This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing. Go and sign up.
While we understand it’s virtually impossible to achieve a linear increase in throughput as the number of vCPUs grow, a near-linear increase is attainable. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.” This was our starting point for troubleshooting.
This extends Dynatrace visibility into Citrix user experience and Citrix platform performance. Platform performance —get visibility into the performance of the Citrix platform to optimize application delivery. Dynatrace Extension: SAP ABAP platform performance. Dynatrace Extension: NetScaler performance.
Microsoft Hyper-V is a virtualization platform that manages virtual machines (VMs) on Windows-based systems. Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking. What is Microsoft Hyper-V?
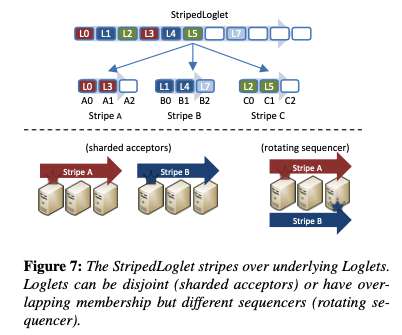
Virtual consensus in Delos , Balakrishnan et al. While ultimately this new system should be able to take advantage of the latest advances in consensus for improved performance, that’s not realistic given a 6-9 month in-production target. We propose the novel abstraction of a virtual shared log (or VirtualLog).
Sure, cloud infrastructure requires comprehensive performance visibility, as Dynatrace provides , but the services that leverage cloud infrastructures also require close attention. Well-defined APIs are required for managing such microservices and tracking changes in their performance. High latency or lack of responses.
Service level objectives (SLOs) provide a powerful framework for measuring and maintaining software performance, reliability, and user satisfaction. SLOs are a valuable tool for organizations to ensure the health and performance of their applications. But how do you get started, and what are some service level objective examples?
Platform performance —get visibility into the performance of the Citrix platform to optimize application delivery. Dynatrace Extension: SAP ABAP platform performance. Dynatrace Extension: database performance as experienced by the SAP ABAP server. Synthetic monitoring: Citrix login availability and performance.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
The ProRes codec family provides great editing performance and image quality. Uploading and downloading data always come with a penalty, namely latency. Virtual Assembly Figure 3 describes how a virtual assembly of the encoded chunks replaces the physical assembly used in our previous architecture.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. VMware commercialized the idea of virtual machines, and cloud providers embraced the same concept with services like Amazon EC2, Google Compute, and Azure virtual machines.
Nutanix overview dashboard The extension automatically gathers real-time performance data from your Nutanix clusters to monitor resource usage, cluster health, and more, all in one place. Dynatrace, in tandem with the Nutanix extension, simplifies performance monitoring and makes issue identification and resolution more efficient.
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. In the screenshot below, a chaos engineering scenario introduced latency and resource stress on the “easytrade” demo application.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
Dynatrace is a launch partner in support of AWS Lambda Response Streaming , a new capability enabling customers to improve the efficiency and performance of their Lambda functions. Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes.
To that end, it’s important that we prevent significant performance regressions from reaching the production app. Any performance regression that makes it into a product release will degrade user experience, so the challenge is to detect and fix such regressions before they ship. What do we mean by Performance?
In addition to providing visibility for core Azure services like virtual machines, load balancers, databases, and application services, we’re happy to announce support for the following 10 new Azure services, with many more to come soon: Virtual Machines (classic ones). Azure Virtual Network Gateways. Azure Batch.
As a discipline, SRE focuses on improving software system reliability across key categories including availability, performance, latency, efficiency, capacity, and incident response. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
Real user monitoring (RUM) is a performance monitoring process that collects detailed data about a user’s interaction with an application. IT teams can deploy synthetic agents in different geographical regions, so you can detect variations in application performance based on geolocation. What is real user monitoring?
As a discipline, SRE focuses on improving software system reliability across key categories including availability, performance, latency, efficiency, capacity, and incident response. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
While this is a good way to get a rough estimate, your monthly cloud costs will indeed vary based on the amount of backups performed and your data transfer activity. A vast majority of the features are the same, outside of these advanced features available through the BYOC model: Virtual Private Clouds / Virtual Networks.
Service level objectives (SLOs) provide a powerful framework for measuring and maintaining software performance, reliability, and user satisfaction. Teams can build on these SLO examples to improve application performance and reliability. In this post, I’ll lay out five SLO examples that every DevOps and SRE team should consider.
Understanding why a user is experiencing transactional or performance issues enables organizations to achieve greater observability that goes beyond metrics, traces and logs. PC, smartphone, server) or virtual (virtual machines, cloud gateways). Endpoint monitoring (EM). Endpoints can be physical (i.e.,
The first was voice control, where you can play a title or search using your virtual assistant with a voice command like “Show me Stranger Things on Netflix.” (See Finally, the device receives the message, and the action, such as “Show me Stranger Things on Netflix”, is performed. Sample system diagram for an Alexa voice command.
What’s most impressive is that you’re not compromising performance for cost. We ran performance tests for MongoDB on DigitalOcean vs. AWS vs. Azure and found that DigitalOcean performance was in line with, if not better, on both high throughput and low latency in the deployment. Monitoring Performance.
It's an exciting time for developments in computer performance, not just for the BPF technology (which I often [write about]) but also for processors with 3D stacking and cloud vendor CPUs (e.g., This was a chance to talk about other things I've been working on, such as the present and future of hardware performance.
With this approach, you can add any relevant metric(s) from your process to Dynatrace, and then chart it, alert on it, or correlate it with your process’ performance. With insights from Dynatrace into network latency and utilization of your cloud resources, you can design your scaling mechanisms and save on costly CPU hours.
In addition, compute and storage are increasingly being separated causing larger latencies for queries. Alluxio is leveraged as compute-side virtual storage to improve performance. But to get the best performance, like any technology stack, you need to follow the best practices. A Note on Data Locality.
These sit between the database and the clients, sometimes on a seperate server (physical or virtual) and sometimes on the same box, and create a pool that clients can connect to. There is no centralized control – you cannot use measures like client-specific access limits. A middleware becomes a single point of failure.
At USENIX SREcon22 APAC I gave the opening keynote on the future of computer performance, rounding up the latest developments and making predictions of where I see things heading. This talk originated from my updates to [Systems Performance 2nd Edition], and this was the first time I've given this talk in person! Or even on a plane.
Relationships are a fundamental aspect of both the physical and virtual worlds. Modern applications need to quickly navigate connections in the physical world of people, cities, and public transit stations as well as the virtual world of search terms, social posts, and genetic code, for example. The importance of relationships.
Amazon DynamoDB is a fully managed NoSQL database service that provides fast performance at any scale. Amazon DynamoDB offers low, predictable latencies at any scale. It is very gratifying to see all of our learning and experience become available to our customers in the form of an easy-to-use managed service.
It keeps application processing closer to the data to maintain higher bandwidth and lower latencies, adheres to compliance regulations that don’t yet approve cloud managed services, and allows data center capital investments to be fully amortized before moving to the cloud. Customer Data Center – Hosts and Virtual Machines.
Despite advances in browser tooling , automated evaluation , lab tools , guidance , and runtimes , however, teams struggle to deliver even decent performance with today's popular frameworks. What is Performance? It may seem a silly question, but what is performance, exactly?
Today, we added two important choices for customers running high performance apps in the cloud: support for Redis in Amazon ElastiCache and a new high memory database instance (db.cr1.8xlarge) for Amazon RDS. Today, we are further expanding the choices available for designing and developing highly scalable and high performance apps.
With Dynatrace, we follow a combination of agent and agent-less approach where the “secret sauce” lies in our Dynatrace OneAgent (watch my Performance Clinic YouTube tutorial with our Chief Software Architect Helmut Spiegl ). What’s the current performance of key database queries and stored procedures? Which Database to migrate?
We were pushing the limits of what was a leading commercial database at the time and were unable to sustain the availability, scalability and performance needs that our growing Amazon business demanded. Performant – The service would need to be able to maintain consistent performance in the face of diverse customer workloads.
Looking back over the past 10 years, there are hundreds of lessons that we’ve learned about building and operating services that need to be secure, reliable, scalable, with predictable performance at the lowest possible cost. This lowered latency more than 2x and delivered more than 10x improvement in latency variability on the network.
On April 24, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations. Focus on real-world performance and continuous improvement.
These strange questions came to the fore back in 2014 when Netflix was switching services from CentOS Linux to Ubuntu, and I helped debug several weird performance issues including one I'll describe here. A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. How would you _time_ time?
There is a section in our Documentation ( Introduction to Serverless PostgreSQL ) and a short overview of the primary components: Page Server The storage server with the primary goal of storing all data pages and WAL records Safe Keeper A component to store WAL records in memory (to reduce latency).
This allowed for sequential access and indexed access, but random writes could cause performance issues. Choosing the appropriate storage engine can have a significant impact on application performance. Choosing the right storage engine is crucial for application performance as each engine has its own strengths and weaknesses.
Simply put, it’s the set of computational tasks that cloud systems perform, such as hosting databases, enabling collaboration tools, or running compute-intensive algorithms. This applies to both virtual machines and container-based deployments. What is workload in cloud computing?
Netflix Drive aims to solve this problem of exposing different namespaces and attaching appropriate access control to help build a scalable, performant, globally distributed platform for storing and retrieving pertinent assets. The data store should expose APIs that allow Netflix Drive to perform I/O operations.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content