , Zhao et al., Improving the efficiency with which we can coordinate work across a collection of units (see the Universal Scalability Law ). Today’s paper choice is a wonderful example of pushing the state of the art on a single server. OSDI’20.
Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). connectivity, access, user count, latency) of geographic regions.
The action corresponds to the button on the page and the withFields specify which fields the server expects to have sent back when the button is clicked. Lower latency as a result of fewer service calls, which means fewer errors for our visitors. Step 3 & 4?—?Determine The world is constantly changing.
The breadth of fully-featured services, the pay-as-you-go scalability, and the agility of cloud platforms enable organizations to expand their modern approaches to building and managing digital services in a way they can’t with on-premises apps and infrastructure. Increased scalability. Reduced cost.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Think about items such as general system metrics (for example, CPU utilization, free memory, number of services), the connectivity status, details of our web server, or even more granular in-application tasks like database queries. Let’s click “Apache Web Server apache” now.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. When a server experiences an outage, the system promptly triggers an alert and initiates actions like restarting a server or redirecting traffic to a redundant server.
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
Scalability : Message queues can handle multiple requests and messages simultaneously, making it easier to scale an application to meet increasing demands. This scalability is essential for applications that experience fluctuating workloads. This reliability is crucial for maintaining data integrity and consistency across the system.
Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. A database could start executing a storage management process that consumes database server resources. Observability is made up of three key pillars: metrics, logs, and traces.
Lamborghini, the world-famous manufacturer of elite, luxury sports cars based in Italy, has been using AWS to reduce the cost of their infrastructure by 50 percent, while also achieving better performance and scalability. The company decided it wanted the scalability, flexibility, and cost benefits of working in the cloud.
To meet user-defined goals for performance (request latency) and cost, the monitoring service tracks and adjusts resources to workload changes. Each storage server collects statistics about the requests it serves, the data it stores, etc. This gives users a single, uniform API regardless of where the data is stored.
However, it is limited by the available free memory amount, and all data is lost when the server stops. In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. In-memory Storage Engine This storage engine works completely in RAM, providing the fastest possible access to data.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. can enhance Redis by handling management tasks, backups, and scalability, facilitating global reach and easy cloud integration for global businesses.
This article delves into the specifics of how AI optimizes cloud efficiency, ensures scalability, and reinforces security, providing a glimpse at its transformative role without giving away extensive details. Exploring artificial intelligence in cloud computing reveals a game-changing synergy.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content