This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. This extra network overhead will easily result in increased latency compared to a single-node architecture where data access is straightforward.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency.
Scalability and low latency are crucial for any application that relies on real-time data. In this post, we'll discuss how you can use YugabyteDB and its read replica nodes to improve the read latency for users across the globe. One way to achieve this is by storing data closer to the users.
Speed and scalability are significant issues today, at least in the application landscape. We compare throughput, operations per second, and latency under different loads, namely the P90 and P99 percentiles. We compare throughput, operations per second, and latency under different loads, namely the P90 and P99 percentiles.
The goal is to help developers, technical managers, and business owners understand the importance of API performance optimization and how they can improve the speed, scalability, and reliability of their APIs. API performance optimization is the process of improving the speed, scalability, and reliability of APIs.
This decoupling simplifies system architecture and supports scalability in distributed environments. Kafka stores and distributes data through a partitioned log system, which spans multiple brokers to provide fault tolerance and scalability. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Benefits of Caching Improved performance: Caching eliminates the need to retrieve data from the original source every time, resulting in faster response times and reduced latency. Reduced server load: By serving cached content, the load on the server is reduced, allowing it to handle more requests and improving overall scalability.
In this article, I will walk through a comprehensive end-to-end architecture for efficient multimodal data processing while striking a balance in scalability, latency, and accuracy by leveraging GPU-accelerated pipelines, advanced neural networks , and hybrid storage platforms.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? The complexity of these operational demands underscored the urgent need for a scalable solution.
Solves compute, latency, and interop. Number Stuff: Don't miss all that the Internet has to say on Scalability, click below and become eventually. consistent with all scalability knowledge (which means this post has many more items to read so please keep on reading). Cars become mostly remote controlled pleasure palaces.
With the rise of microservices architecture , there has been a rapid acceleration in the modernization of legacy platforms, leveraging cloud infrastructure to deliver highly scalable, low-latency, and more responsive services. Why Use Spring WebFlux?
Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. Keeping queues short maintains a responsive and efficient RabbitMQ setup.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.
It was made possible by using a low latency of 0.1 seconds, the lower the latency, the more responsive the robot. Don't miss all that the Internet has to say on Scalability, click below and become eventually consistent with all scalability knowledge (which means this post has many more items to read so please keep on reading).
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system.
Delay is Not an Option: Low Latency Routing in Space , Murat ). Don't miss all that the Internet has to say on Scalability, click below and become eventually consistent with all scalability knowledge (which means this post has many more items to read so please keep on reading). Here's some fancy FCC reverse engineering magic.
Quotable Stuff: @mjpt777 : APIs to IO need to be asynchronous and support batching otherwise the latency of calls dominate throughput and latency profile under burst conditions. . $84.4 : average yearly Facebook ad revenue per user in North America. Also Thurs are now much more productive. We work too much.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
It's HighScalability time: This is your 1500ms latency in real life situations - pic.twitter.com/guot8khIPX. Don't miss all that the Internet has to say on Scalability, click below and become eventually consistent with all scalability knowledge (which means this post has many more items to read so please keep on reading).
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. FUN FACT : In this talk , Dikang Gu, a software engineer at Instagram core infra team has mentioned about how they use Cassandra to serve critical usecases, high scalability requirements, and some pain points.
Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes. Streaming raises the default 6 MB hard limit to a 20 MB soft limit, adding greater scalability and flexibility to their applications. What is a Lambda serverless function?
SCM slots between DRAM and flash in terms of latency, cost, and density. Don't miss all that the Internet has to say on Scalability, click below and become eventually consistent with all scalability knowledge (which means this post has many more items to read so please keep on reading). So many more quotes.
TServerless : We sat with a solution architect, apparently they are aware of the latency issue and suggested to ditch api gw and build our own solution. For those who sought to control nature through programmable machines, it responds by allowing us to build machines whose nature is that they can no longer be controlled by programs.
Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively.
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Citrix platform performance—optimize your Citrix landscape with insights into user load and screen latency per server. Citrix VDA. SAP server. Citrix VDA. Citrix StoreFront.
It's HighScalability time: Have a very scalable Xmas everyone! Tim Bray : How to talk about [Serverless Latency] · To start with, don’t just say “I need 120ms.” See you in the New Year. Do you like this sort of Stuff? Please support me on Patreon. I'd really appreciate it. Explain the Cloud Like I'm 10.
µs of replication latency on lossy Ethernet, which is faster than or comparable to specialized replication systems that use programmable switches, FPGAs, or RDMA.". We achieve 5.5 matthewstoller : I just looked at Netflix’s 10K. At some point, the e-mail I send over WiFi will hit a wire, of course". Yep, there are more quotes.
This approach supports innovation, ambitious SLOs, DevOps scalability, and competitiveness. These metrics are latency, traffic, errors, and saturation, all of which must be key considerations when curating user experience. In this example, unlike latency, the remaining three signals did not receive a “pass.”
Allegro experimented with different performance optimization options to improve Apache Kafka producer tail latency and eventually switched all its clusters to the XFS filesystem. The company used Kafka protocol sniffing, JVM profiling, and eBPF, which proved instrumental in identifying and eliminating performance bottlenecks.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. It provides a good read on the availability and latency ranges under different production conditions.
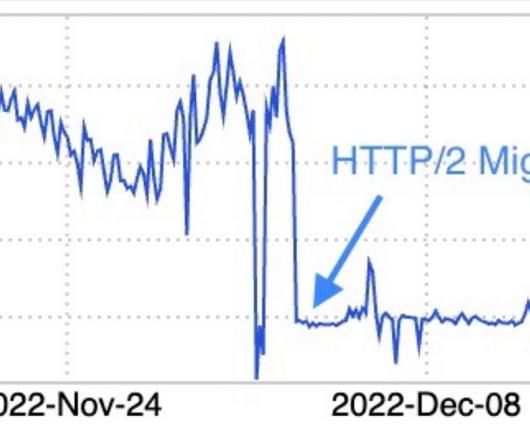
LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. By Rafal Gancarz
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
In that scenario, the system would need to deal with the data propagation latency directly, for example, by use of timeouts or client-originated update tracking mechanisms. We started seeing increased response latencies and leader servers running at dangerously high utilization.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The third generation, called Reloaded , has been online for about seven years and has proven to be stable and massively scalable.
Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance. With the Dynatrace Data Explorer, you can easily analyze metrics, such as client read/write latency by Cassandra nodes and disk space usage by keyspaces.
Many organizations today rely on cloud-native applications for their scalability and agility, among other benefits. Serverless benefits include the following: Dynamic scalability. Reduced latency. By using cloud providers with multiple server sites, organizations can reduce function latency for end users.
A typical example of modern "microservices-inspired" Java application would function along these lines: Netflix : We observed during experimentation that RAM random read latencies were rarely higher than 1 microsecond whereas typical SSD random read speeds are between 100–500 microseconds. There are a few more quotes.
Every new origin we need to visit needs a connection opening, and that can be very costly: DNS resolution, TCP handshakes, and TLS negotiation all add up, and the story gets worse the higher the latency of the connection is. On a slower, higher-latency connection, the story is much, mush worse. All completely avoidable. to just 3.6s.
This proximity to data generation reduces latency, conserves bandwidth and enables real-time decision-making. However, managing distributed workloads across various edge nodes in a scalable and efficient manner is a complex challenge.
Scalability is one of the main drivers of the NoSQL movement. Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. Read/Write latency. Read/Write scalability. Data Placement.
For example, you can switch to a scalable cloud-based web host, or compress/optimize images to save bandwidth. Choose A Scalable Web Host The most convenient way to design a high-traffic website without worrying about website crashes is to upgrade your web hosting solution.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content